Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Currently, Easy Dataset supports three startup methods: client, NPM, and Docker. All methods process data completely locally, so you don't need to worry about data privacy issues.
To solve various local deployment environment issues, you can directly use the client to start, supporting the following platforms:
You can directly go to https://github.com/ConardLi/easy-dataset/releases to download the installation package suitable for your system:
This project is built on Next, so as long as you have a Node environment locally, you can start directly through NPM. This is suitable for developers who need to debug the project:
Clone the repository:
git clone https://github.com/ConardLi/easy-dataset.git
cd easy-datasetInstall dependencies:
npm installStart the server:
npm run build
npm run startNote: When using NPM startup, when the system releases a new version, you need to re-execute git pull to fetch the latest code, and then re-execute the three steps of npm install, npm run build, and npm run start.
If you want to build the image yourself for deployment in cloud services or intranet environments, you can use the Dockerfile in the project root directory:
Clone the repository:
git clone https://github.com/ConardLi/easy-dataset.git
cd easy-datasetBuild the Docker image:
docker build -t easy-dataset .Run the container:
docker run -d -p 1717:1717 -v {YOUR_LOCAL_DB_PATH}:/app/local-db --name easy-dataset easy-datasetNote: Please replace
{YOUR_LOCAL_DB_PATH}with the actual path where you want to store the local database.
Currently, the platform has built-in some model providers by default. You only need to fill in the corresponding key for the model provider:
ollama
Ollama
http://127.0.0.1:11434/api
openai
OpenAI
https://api.openai.com/v1/
siliconcloud
Silicon Flow
https://api.ap.siliconflow.com/v1/
deepseek
DeepSeek
https://api.deepseek.com/v1/
302ai
302.AI
https://api.302.ai/v1/
zhipu
Zhipu AI
https://open.bigmodel.cn/api/paas/v4/
Doubao
Volcano Engine
https://ark.cn-beijing.volces.com/api/v3/
groq
Groq
https://api.groq.com/openai
grok
Grok
https://api.x.ai
openRouter
OpenRouter
https://openrouter.ai/api/v1/
alibailian
Alibaba Cloud Bailian
https://dashscope.aliyuncs.com/compatible-mode/v1
Note: Model providers not in the above list are also supported for configuration. Information such as model provider, API interface address, API Key, and model name all support custom input. As long as the API conforms to the OPEN AI format, the platform can be compatible with it.
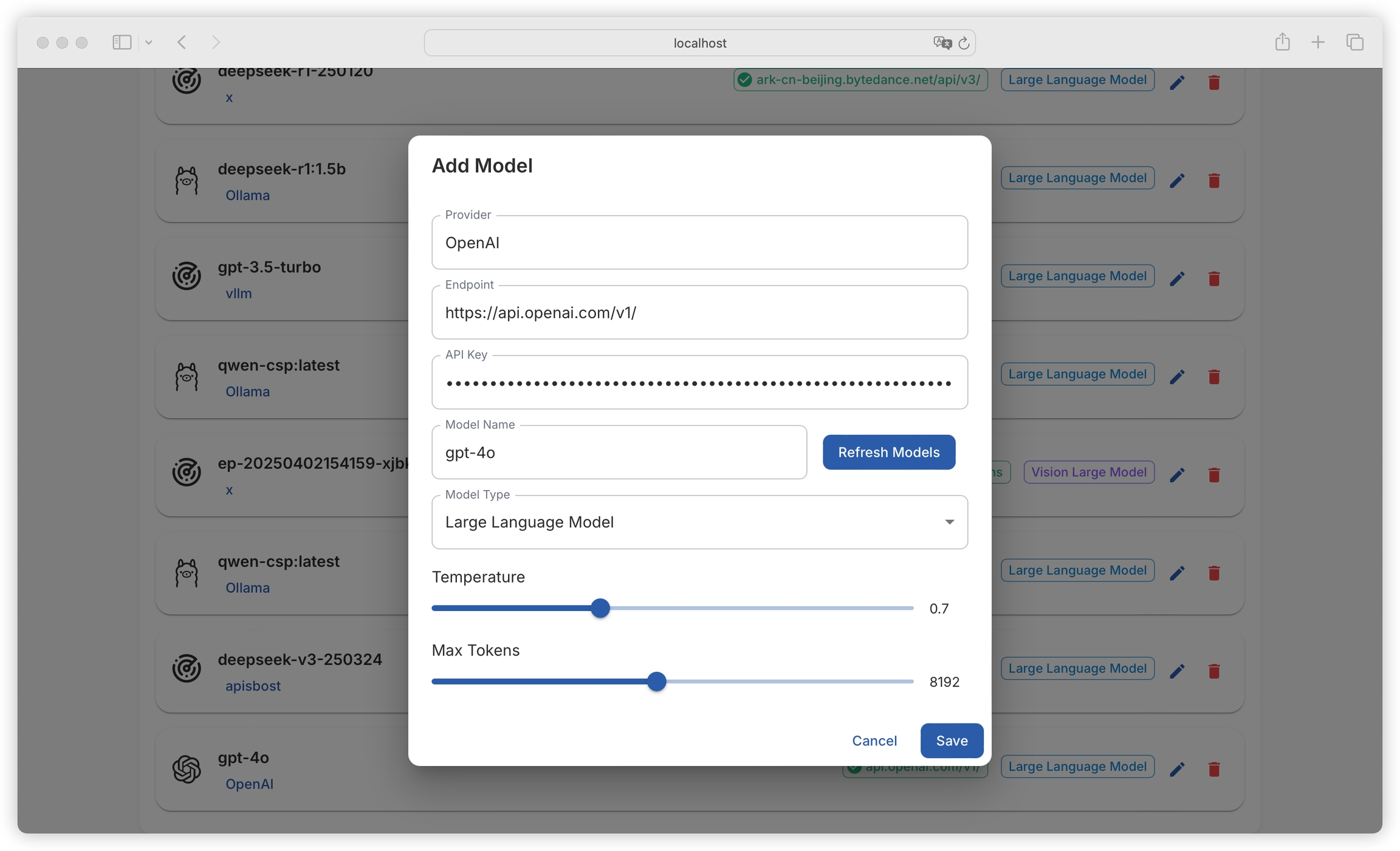
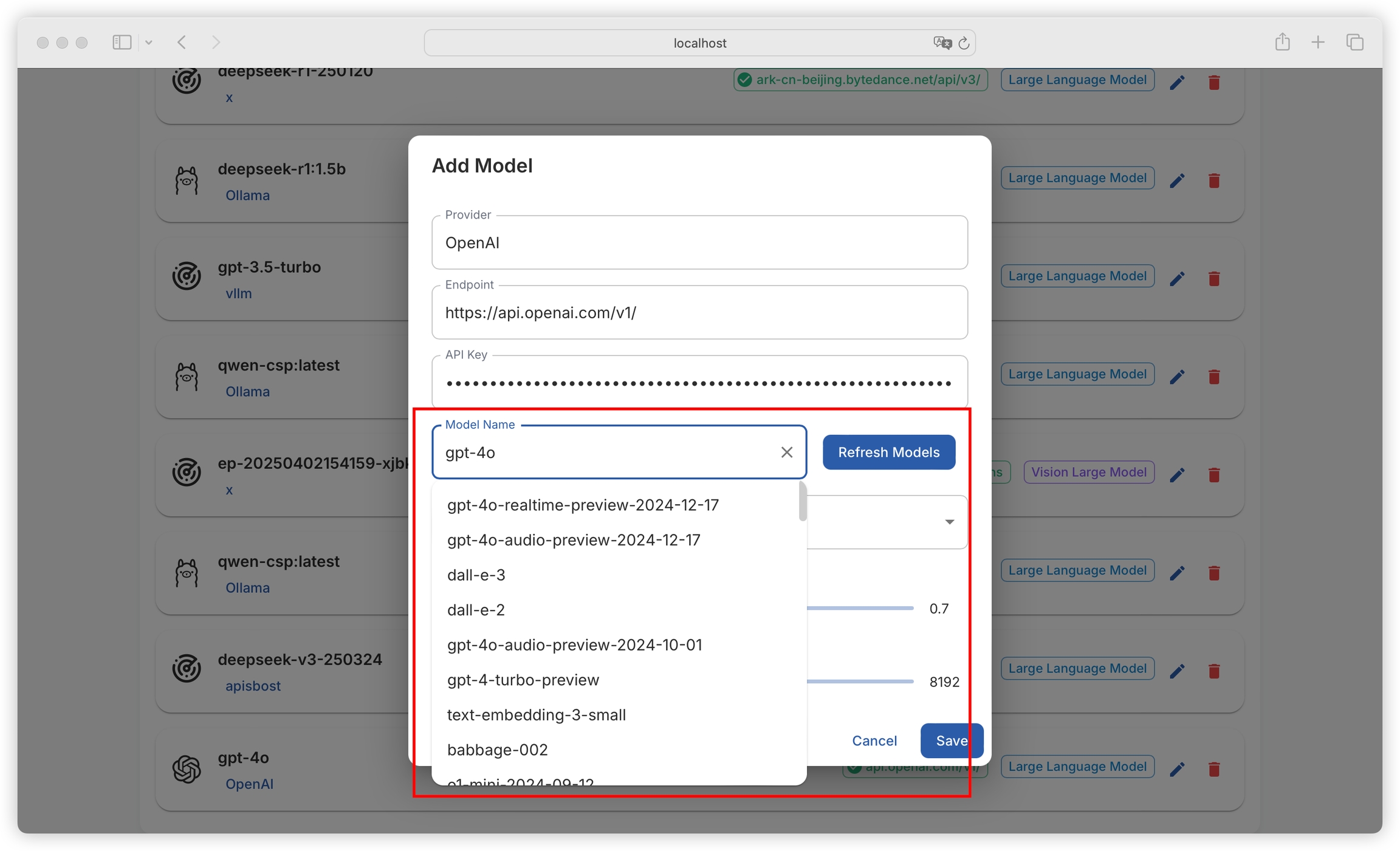
Click Refresh Model List to view all models provided by the provider (you can also manually enter the model name here):
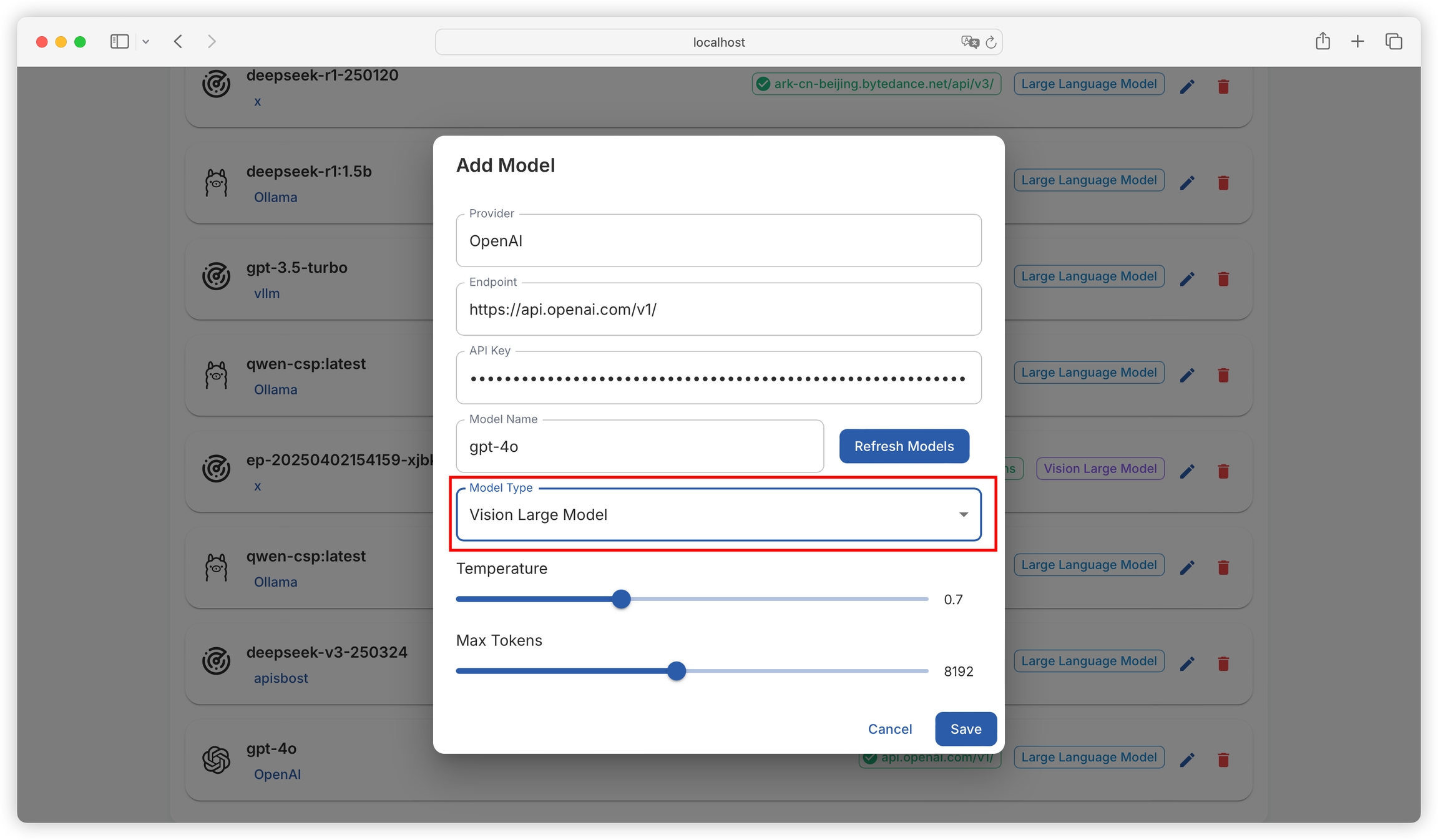
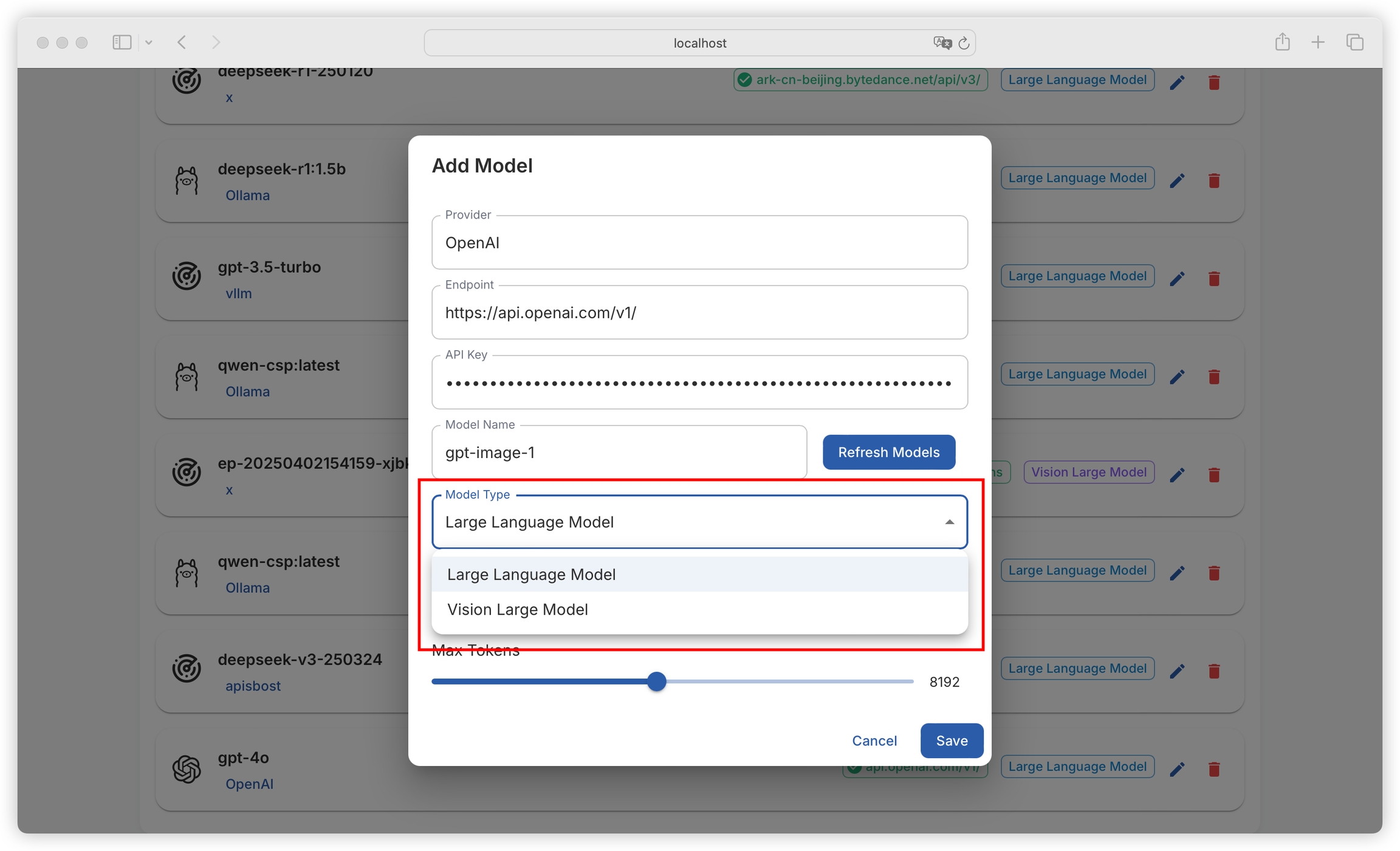
Supports configuration of language models (for text generation tasks) and vision models (for visual analysis tasks):
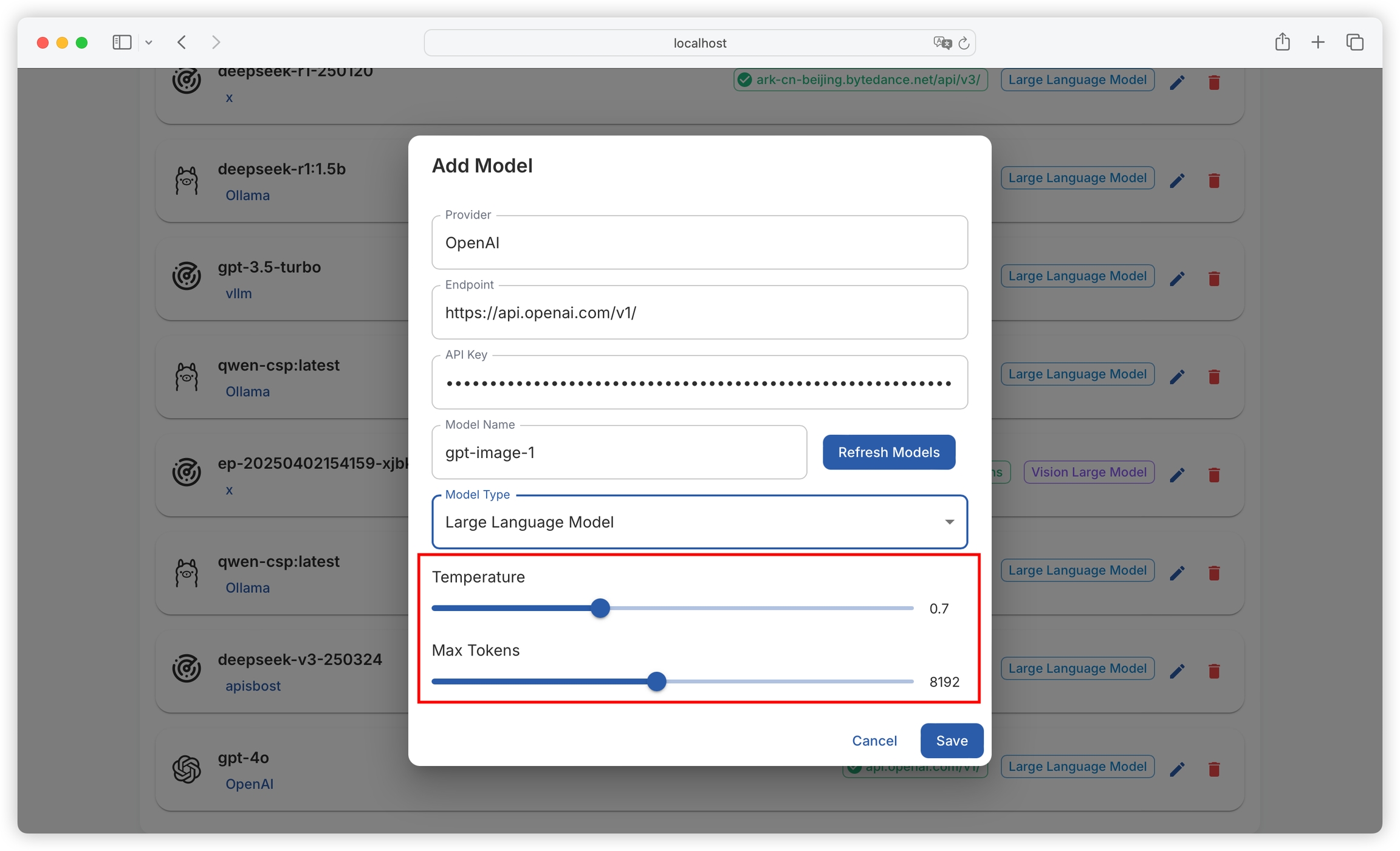
It also supports configuring the model's temperature and maximum output tokens:
Temperature: Controls the randomness of the generated text. Higher temperature results in more random and diverse outputs, while lower temperature leads to more stable and conservative outputs.
Max Token: Limits the length of text generated by the model, measured in tokens, to prevent excessively long outputs.
Supports Ollama, which can automatically fetch the list of locally deployed models:
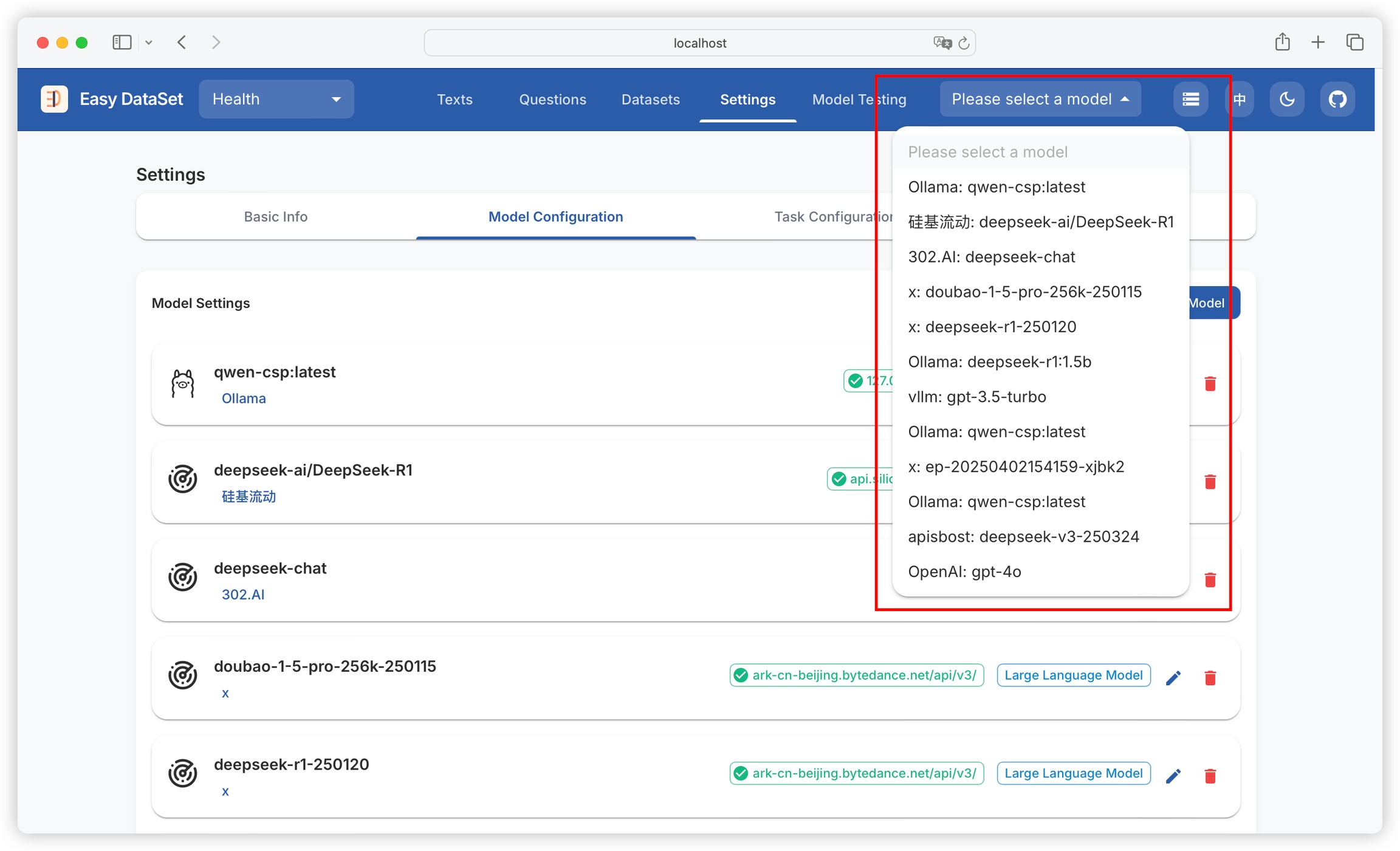
Supports configuring multiple models, which can be switched through the model dropdown box in the upper right corner:
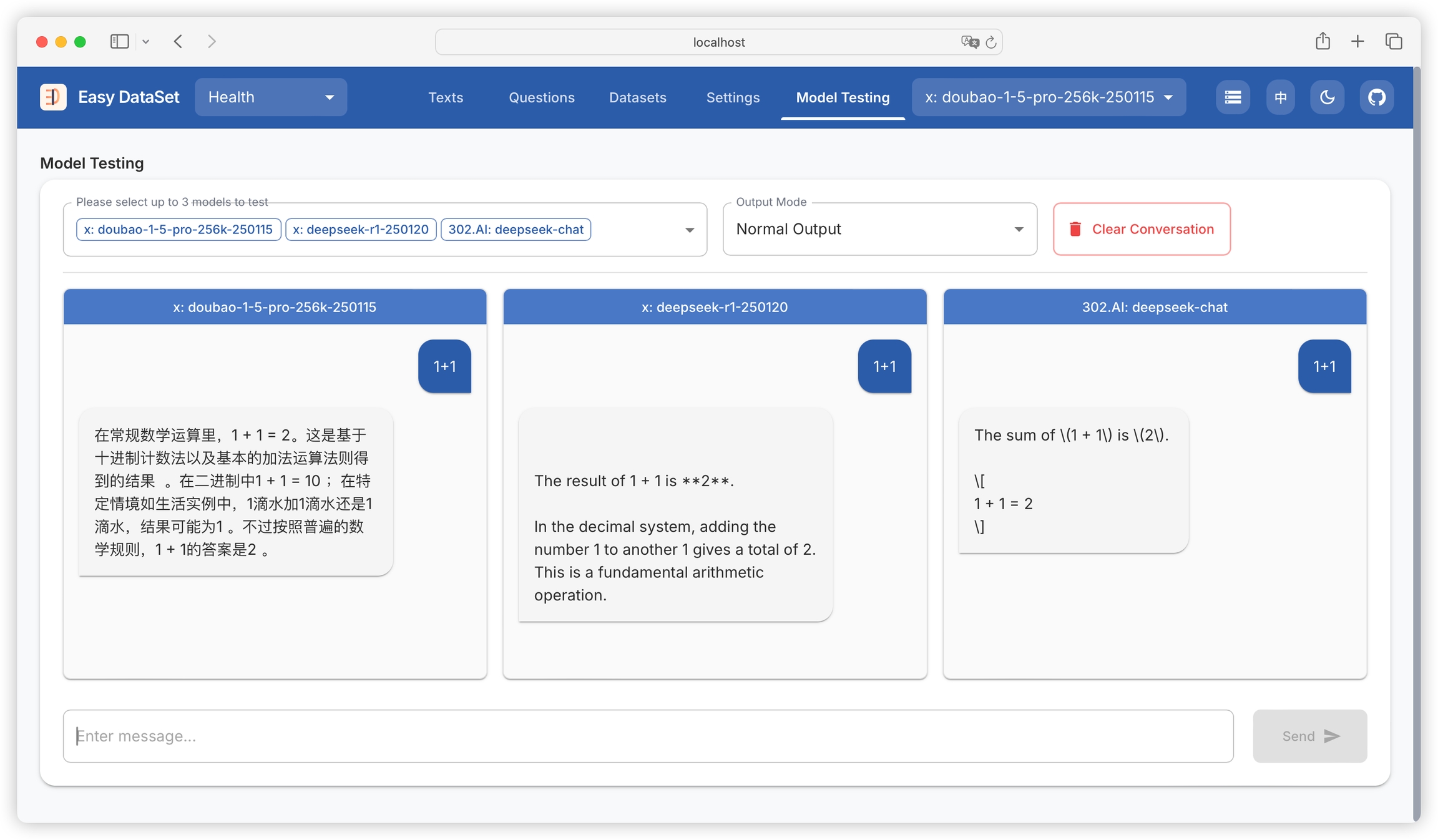
Supports selecting multiple models simultaneously (up to three) to compare model response effects, making it convenient to test which model performs better in different task scenarios:
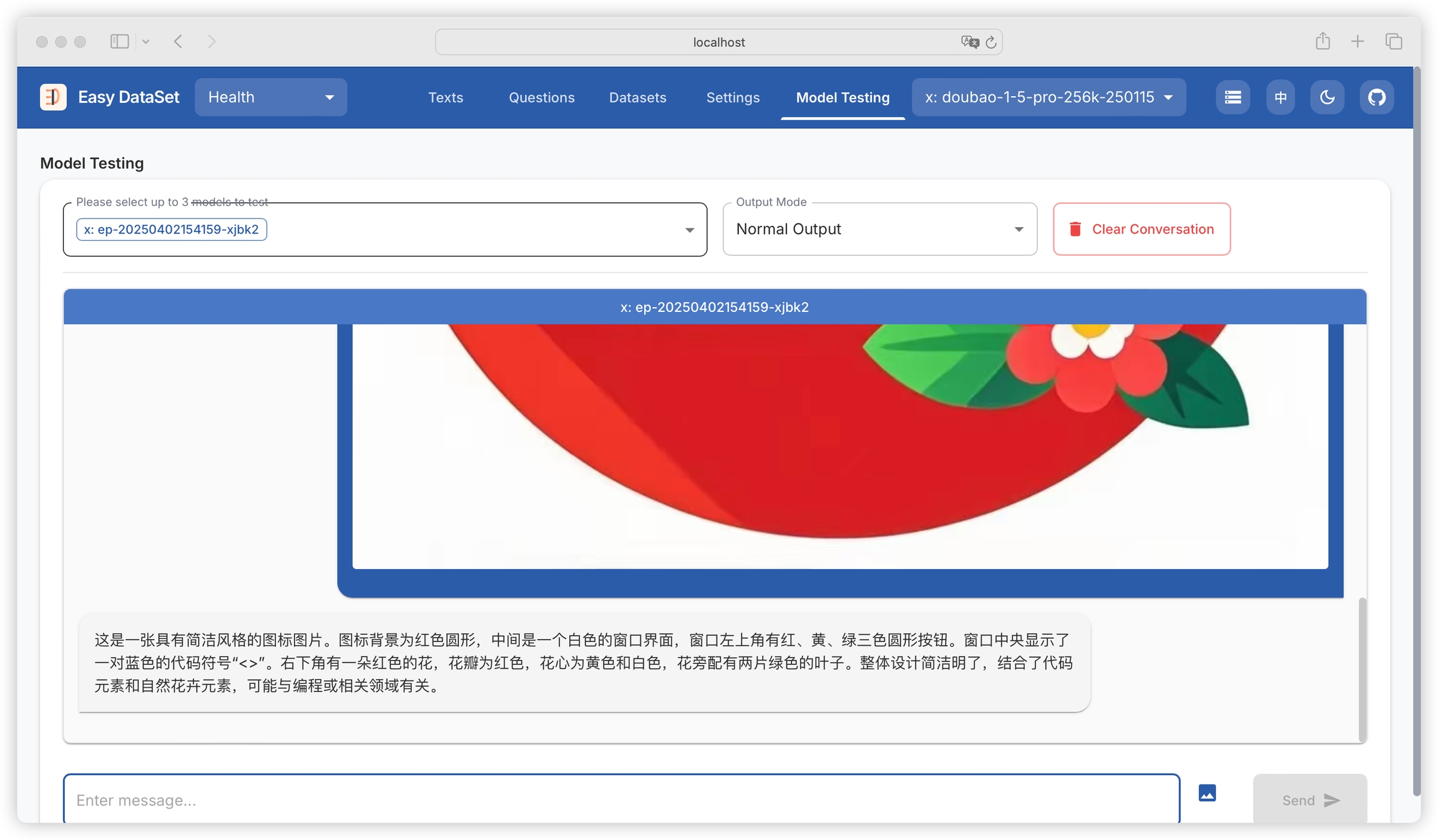
Supports testing vision models:
Currently, various industries are actively exploring fine-tuning large models for their specific sectors. The fine-tuning process itself is not difficult, and there are many mature tools available in the market. The challenging part is the initial dataset preparation stage. The quality of the dataset directly determines the effectiveness of the model after fine-tuning. Building high-quality domain datasets consistently faces multiple challenges, and people generally encounter the following problems when building datasets:
Complete lack of knowledge on how to proceed, currently doing everything manually and wanting to improve efficiency
Directly giving documents to AI, but AI performs poorly when generating Q&A pairs for large files
AI has context limitations, cannot generate too many questions at once, and generates duplicate questions when done in batches
Already have compiled datasets but want a place to manage them in bulk for annotation and validation
Have specific domain requirements for datasets but don't know how to build domain tags
Want to fine-tune reasoning models but don't know how to construct Chain-of-Thought (COT) in the fine-tuning dataset
Want to convert from one dataset format to another but don't know how to do the conversion
To solve these problems, Easy DataSet was created, providing a systematic solution that implements a complete closed-loop from literature parsing to dataset construction, annotation, export, and evaluation. Below are the problems the tool aims to solve:
Support multiple literature processing methods to convert various formats of literature into formats that models can understand
Achieve AI-assisted dataset generation without losing accuracy
Solve truncation problems caused by model context limitations
Construct datasets in bulk, generate COT, and avoid generating duplicate datasets
Build domain tags and organize datasets according to domain trees
Effectively manage datasets for quality verification and other operations
Easily convert generated datasets into different formats, such as Alpaca and ShareGPT formats
Effectively evaluate models based on datasets
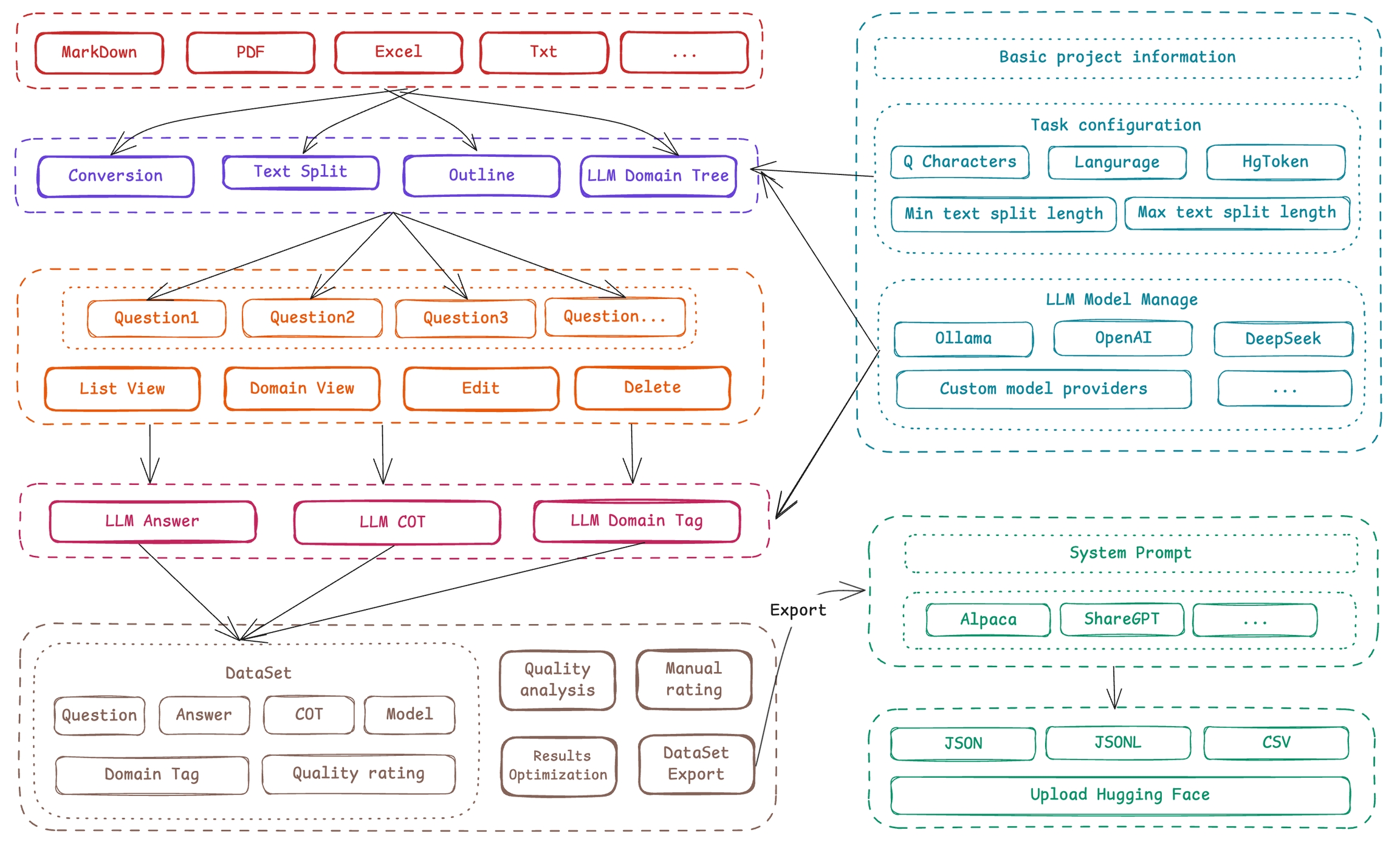
Easy DataSet uses a project-based approach as its core unit, covering the entire chain from "literature processing-question generation-answer construction-tag management-data export":
Model Configuration Center: Supports OpenAI format APIs (such as OpenAI, DeepSeek, various third-party model providers) and local models (Ollama), with built-in model testing Playground, supporting multi-model comparison.
Intelligent Literature Processing: Uses the "Section-Aware Recursive Chunking" algorithm, implements semantic-level segmentation based on Markdown structure, ensures complete content in each chunk (configurable minimum/maximum length), accompanied by outline extraction and summary generation.
Domain Tag System: AI automatically generates two-level domain trees (such as "Sports-Football"), supports manual correction, binds precise tags to each Q&A pair, reducing duplication rate.
Intelligent Data Generation: Extracts questions from domain information, intelligently constructs data based on questions + domain information, and supports multi-dimensional data annotation and multi-format data export.
Batch Question Generation: Based on text block semantics, dynamically generates questions according to character density (configurable), supports batch creation and interruption recovery.
Intelligent Answer Construction: Generates answers associated with original text blocks, supports reasoning models (such as DeepSeek-R1) to generate answers with Chain of Thought (COT).
Quality Verification Mechanism: Provides batch deletion, manual editing, and AI optimization (automatic polishing with input instructions) of questions/answers to ensure data usability.
Multi-format Export: Supports Alpaca, ShareGPT standard formats, custom field mapping, including domain tags and COT information.
Dataset Marketplace: Aggregates multiple platform data sources such as HuggingFace and Kaggle, supports one-click keyword search, solving the initial problem of "where to get data."
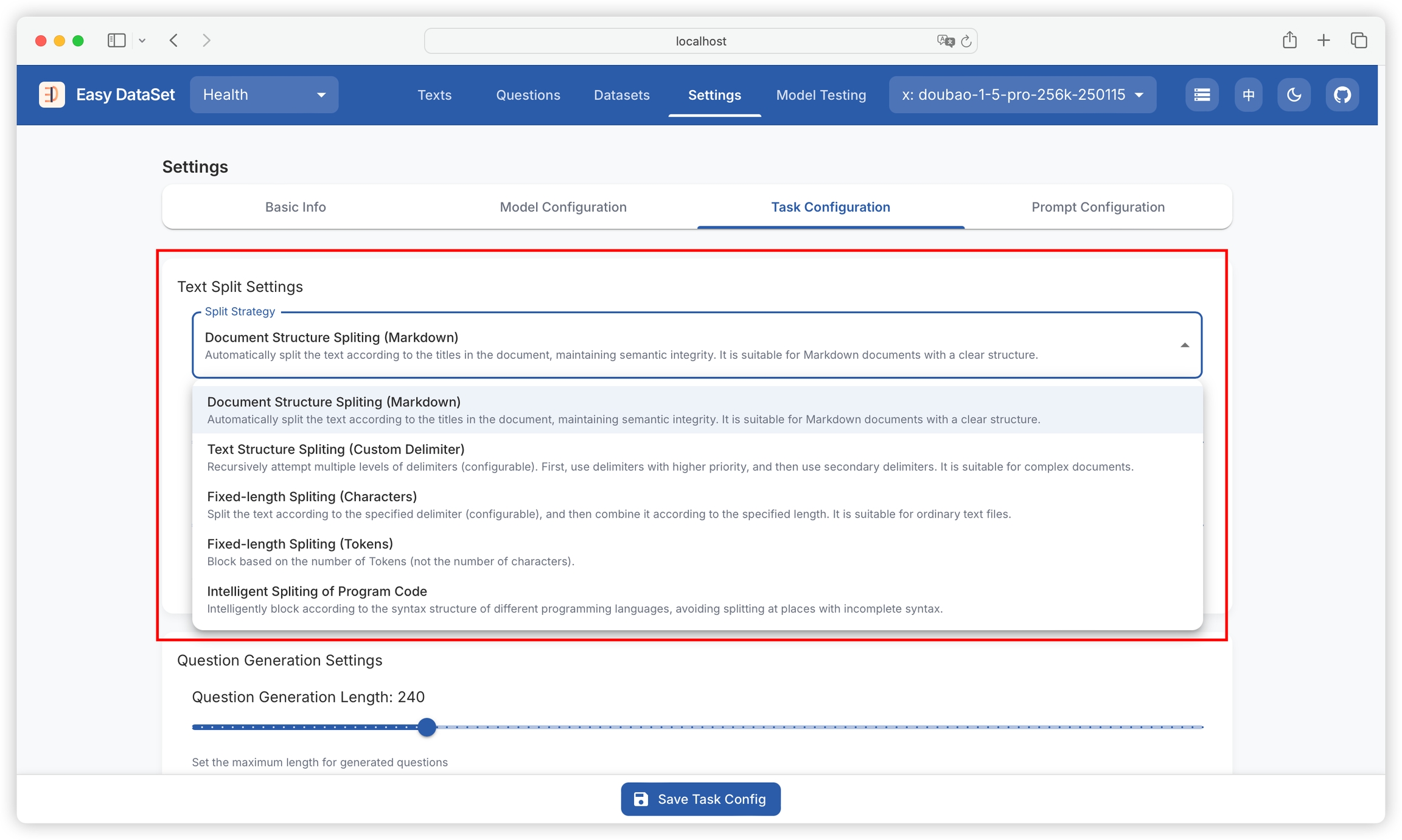
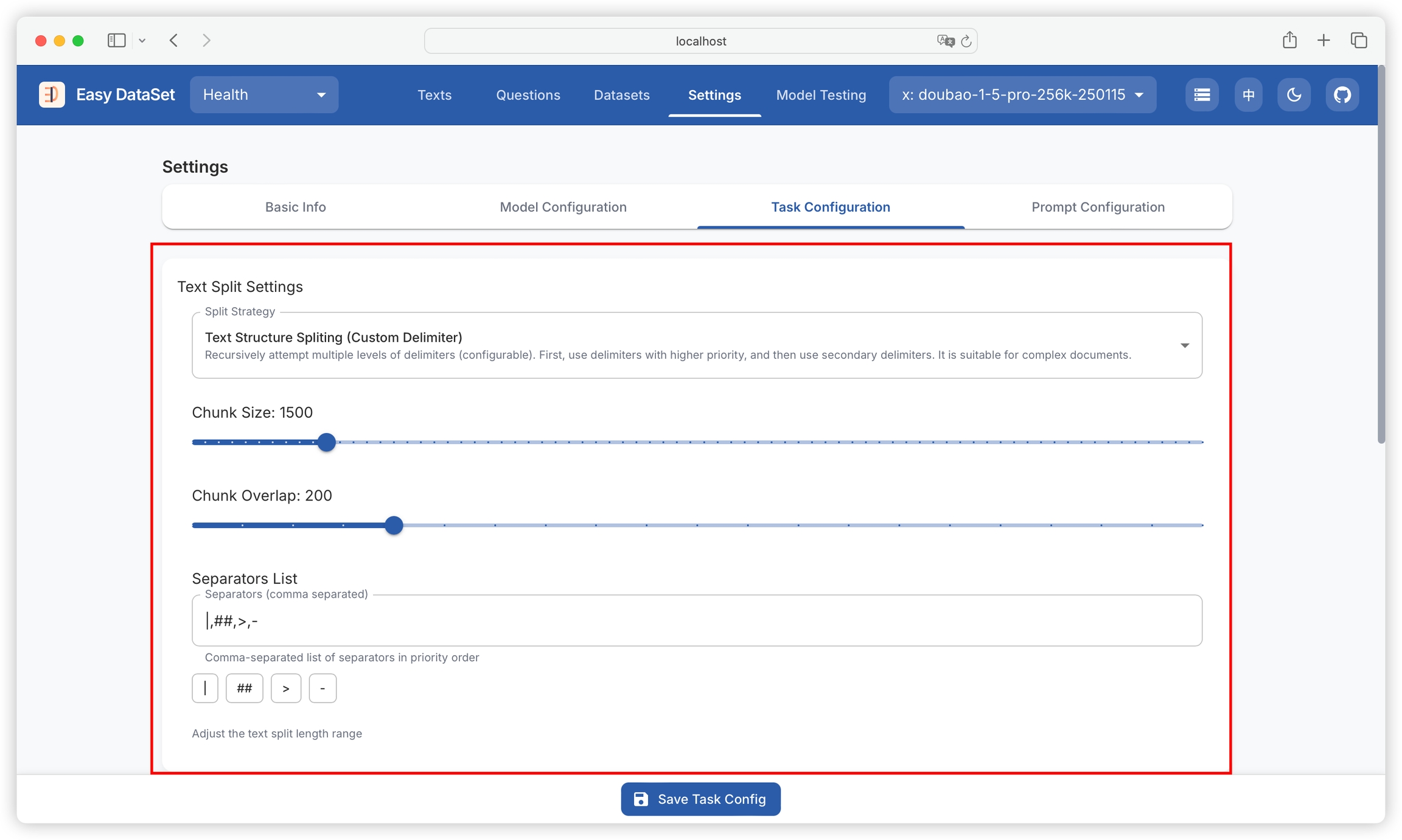
Text splitting operates based on the set length range, dividing input text according to rules into appropriate paragraphs for subsequent processing.
Function: Sets the minimum character length for each text fragment after splitting, with a current default value of 1500. If a text segment is shorter than this value, it will be merged with adjacent text segments until it meets the minimum length requirement.
Setting method: Enter the desired value (must be a positive integer) in the input box after "Minimum Length".
The value should not be too large, as it may result in too few text fragments, affecting the flexibility of subsequent processing; it should also not be too small, to avoid text fragments being too fragmented.
Function: Limits the maximum character length of each text fragment after splitting, with a current default value of 2000. Text exceeding this length will be split into multiple fragments.
Setting method: Enter an appropriate value (must be a positive integer and greater than the minimum length value) in the input box after "Maximum Split Length".
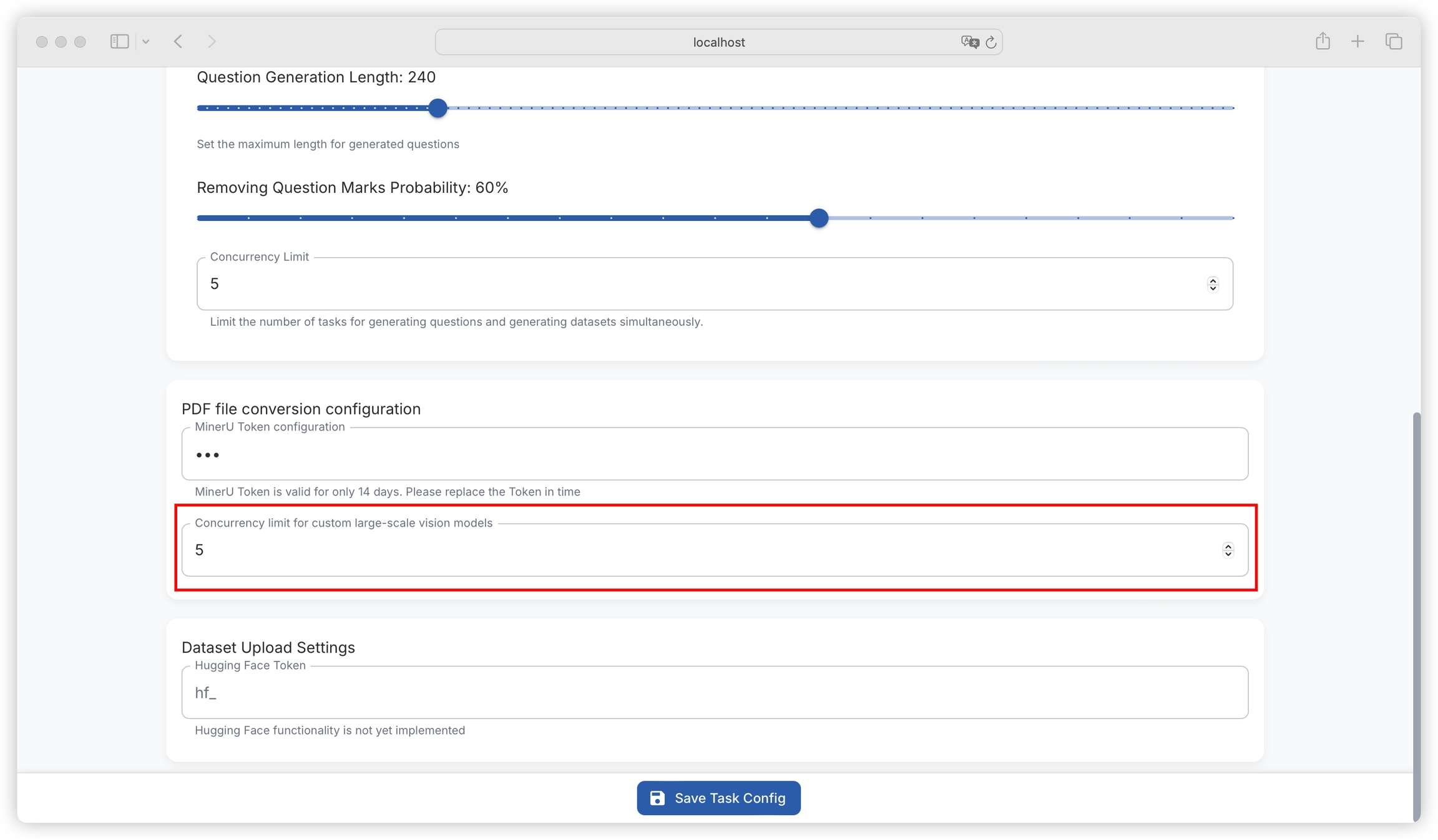
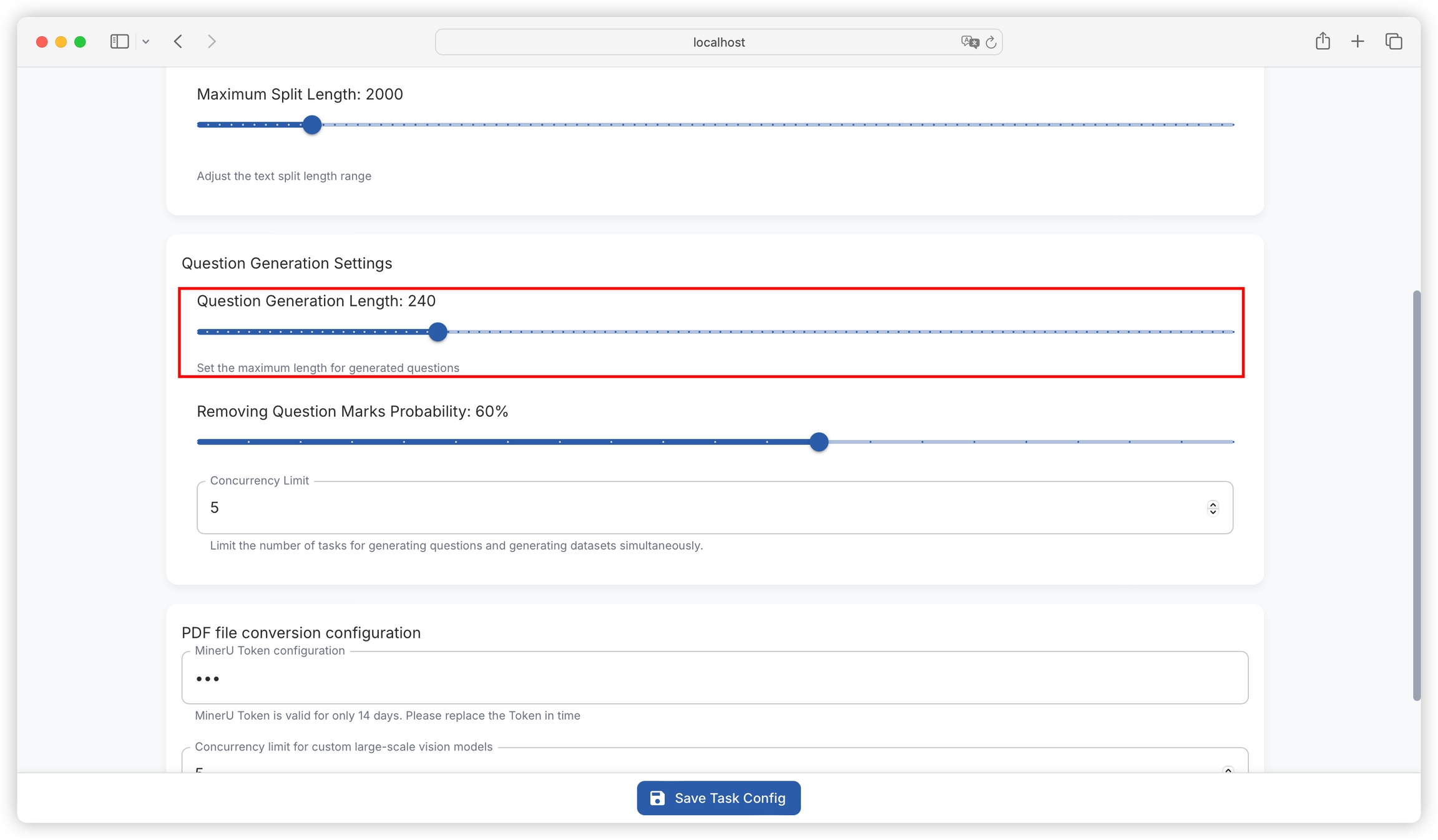
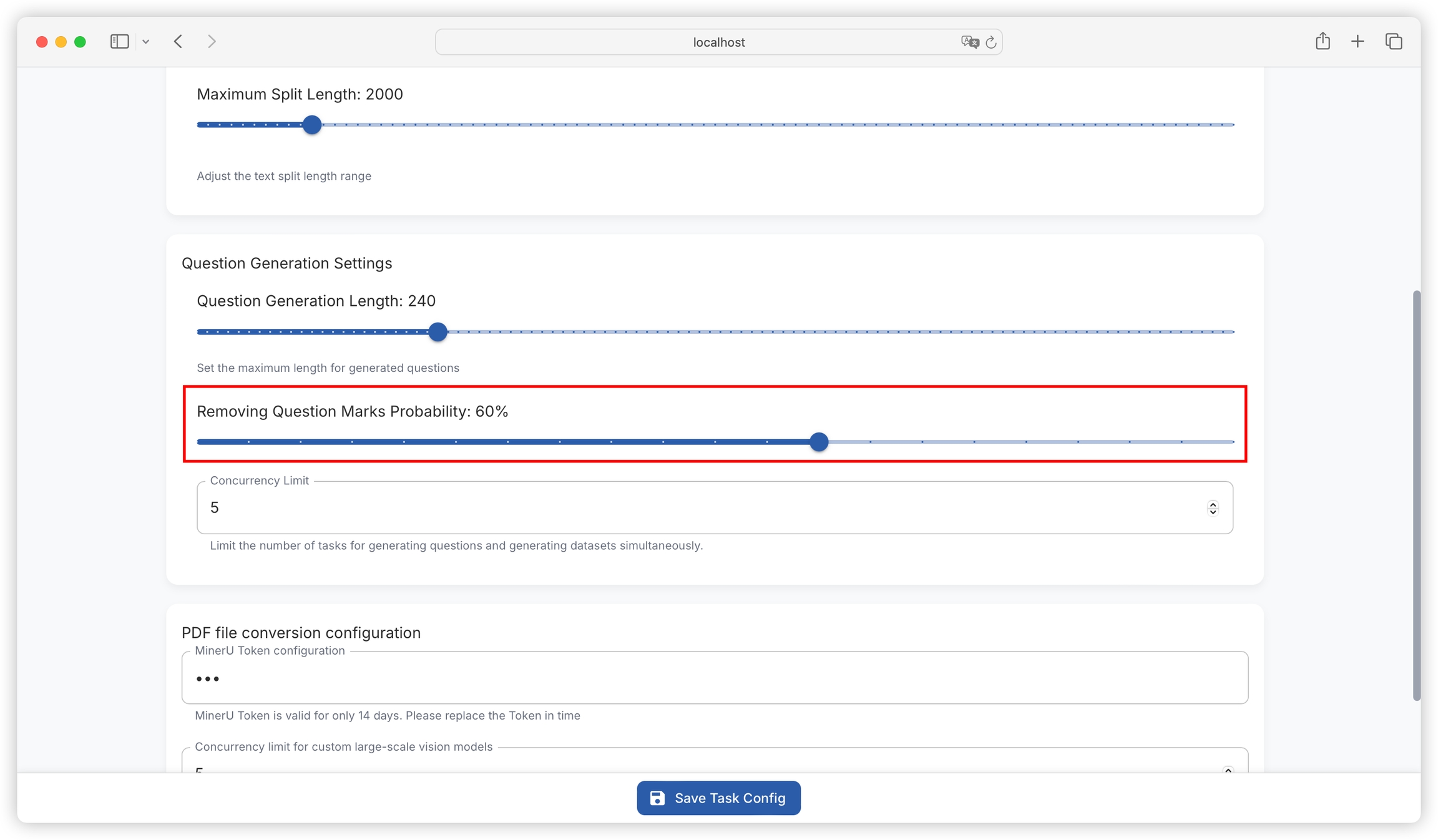
Function: Sets the maximum character length for generated questions, with a current default value of 240. Ensures that generated questions are within a reasonable length range for easy reading and understanding.
Setting method: Enter the desired value (must be a positive integer) in the input box after "Question Generation Length".
Function: Sets the probability of removing question marks when generating questions, with a current default value of 60%. The question format can be adjusted according to specific needs.
Setting method: Enter an integer between 0 and 100 (representing percentage probability) in the input box after "Removing Question Marks Probability".
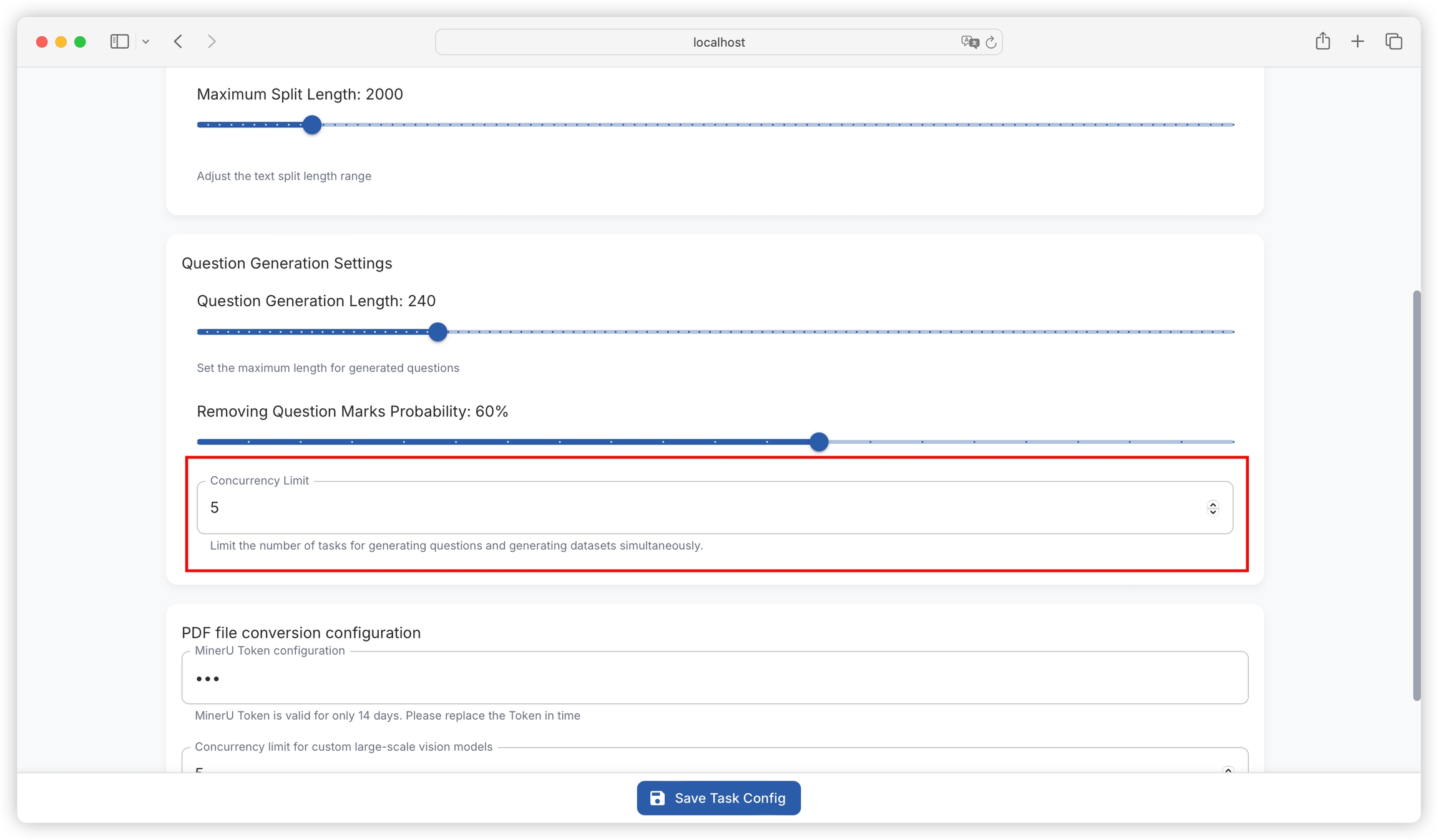
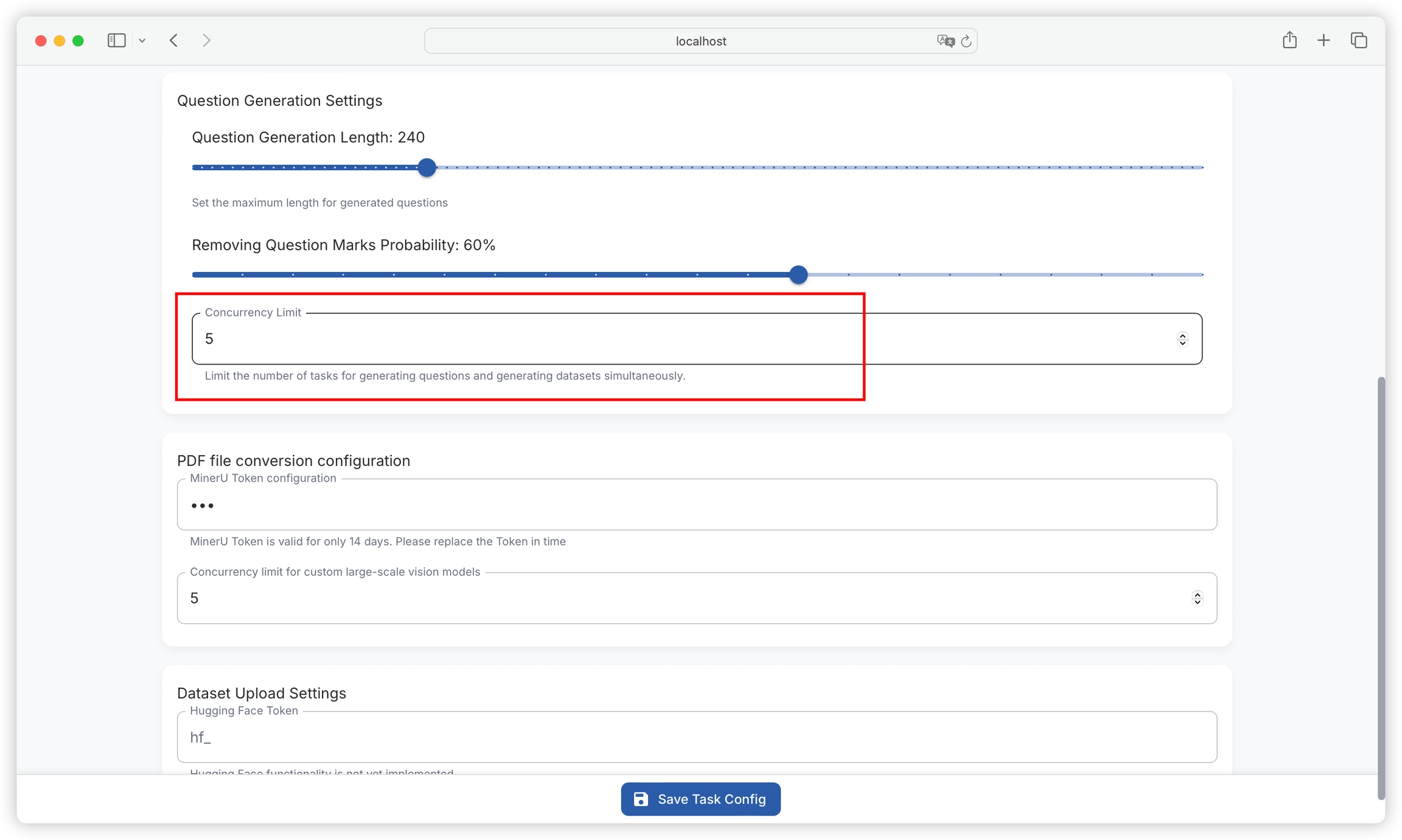
Function: Used to limit the number of simultaneous question generation and dataset generation tasks, avoiding system performance degradation or task failure due to too many tasks occupying too many system resources.
Setting method: Set an appropriate upper limit for concurrent tasks based on system resource conditions and task requirements. Specific operations may require finding the corresponding input box or slider in the relevant settings interface (if available).
When setting, consider factors such as server hardware performance and network bandwidth. If there are too many concurrent tasks, it may lead to long task queue waiting times or even task timeout failures.
Function: MinerU Token is used for authentication and authorization for PDF conversion based on MinerU API.
Setting method: Enter a valid MinerU Token in the corresponding input box. Note that the MinerU Token is only valid for 14 days, and a new Token needs to be replaced promptly after expiration to ensure normal function use.
Function: Limits the number of concurrent tasks related to custom large-scale vision models, reasonably allocates system resources, and ensures the stability and efficiency of model processing tasks.
Setting method: Carefully set concurrency limits based on the computational complexity of the model and system resource conditions. Too high may lead to excessive system load, while too low may not fully utilize system resources.
Function: Hugging Face Token is used for authentication when interacting with the Hugging Face platform to implement functions such as dataset uploading (currently the Hugging Face function has not been implemented, this Token setting is temporarily reserved).
Setting method: Enter the Token generated by the Hugging Face platform in the input box after "hf_".
is a powerful large model dataset creation tool.
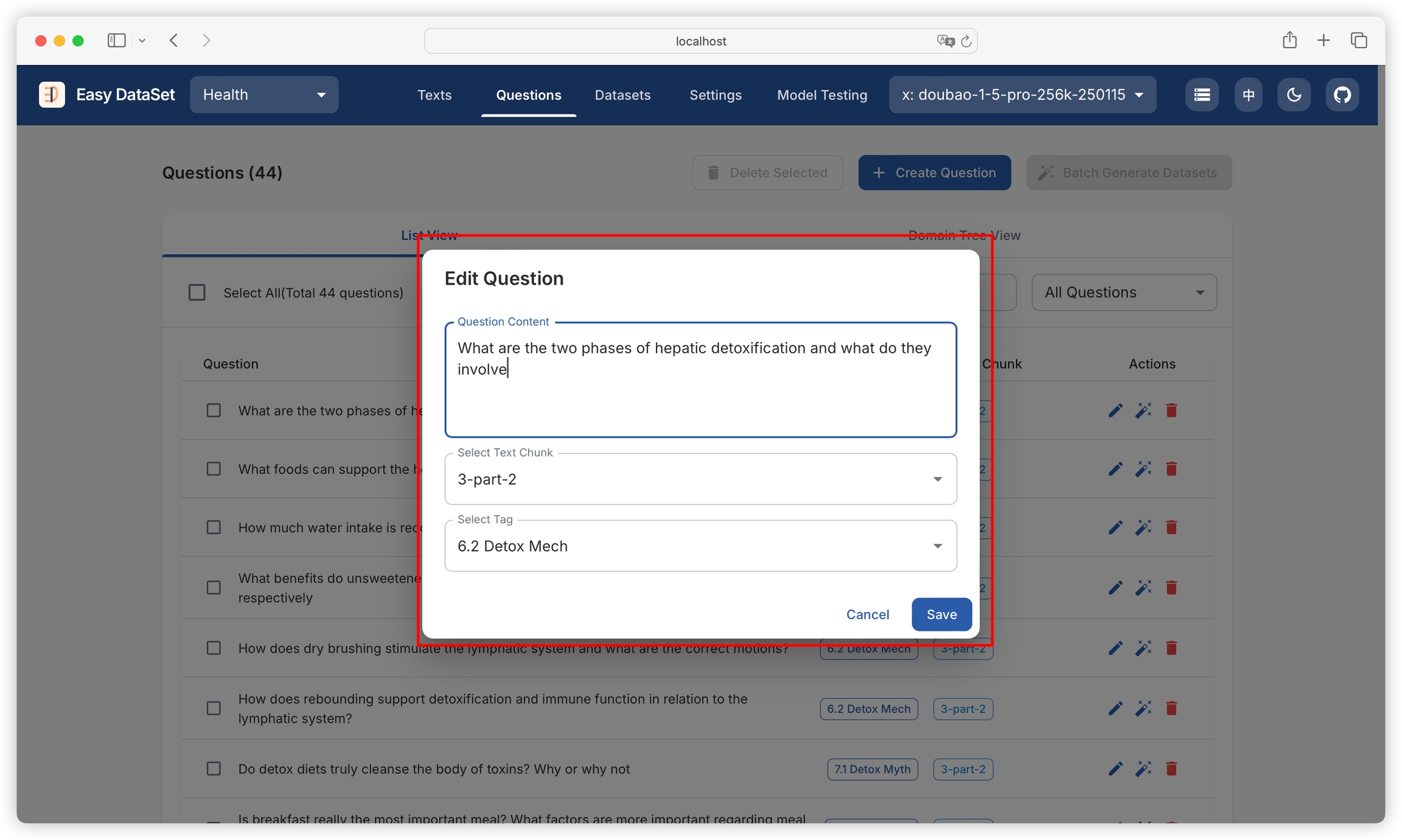
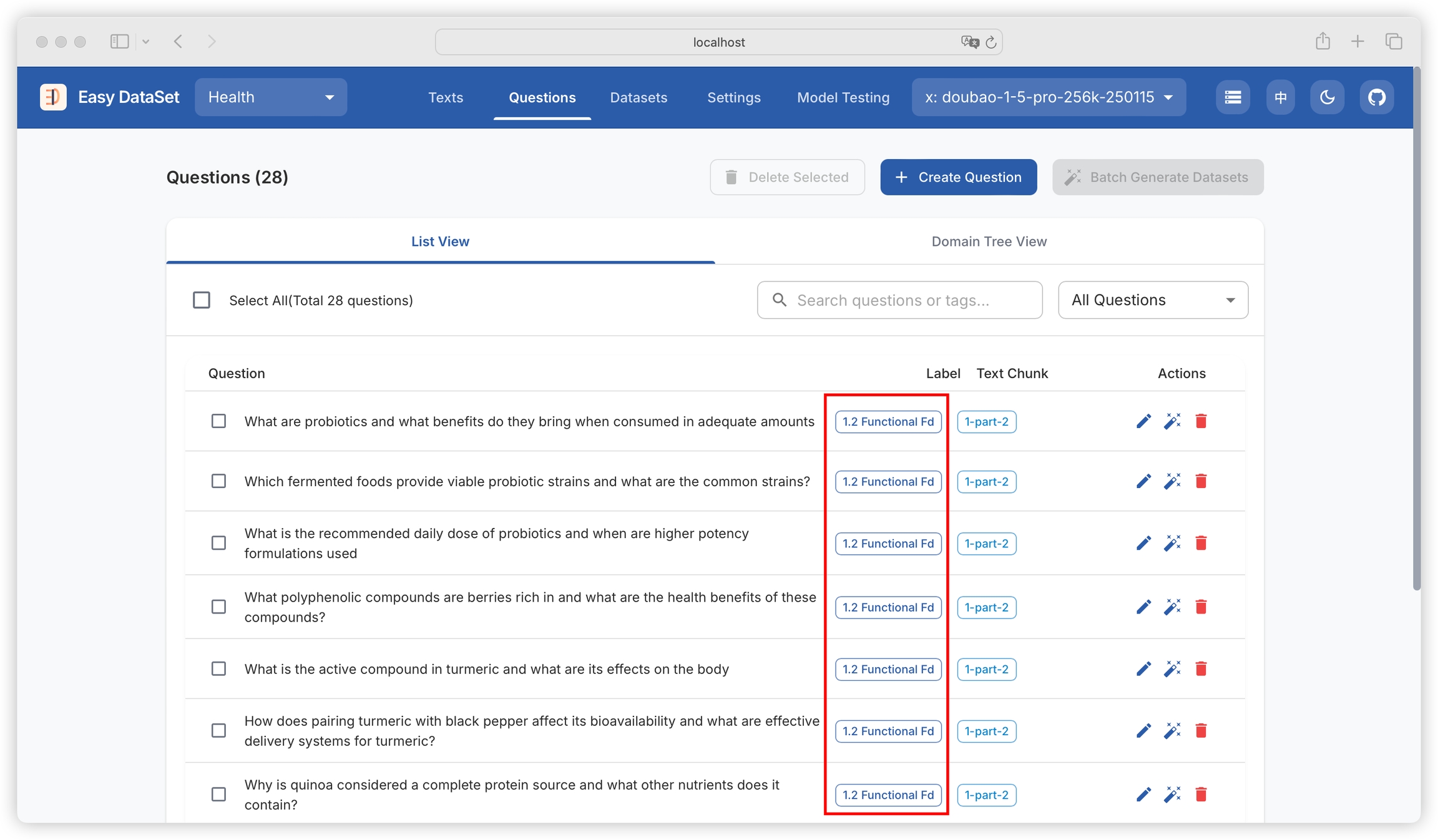
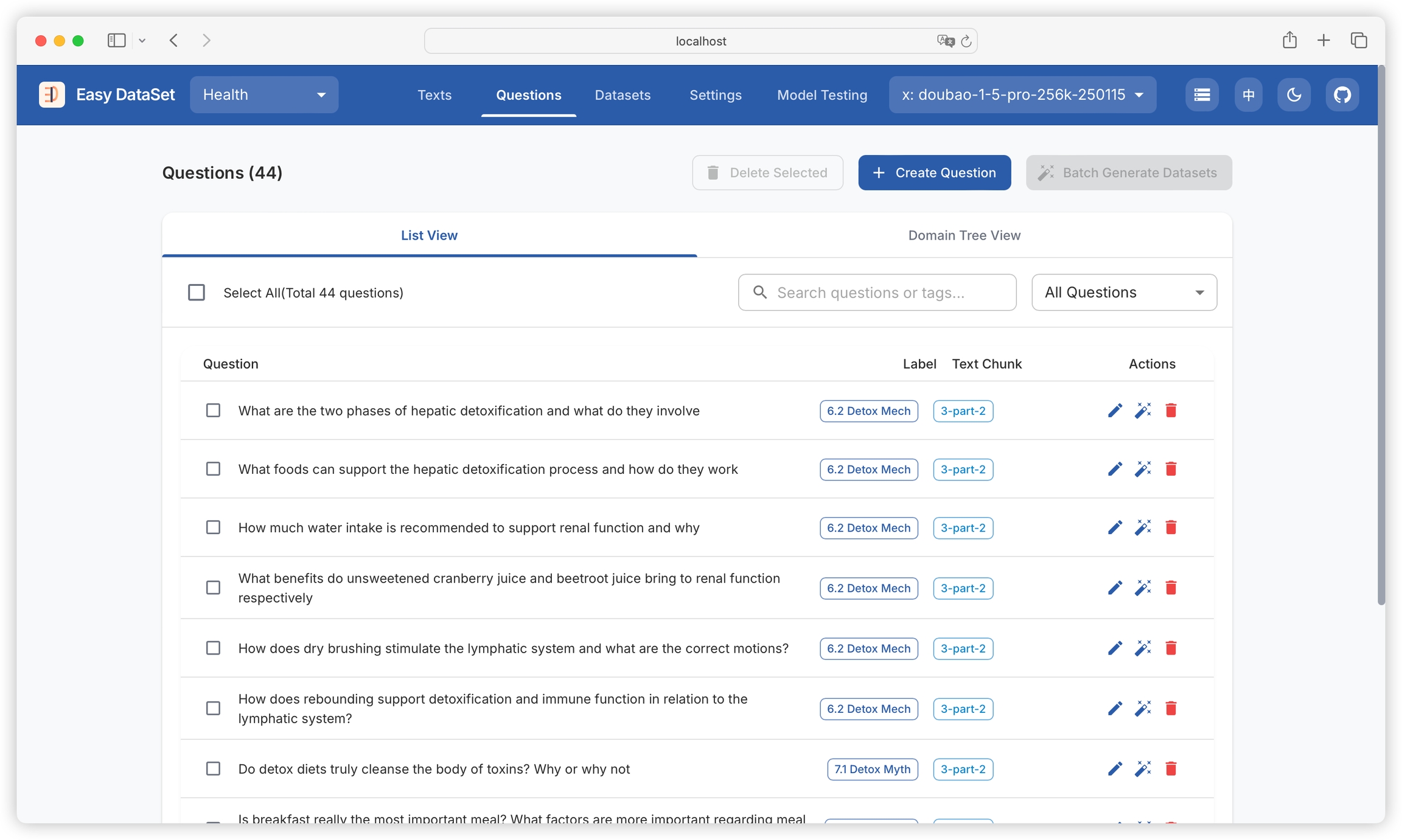
You can view question names, domain tags associated with questions, and text blocks to which questions belong. You can filter by question and tag names:
Supports editing existing questions and adding custom questions:
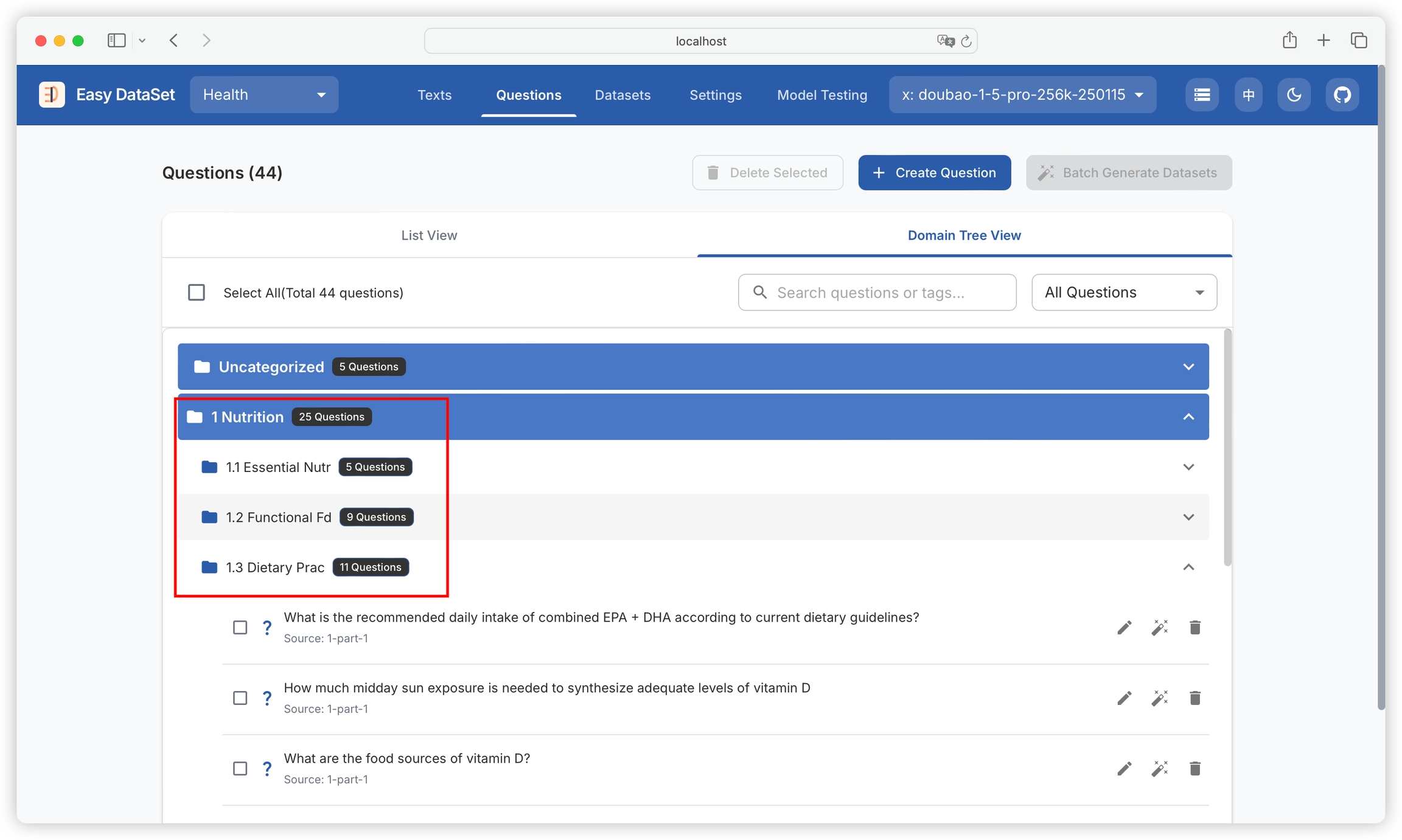
You can use the domain tree view to see questions constructed under each domain tag:
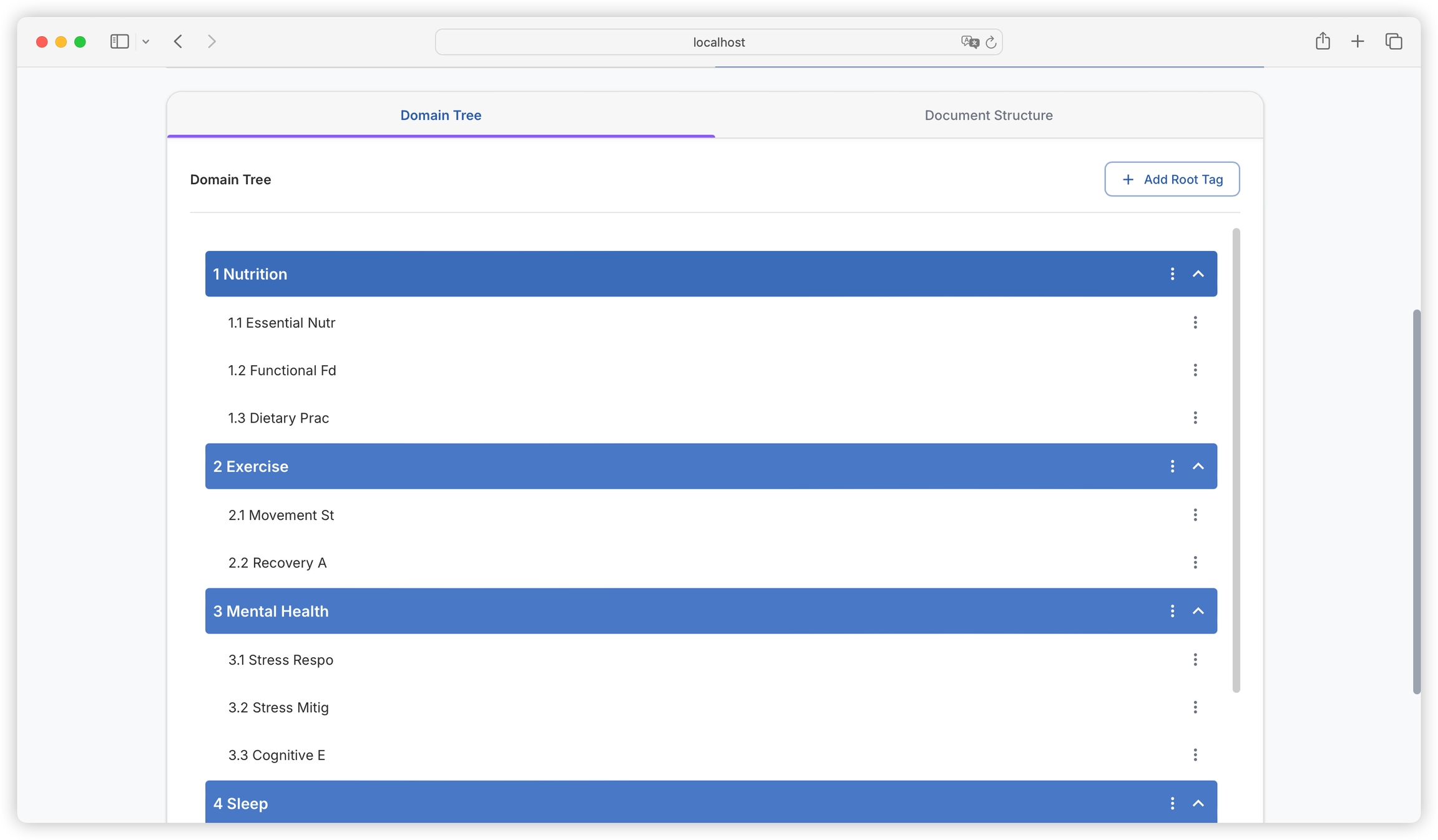
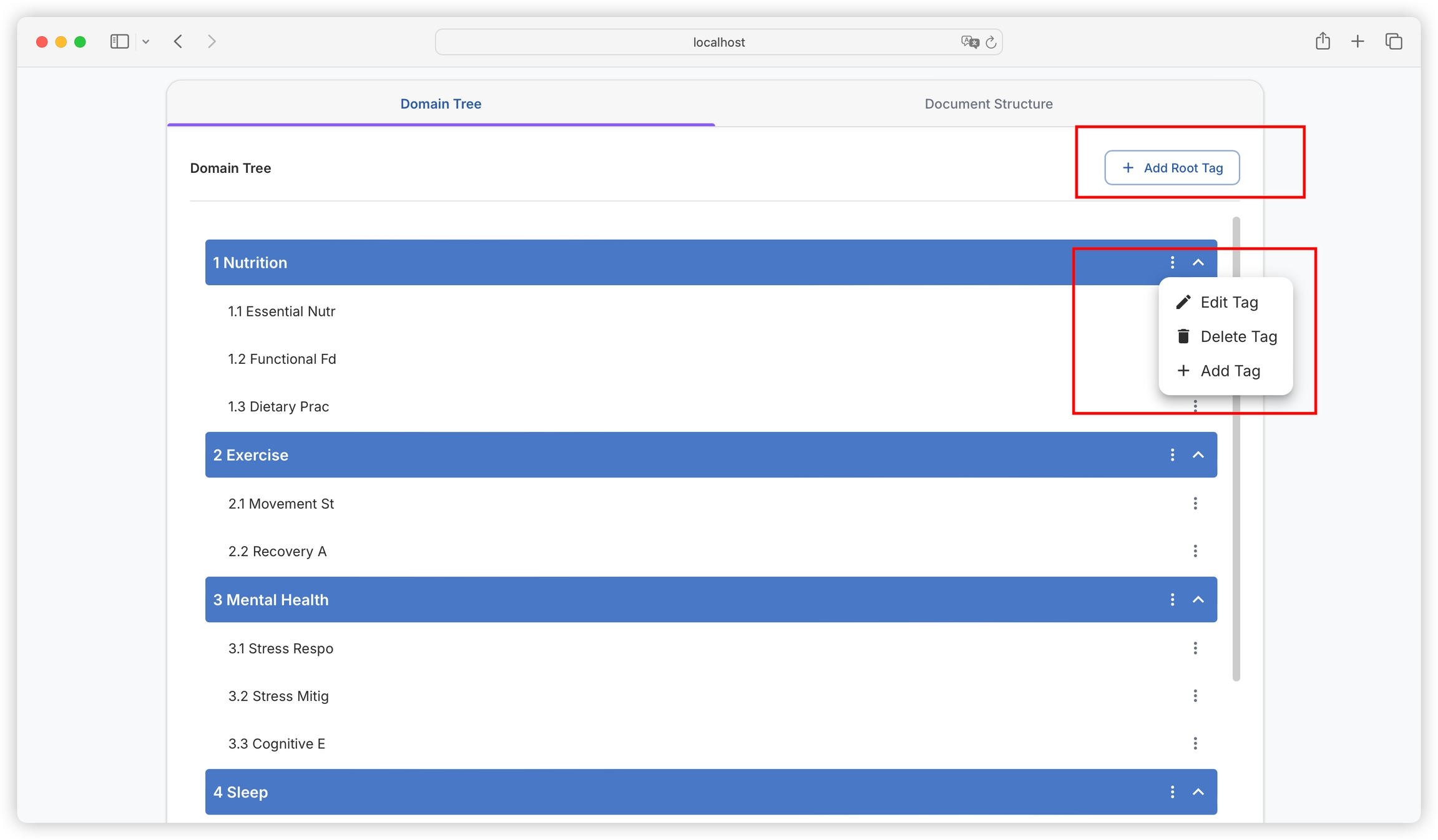
Switch to the Domain Tree tab, and you can see the domain tree intelligently analyzed by AI based on the literature, as well as the original directory extracted from the literature:
In subsequent tasks of generating questions and datasets, the platform will build based on this domain tree, and map the generated questions and datasets to each domain tag. The domain tree allows each dataset to have global understanding capabilities and reduces the possibility of generating duplicate datasets.
If you feel that there are inaccuracies or imperfections in the AI-generated domain tree, you can also directly manually add, modify, or delete tags. It is recommended to confirm the domain tree division more accurately before generating questions.
Currently, the platform supports processing literature in four formats: Markdown, PDF, DOCX, and TXT:
Models understand Markdown literature with good structural organization best. It is recommended to prioritize uploading Markdown files.
Due to the special nature of PDF format, the platform supports four different PDF processing methods for different scenarios. When literature containing PDF format is uploaded, a dialog box will appear:
Focuses on quickly identifying key outlines of simple PDF files. It is efficient for processing well-structured plain text reports and simple documentation, but cannot accurately parse files containing complex content such as large numbers of formulas and charts.
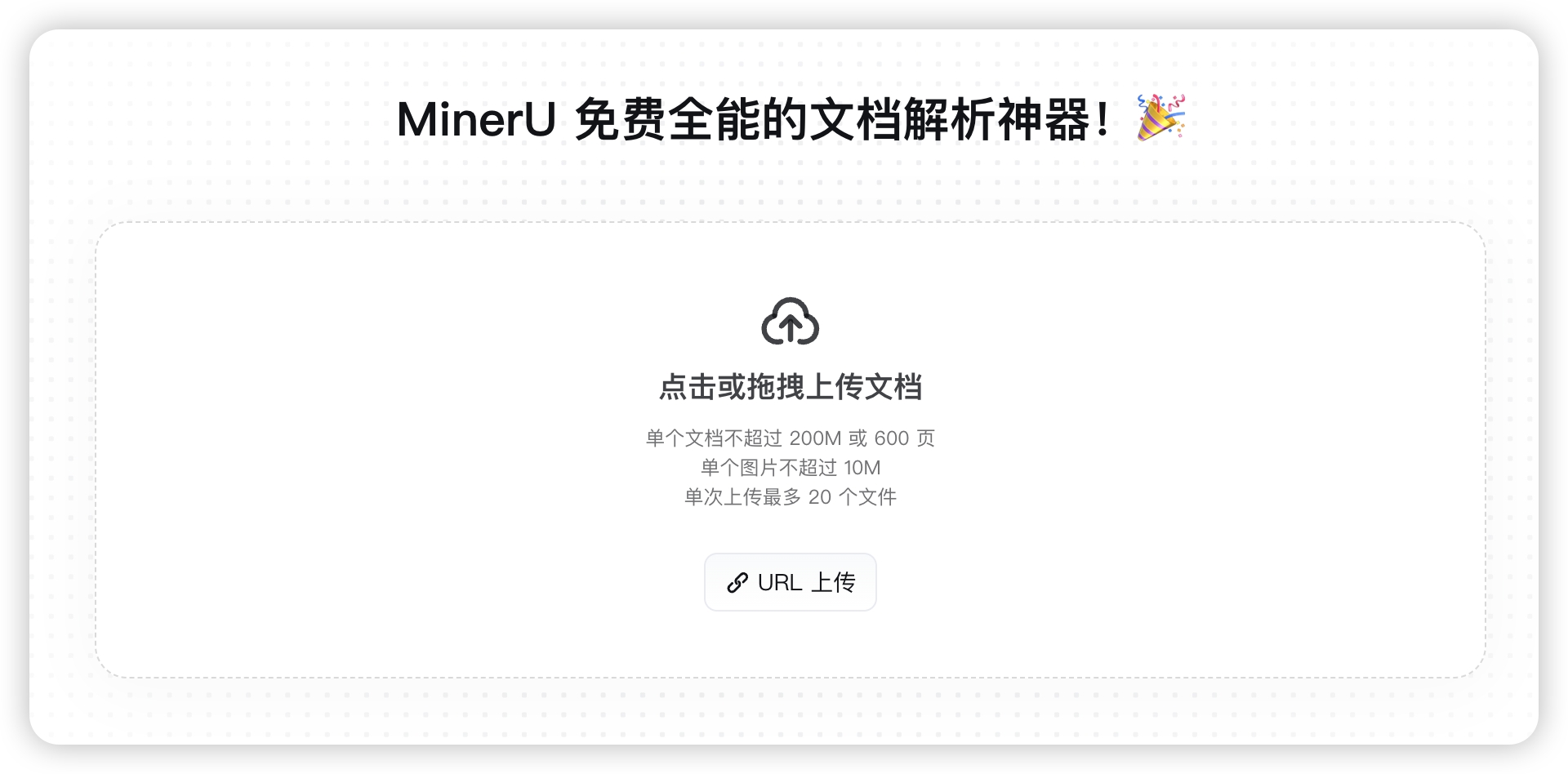
You can configure the MinerU API Key through "Settings - Task Settings" to call the MinerU API for parsing. It can deeply parse complex PDF files containing formulas and charts, suitable for academic papers, technical reports, and other scenarios. The more complex the file, the slower the processing speed. You can apply for a MinerU API Key through https://mineru.net/apiManage/token (note that the validity period is 14 days, after which you need to reconfigure).
Redirects to the MinerU platform: https://mineru.net/OpenSourceTools/Extractor, where users can parse PDFs and download Markdown files, then return to the platform to re-upload them.
Can recognize complex PDF files, including formulas and charts. This method requires adding vision model configuration in the model configuration to parse PDF files through a custom vision model. Parsing rules and model parameters can be customized according to specific needs to adapt to different types of complex PDF files.
When choosing MinerU API parsing or custom vision model parsing, the PDF processing time may be longer, please wait patiently:
You can configure the maximum number of concurrent custom vision models and the maximum number of pages to process simultaneously through "Settings - Task Settings". The more concurrent models, the faster the processing speed, but please consider the concurrency limit of the model provider.
Before uploading, please select the model in the top right corner, otherwise, the processing will fail:
Note that there is no need to select a reasoning model (such as DeepSeek-R1) in this step. Selecting a normal question-answering model, such as Doupai or Qianwen, is sufficient. Reasoning models will not provide any advantages in this step and will slow down the processing speed.
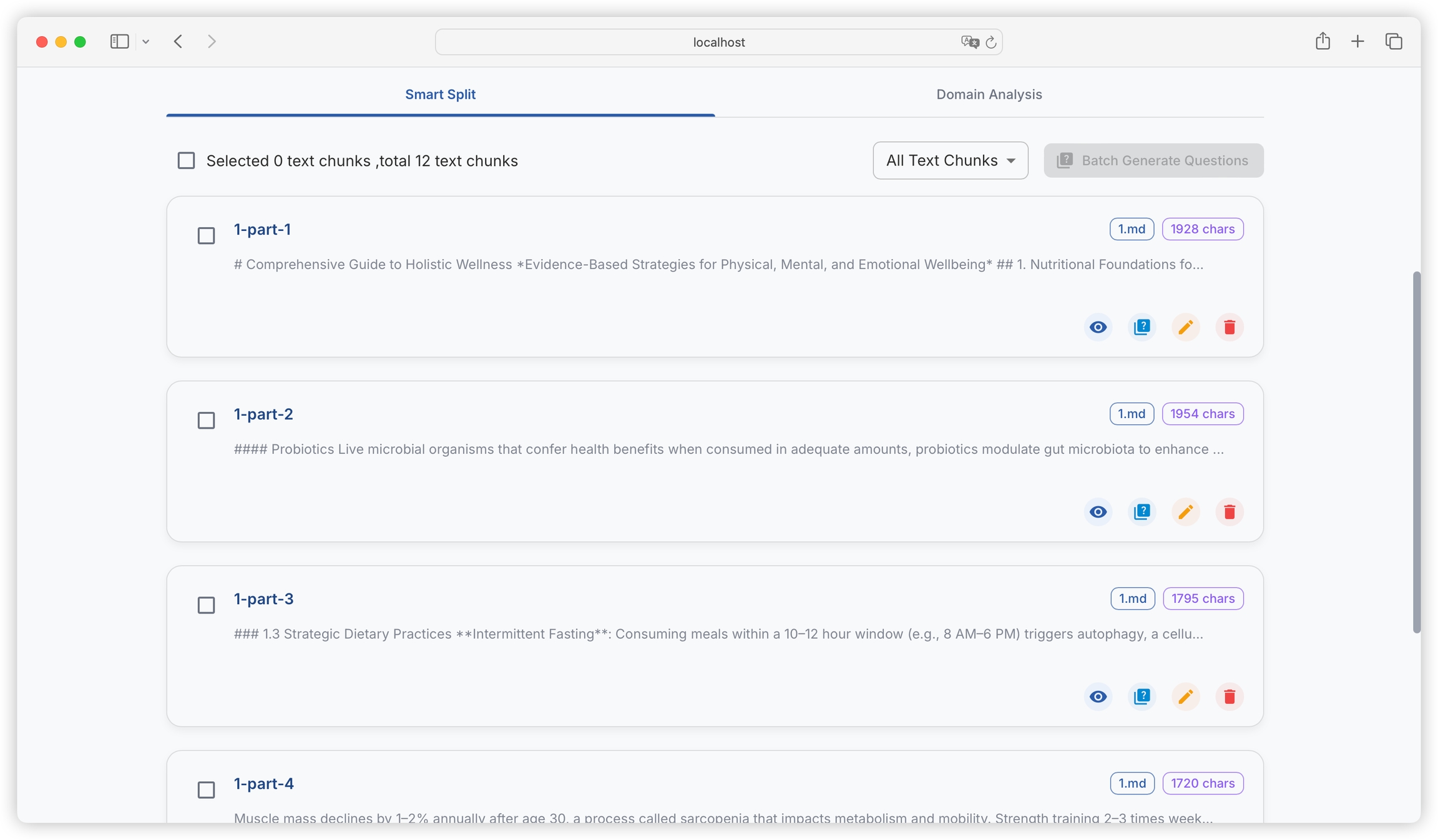
After uploading, the platform will intelligently segment the text into blocks, and we can see the segmented text blocks and the number of characters in each block:
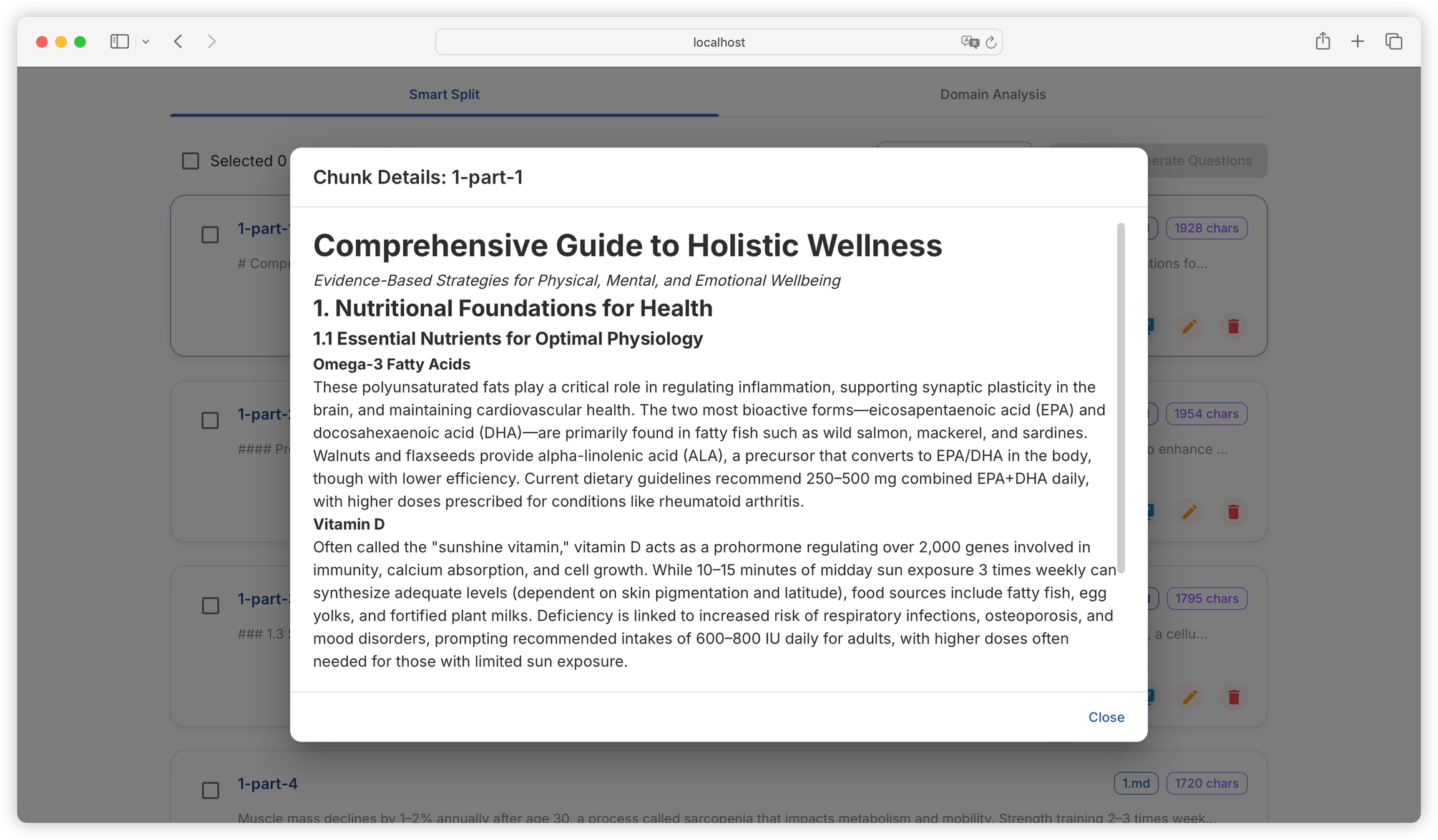
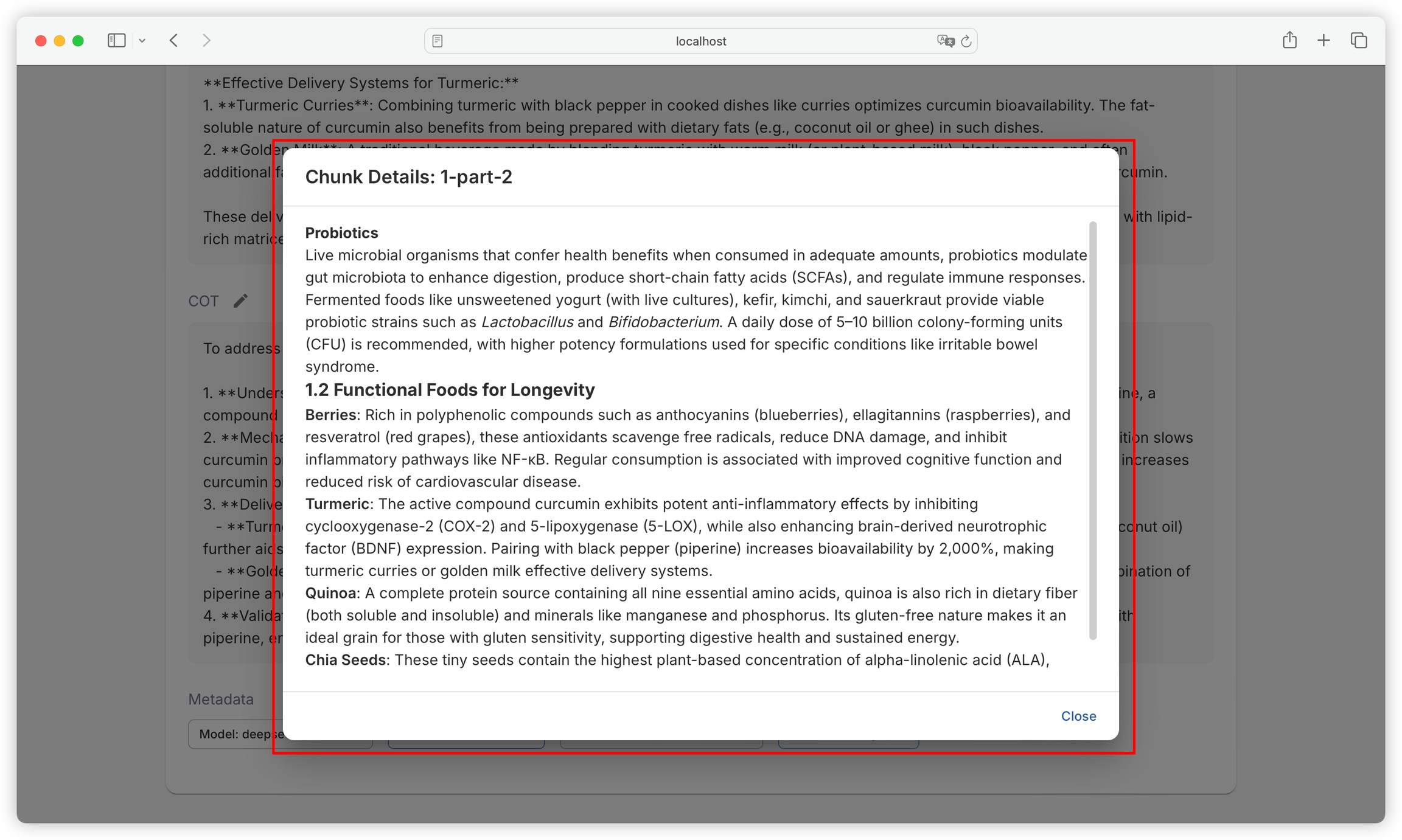
We can view the details of each text block:
We can edit each text block:
For more information on the principles of text segmentation and how to customize segmentation rules to adapt to different literature structures, please refer to the "Custom Segmentation" chapter.
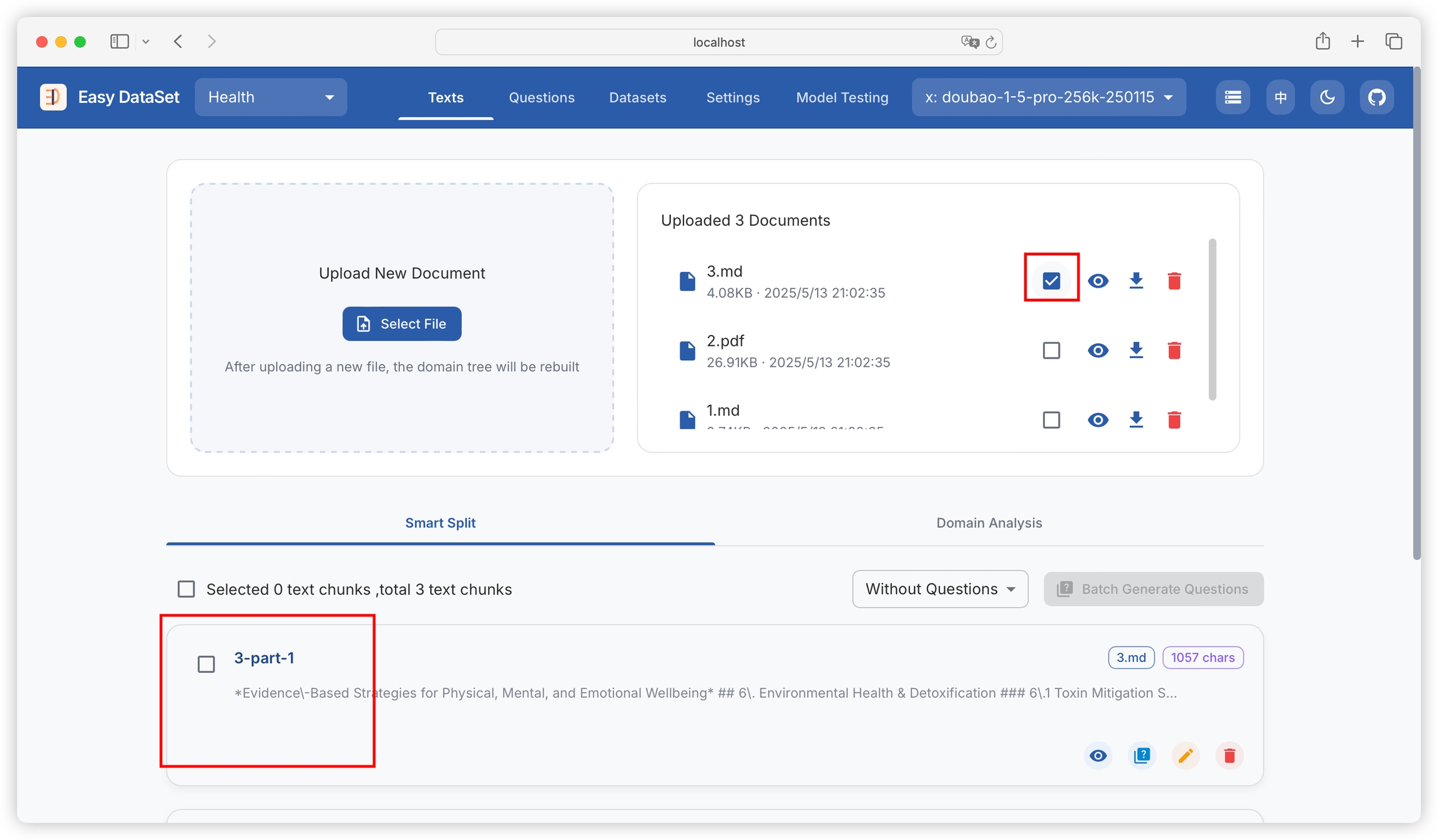
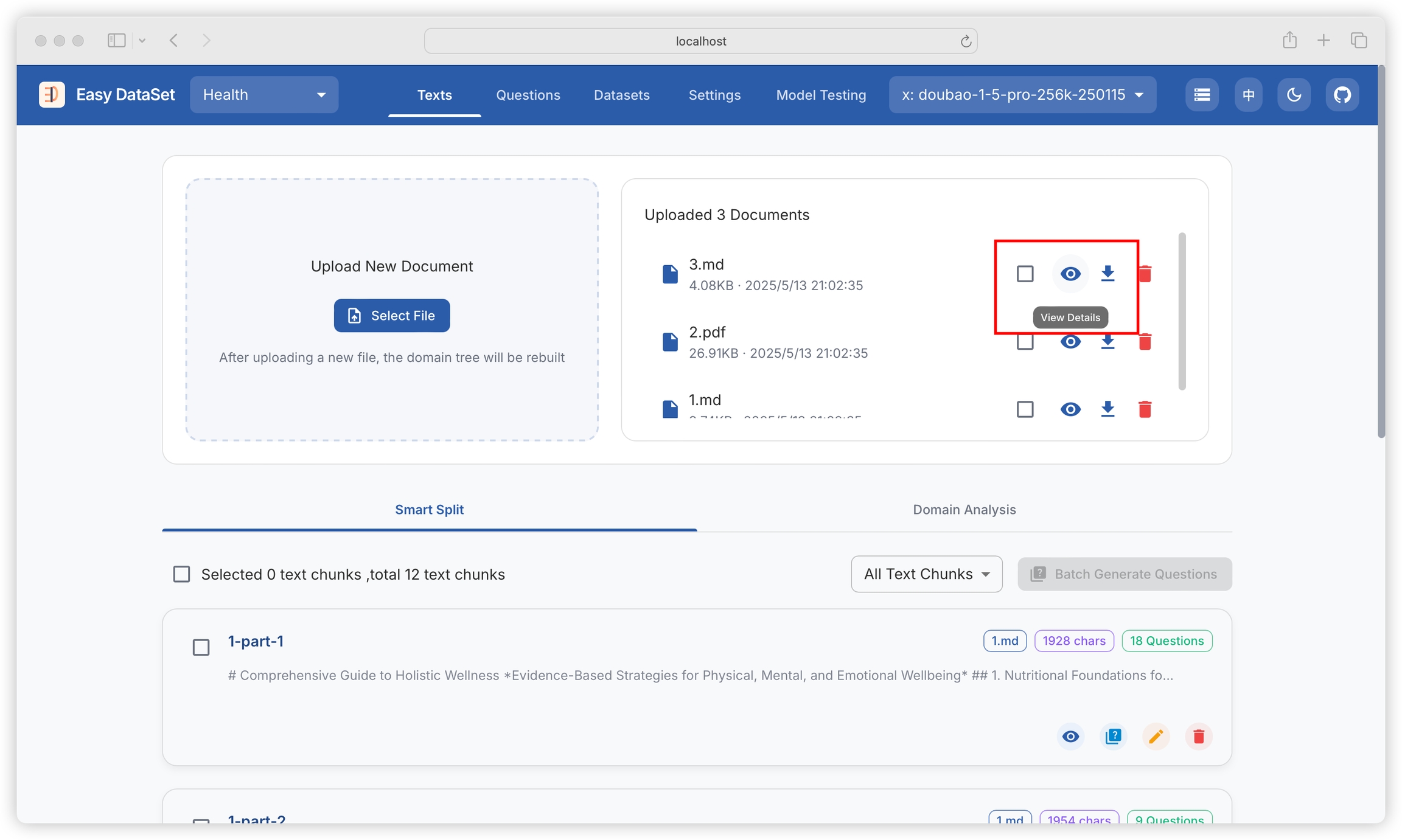
We can filter the text blocks generated for a specific literature:
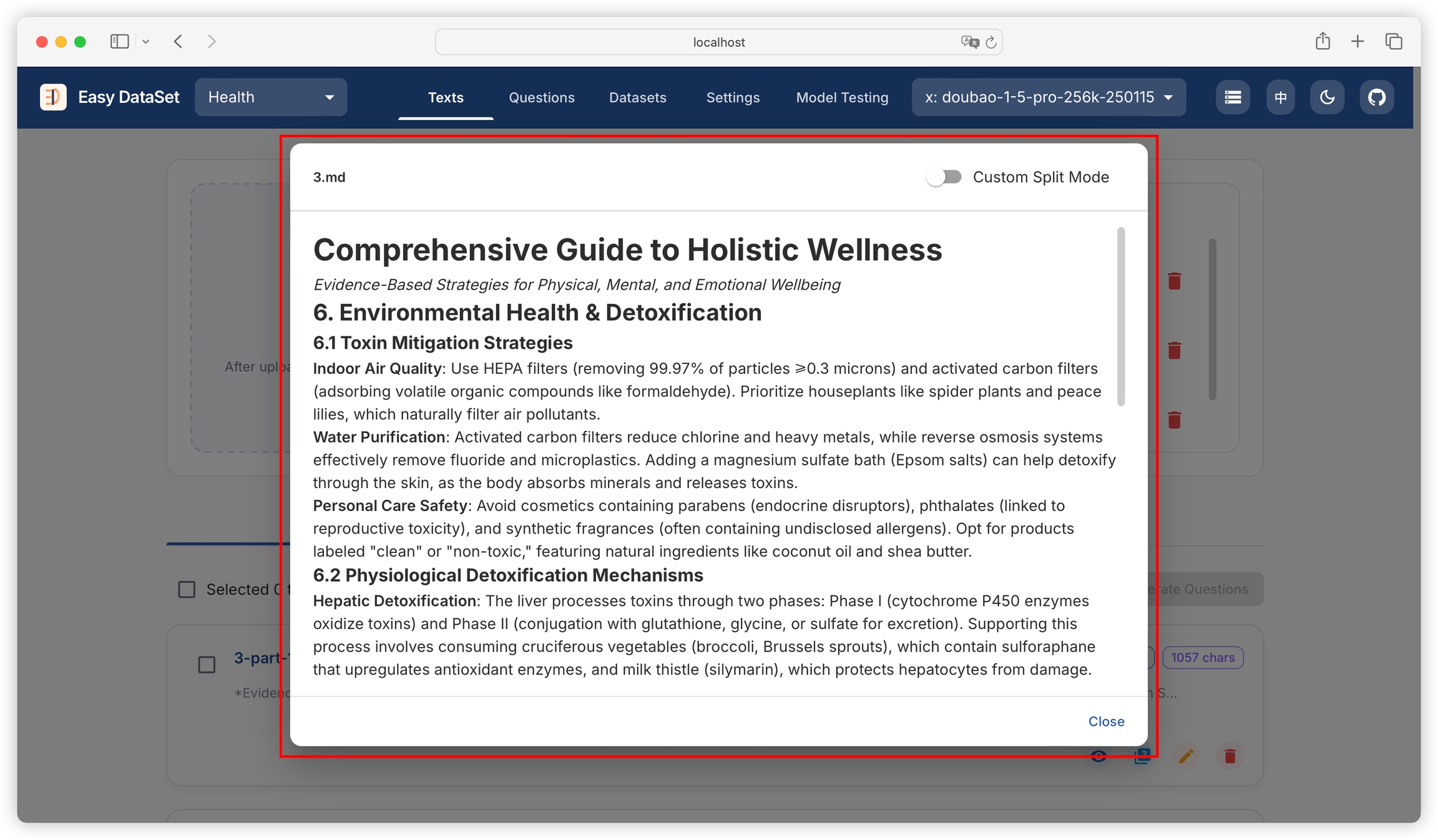
We can preview the literature details (converted to Markdown), download the literature (Markdown), and delete the literature:
Preview the literature:
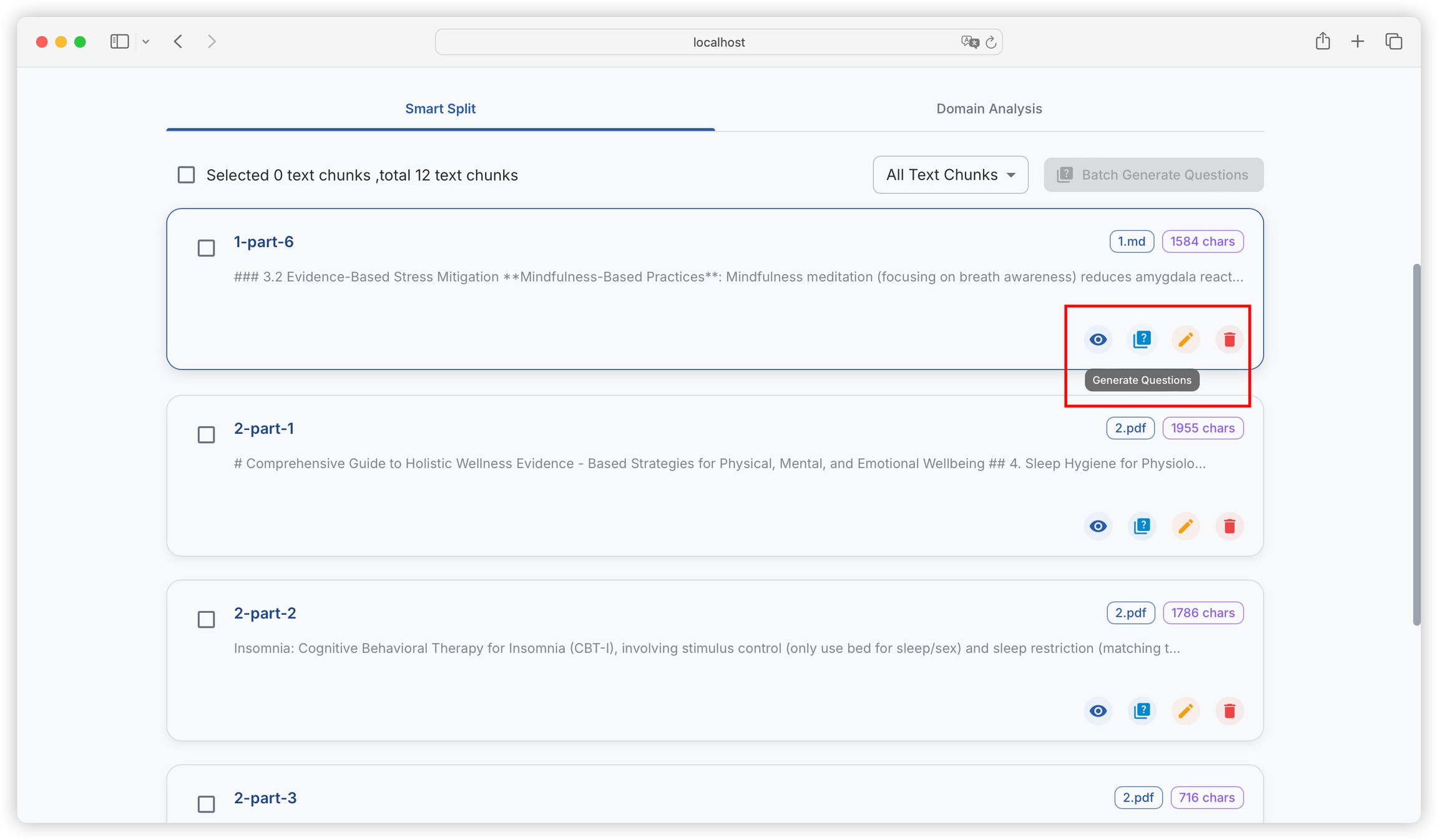
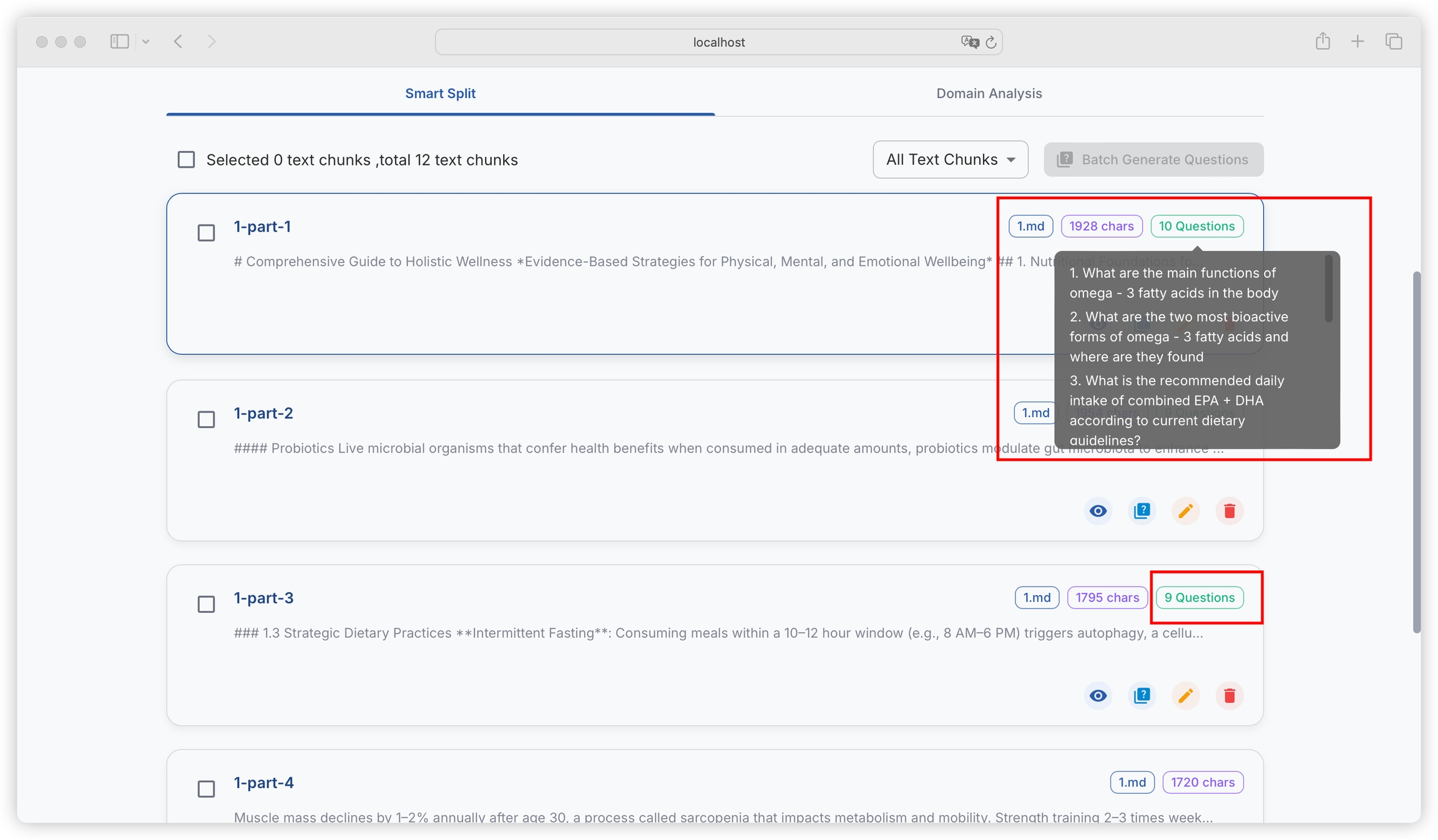
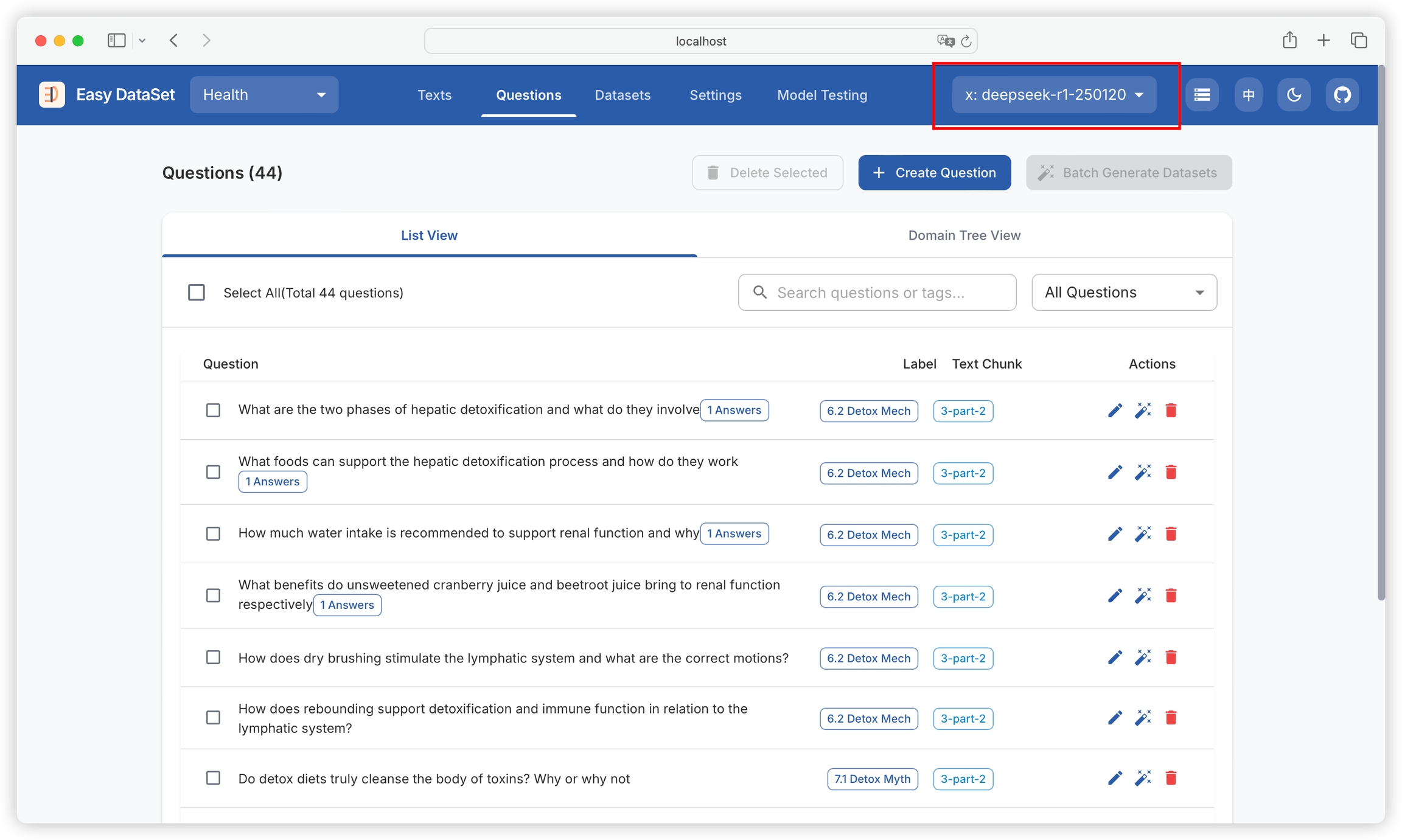
After the task is completed, you can view the generated questions in the text block.
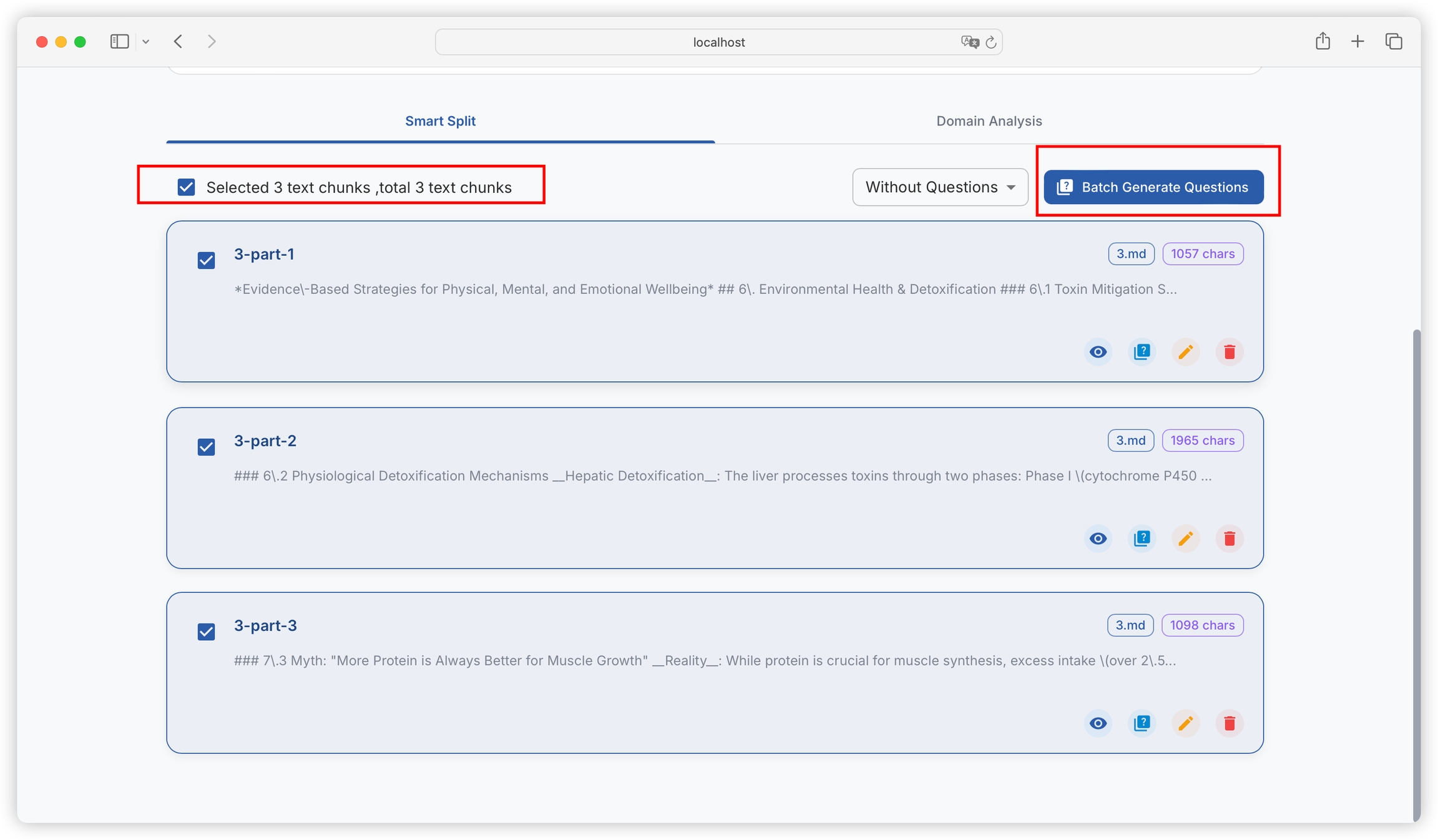
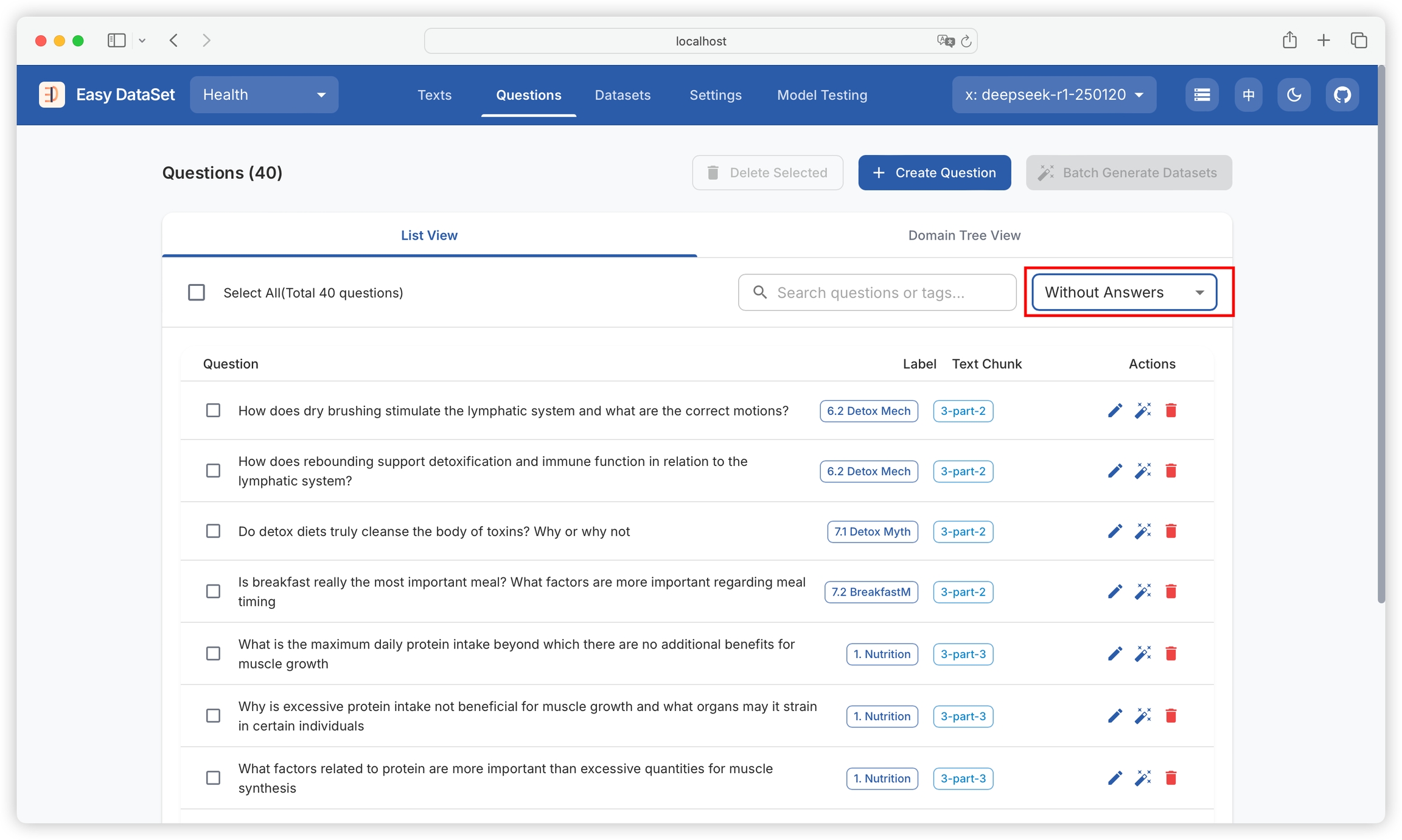
You can filter text blocks with generated questions and text blocks without generated questions:
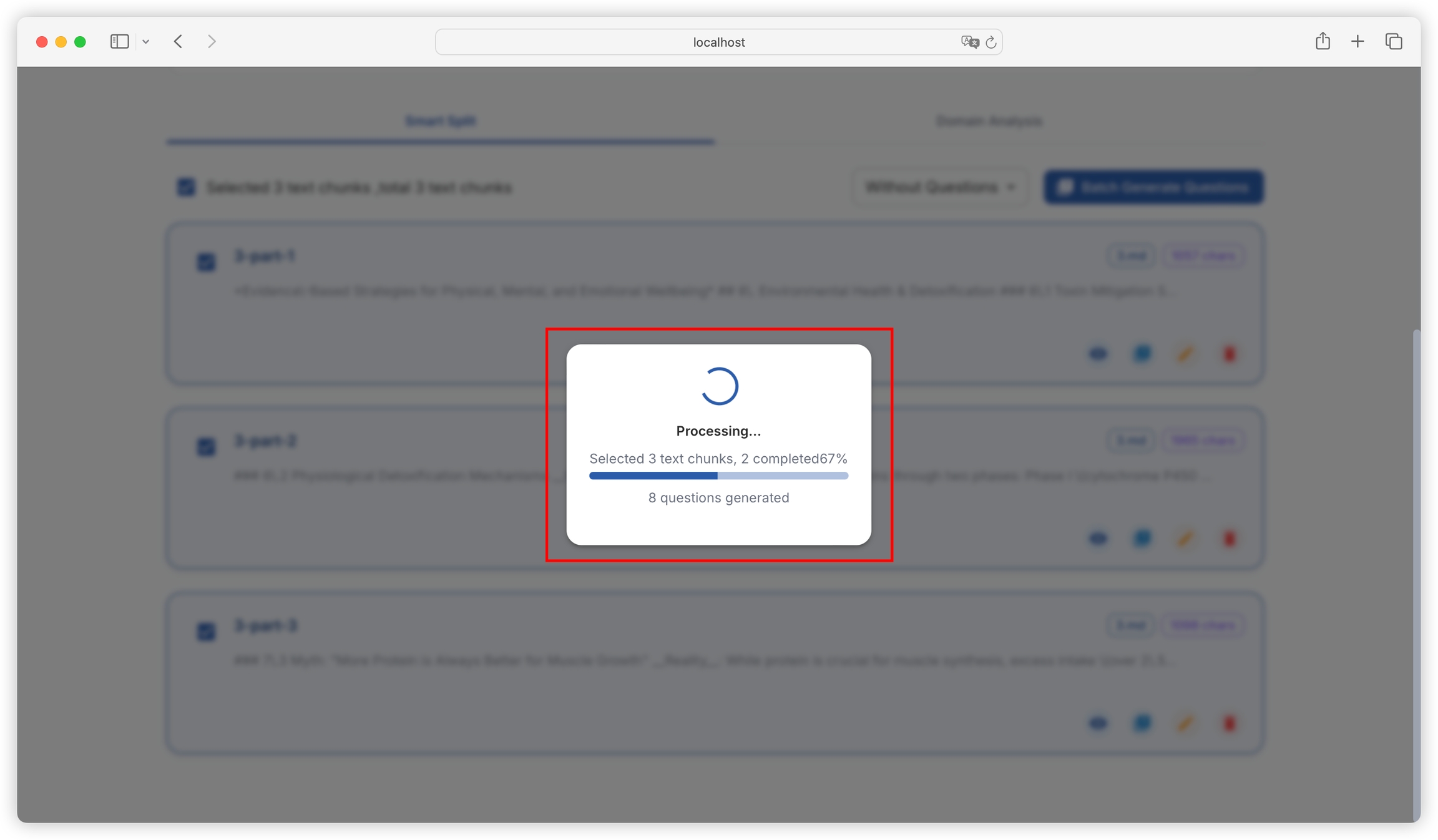
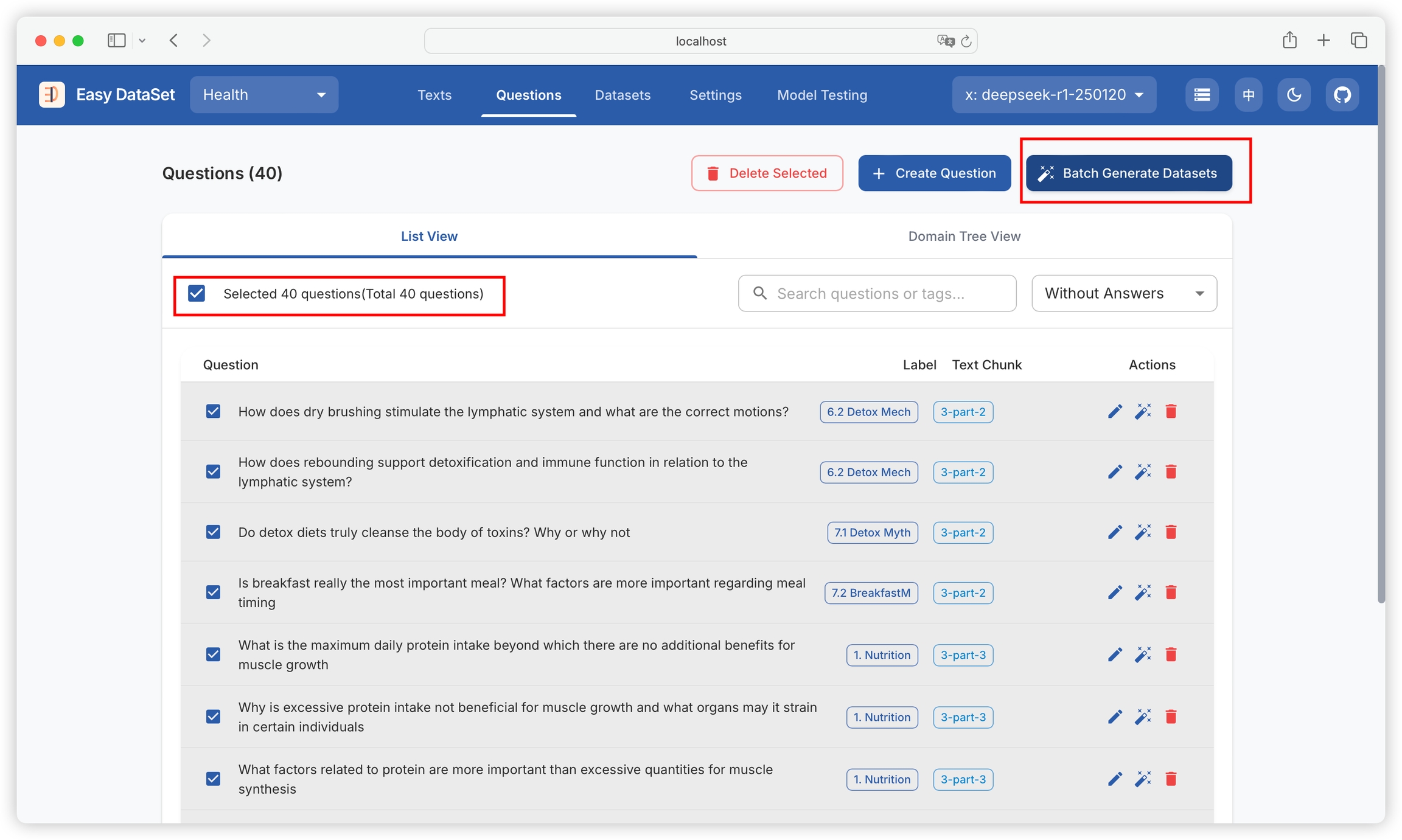
You can batch select or select all text blocks, and construct questions in batch:
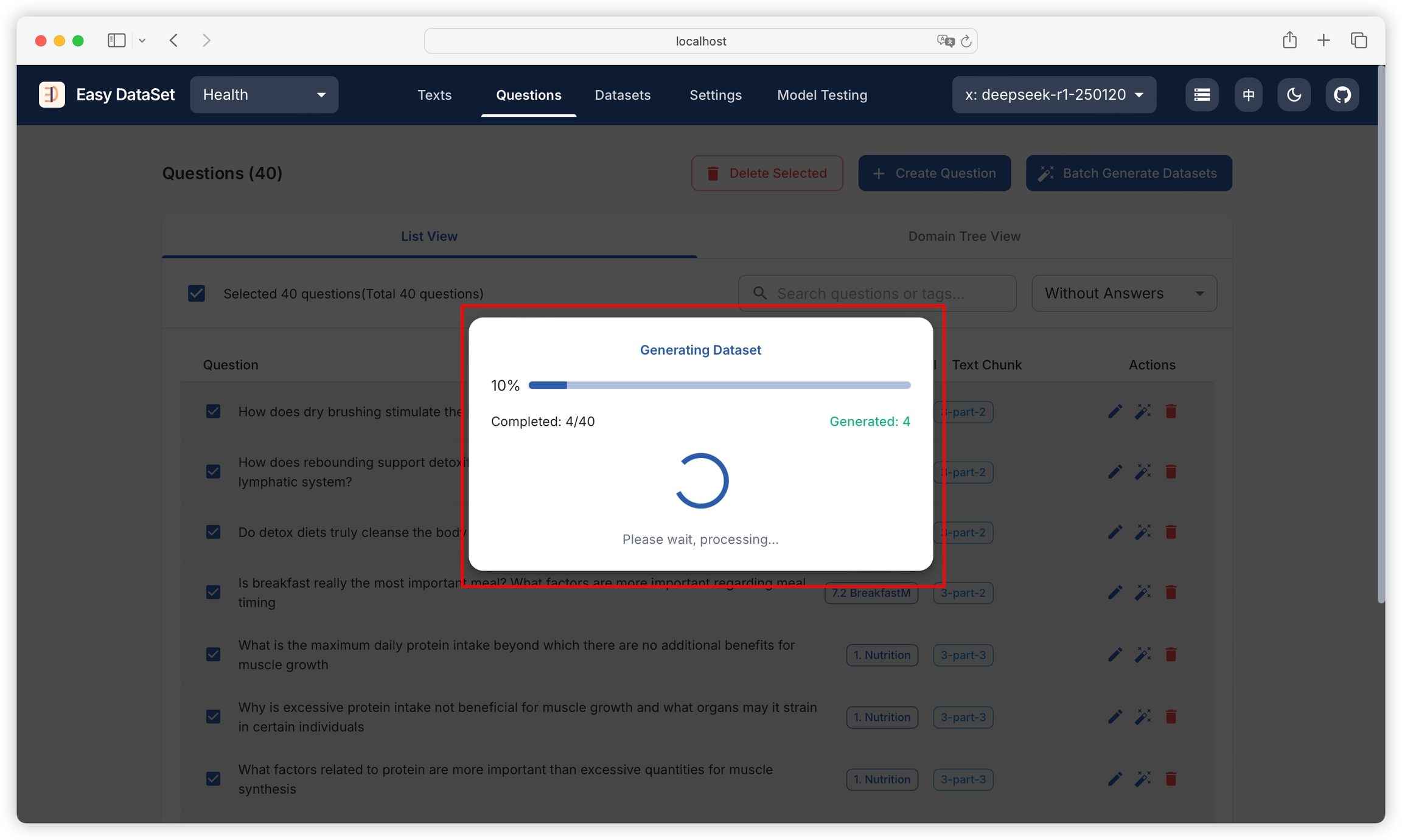
You can view the progress of batch tasks in real-time:
How many questions are generated for each text block is determined by the maximum length for generating questions in "Project Settings - Task Settings". The default setting is to generate one question per 240 characters. For text blocks of around 2000 characters, about 8 questions will be generated. You can flexibly adjust this according to the information density of your literature:
You can also control the proportion of question marks (?) to be removed in the generated questions (default will remove 60%).
In actual Q&A tasks, users' questions do not always include question marks. Removing a certain percentage of question marks helps improve fine-tuning effects.
You can control the maximum number of concurrent tasks in batch tasks (default maximum concurrency is 5 tasks).
Note that some model providers will limit the maximum number of concurrent tasks. Setting too large a value may cause batch tasks to fail. It is recommended to flexibly test and adjust.
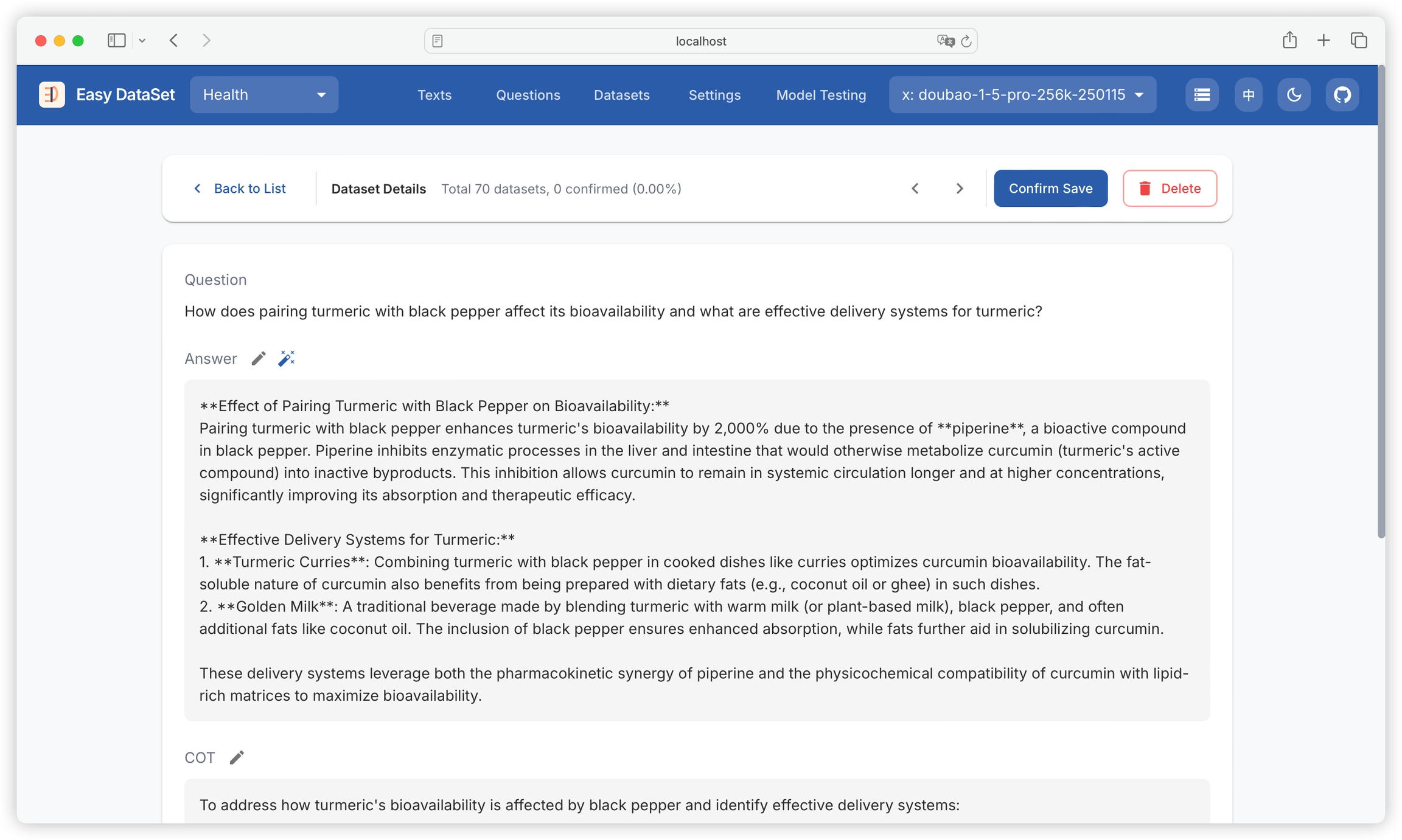
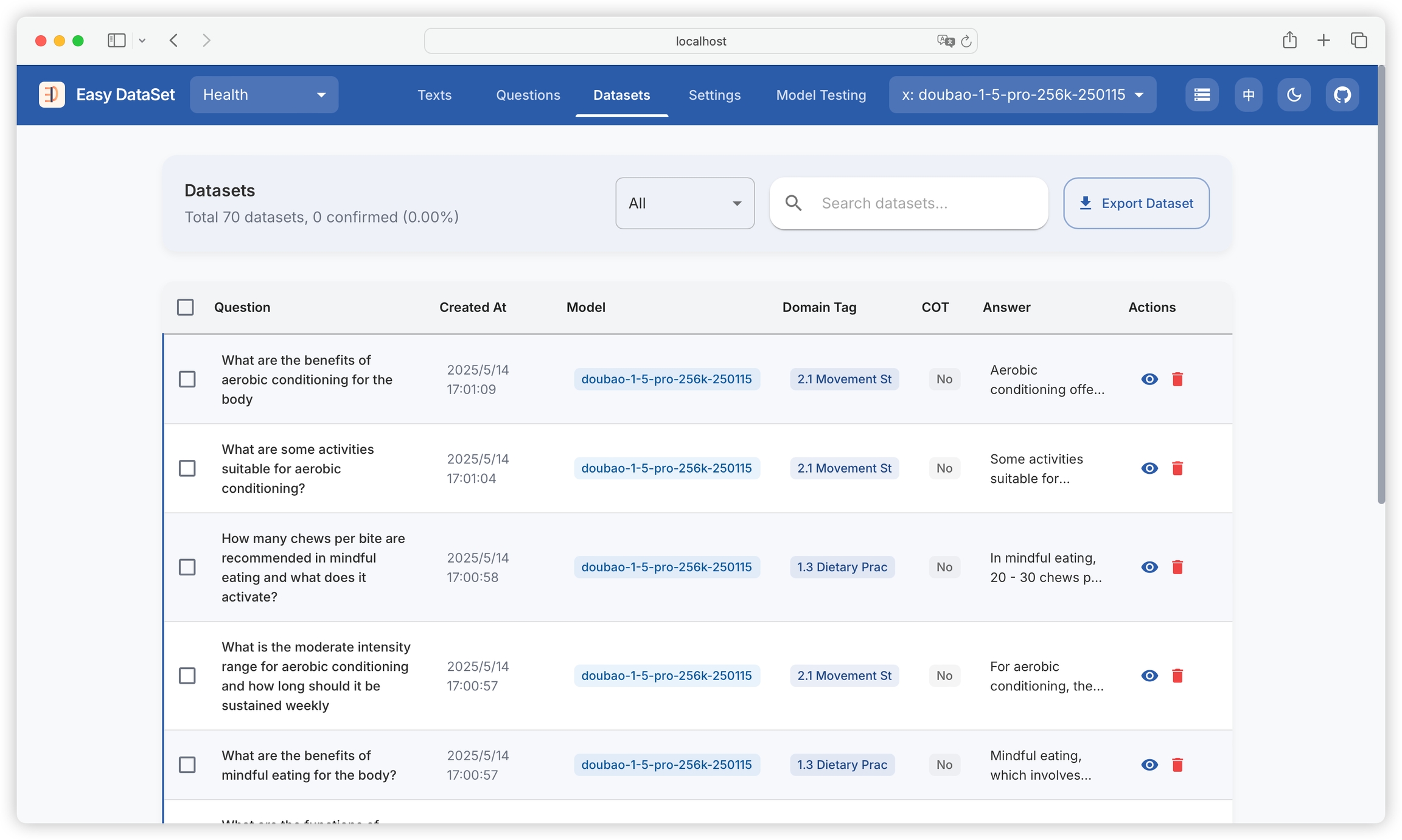
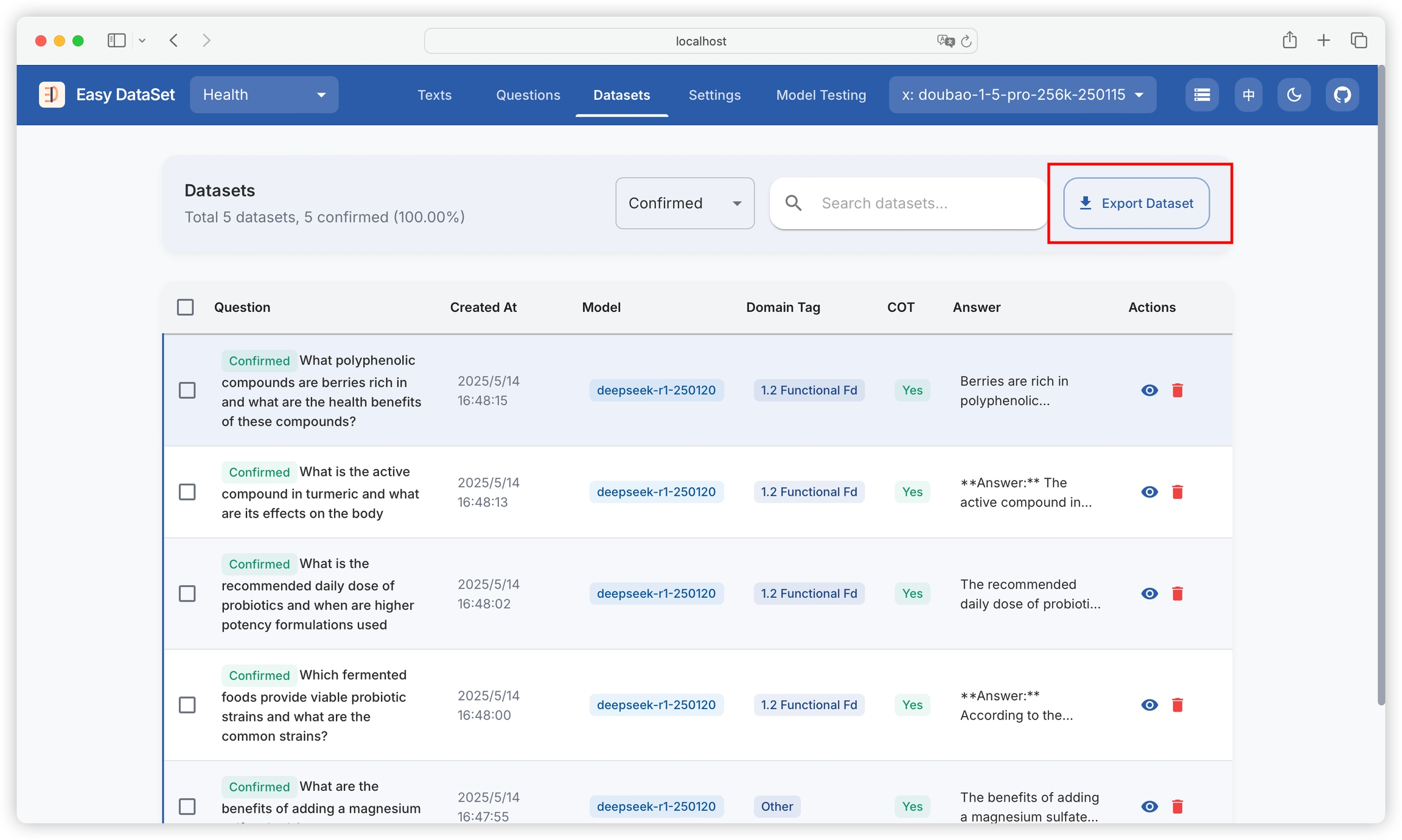
View all generated datasets, including original questions, creation time, models used, domain tags, whether they contain chain of thought (COT), and answer summaries:
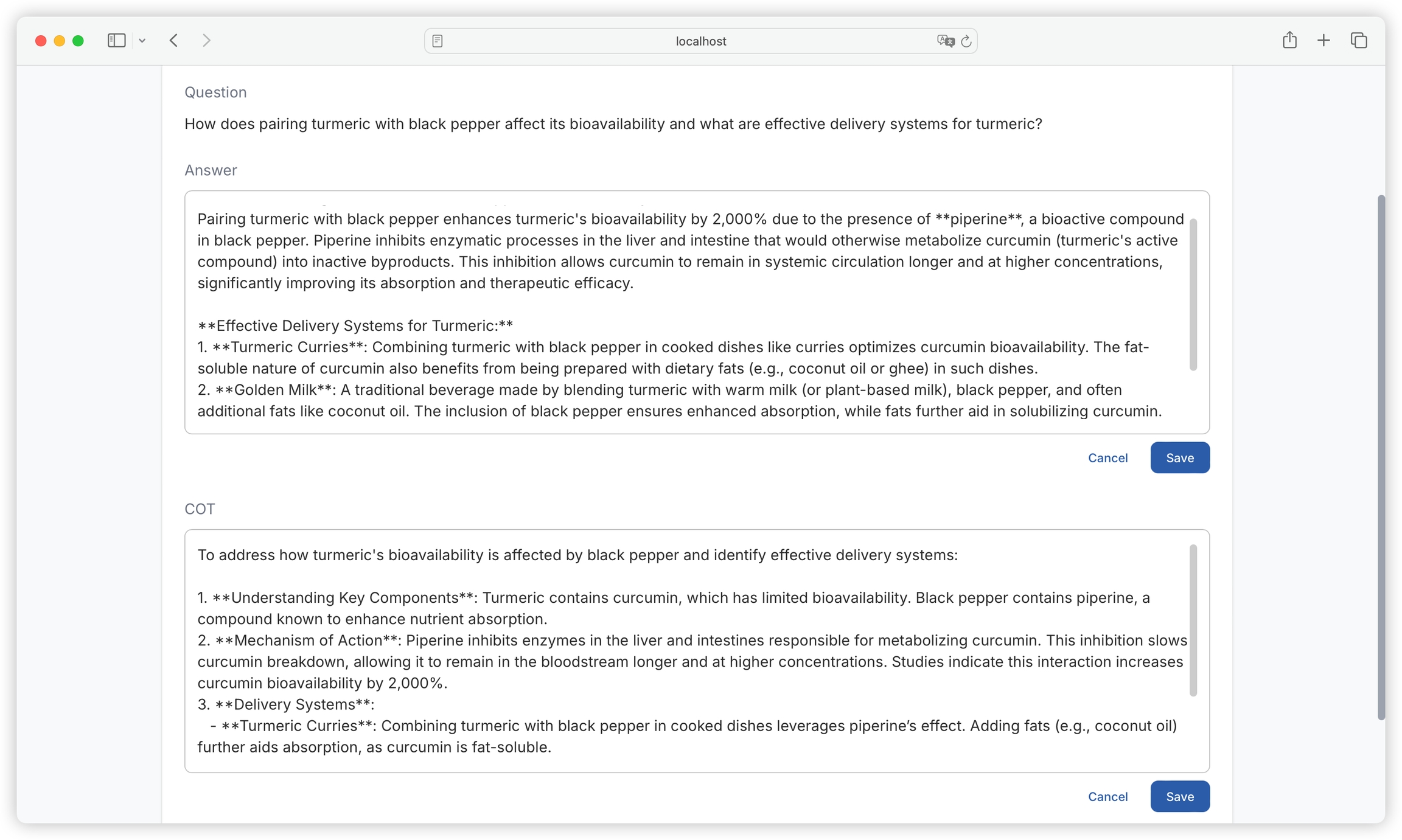
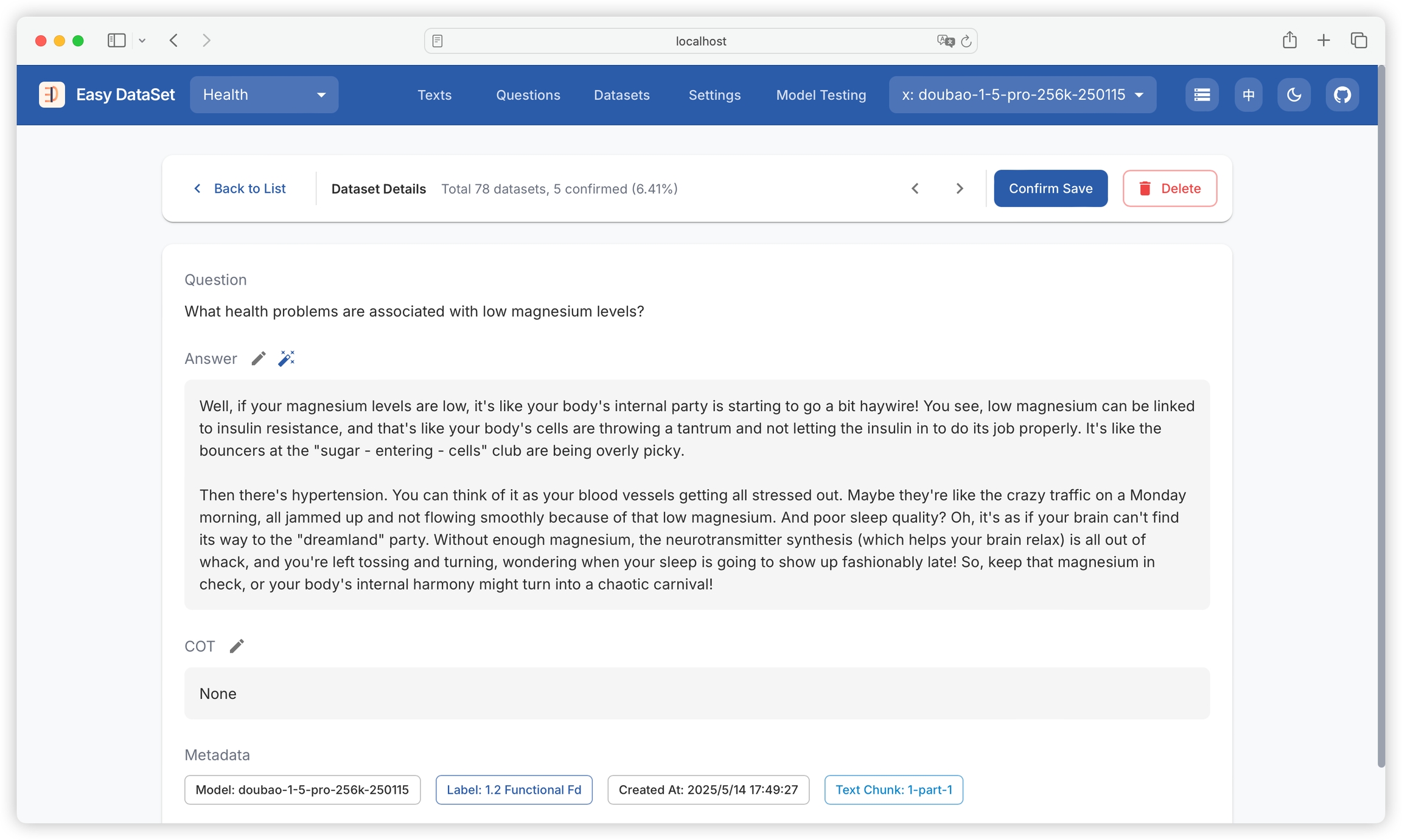
Click on a single dataset to view its details, including question, answer, chain of thought, model used, domain tags, creation time, and text block:
Click on the text block name to view the original text block details, making it convenient to compare the original content with the answer:
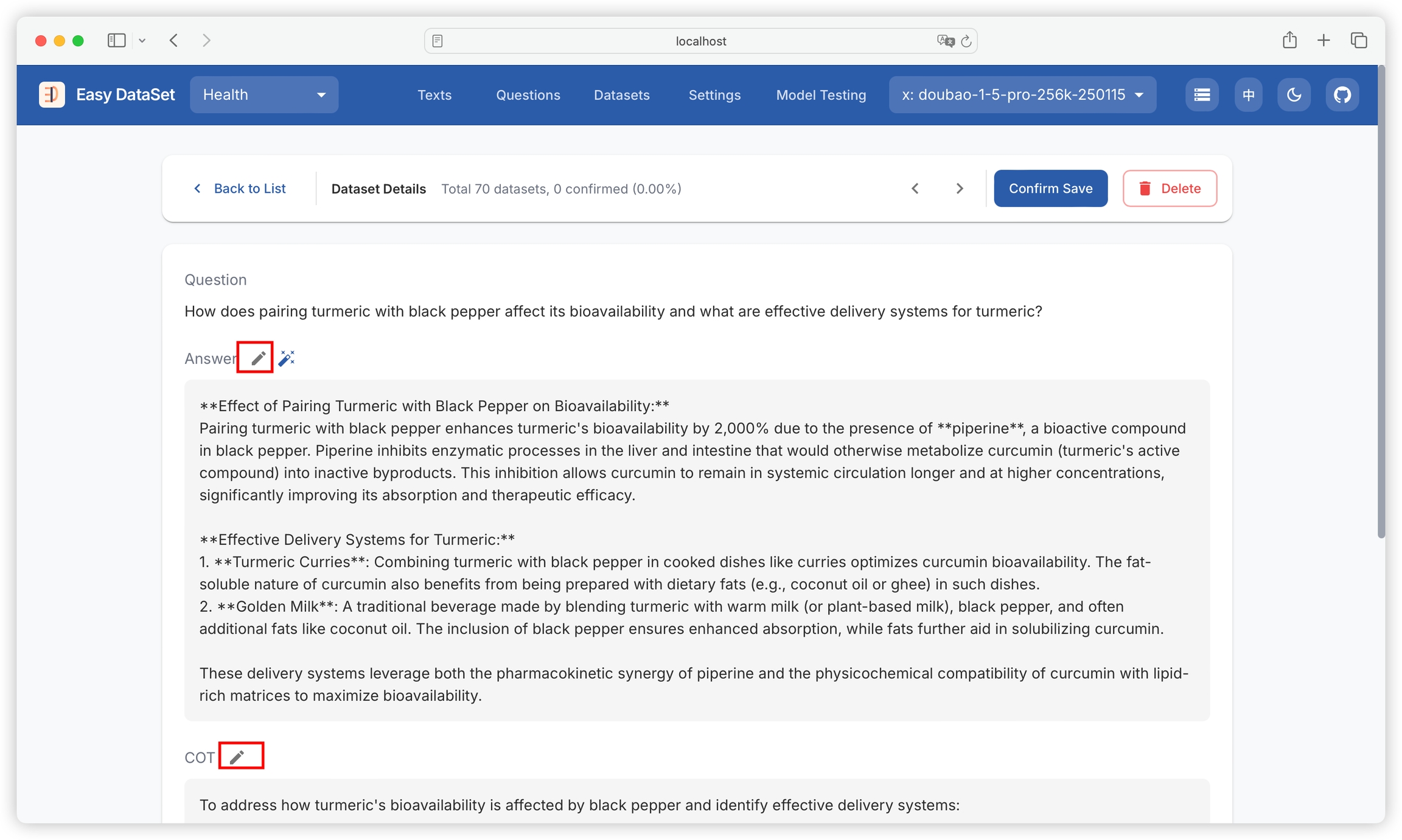
If you are not satisfied with the generated answer or chain of thought, you can click the edit button to modify manually:
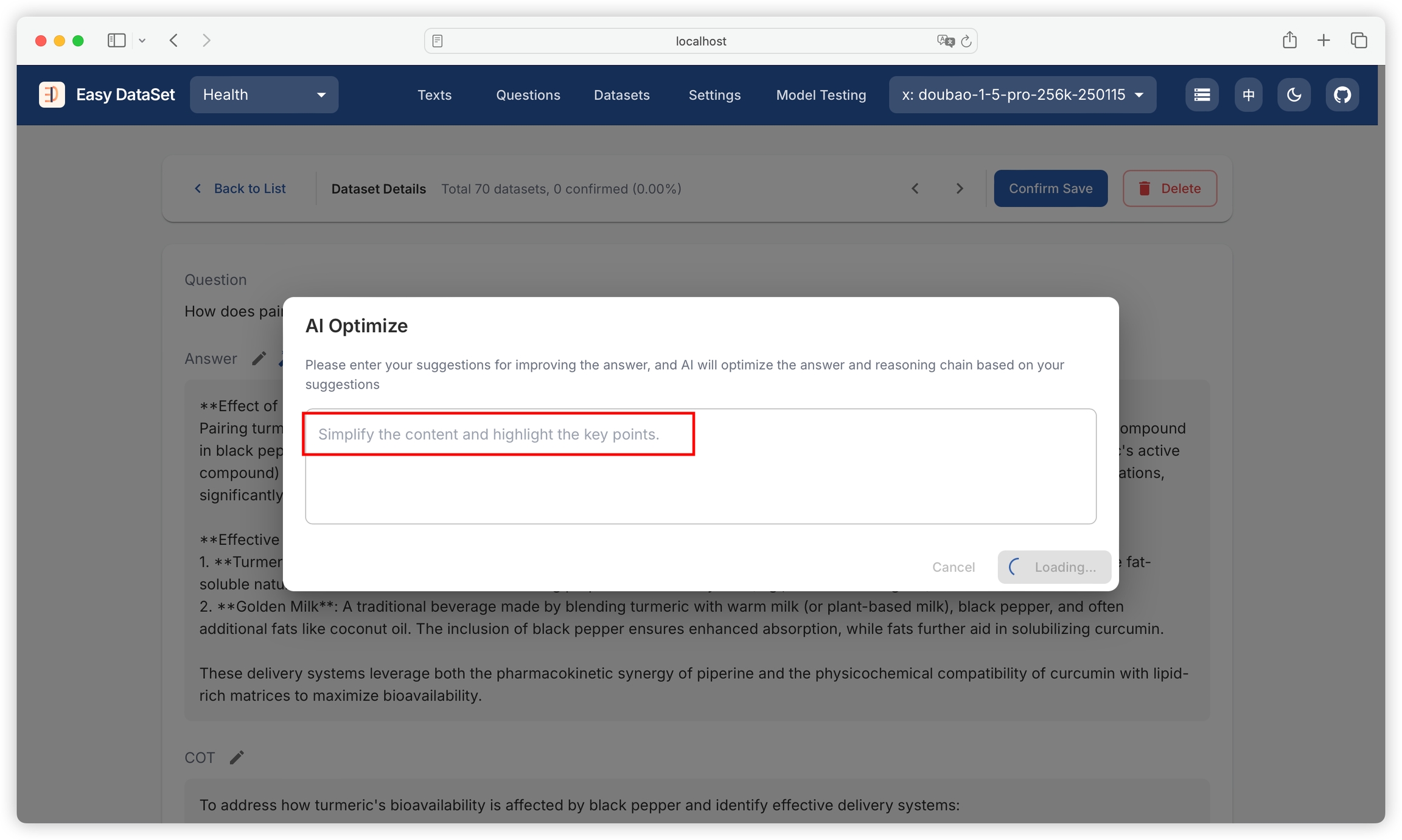
Click the magic wand icon to provide optimization suggestions to AI and optimize based on AI:
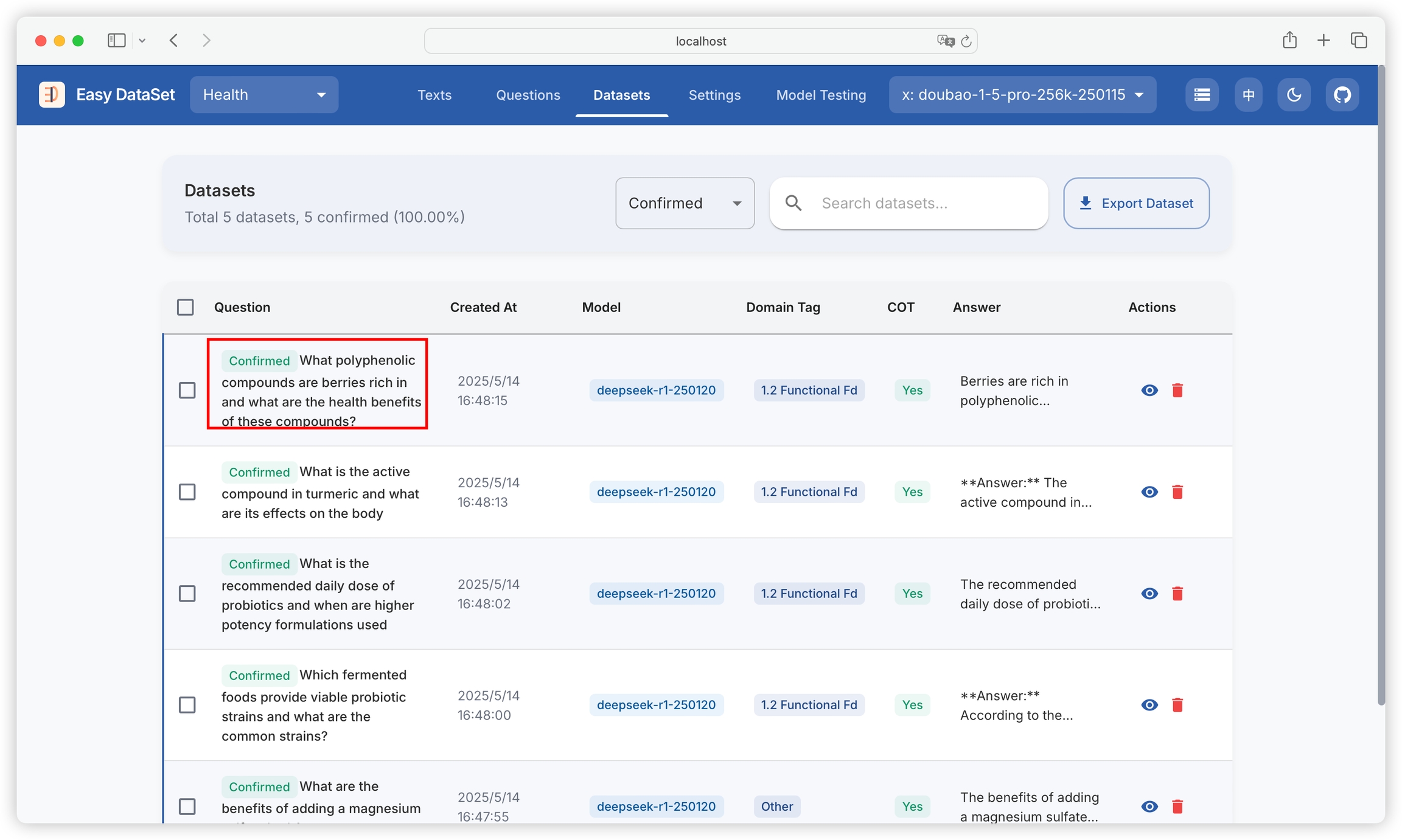
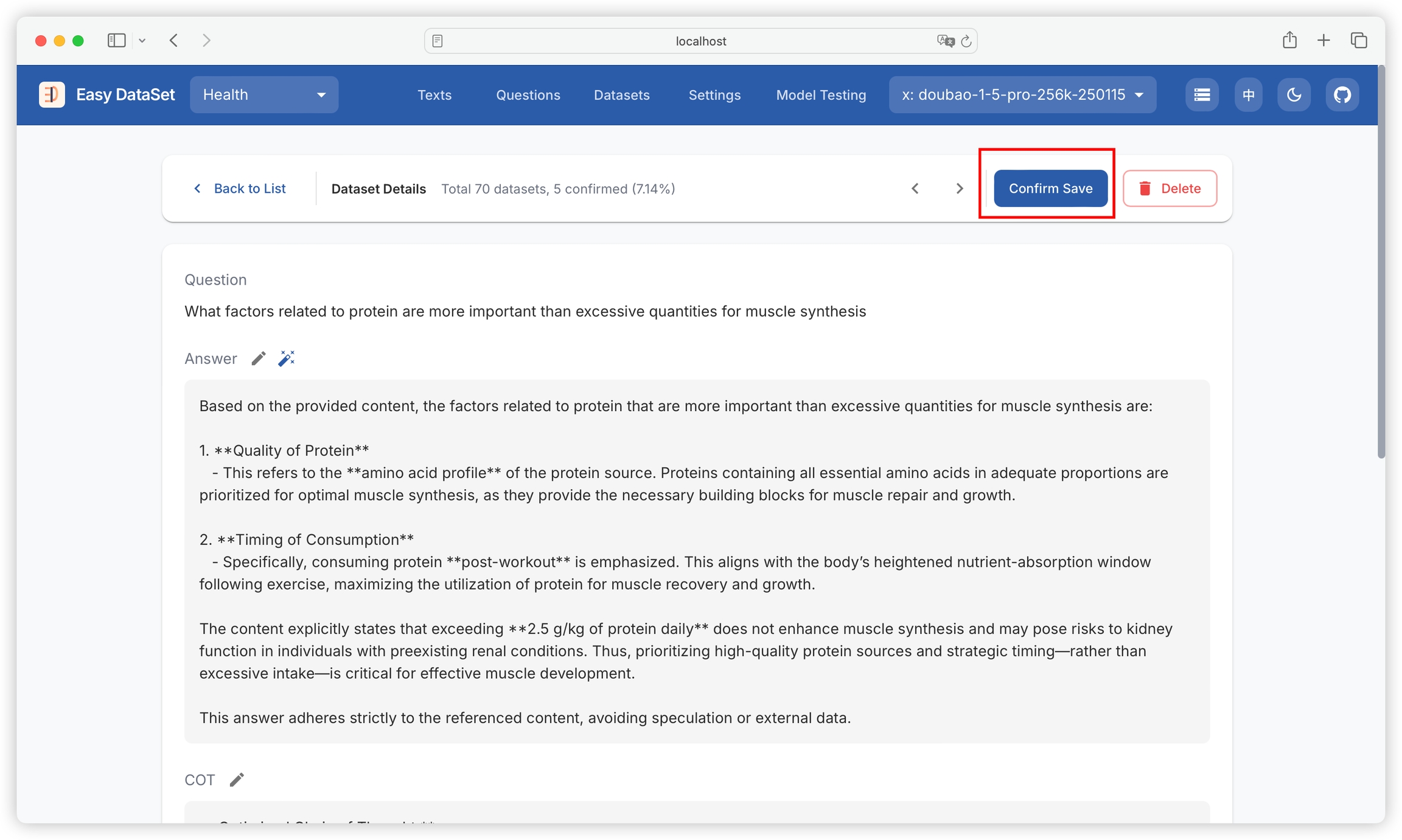
If you confirm that the dataset has no issues, you can click to confirm and keep it:
Confirmed datasets will be labeled:
Note: Confirming datasets is not a mandatory operation. It is only used for the platform to record confirmed status and does not affect subsequent export (unconfirmed datasets can also be exported).
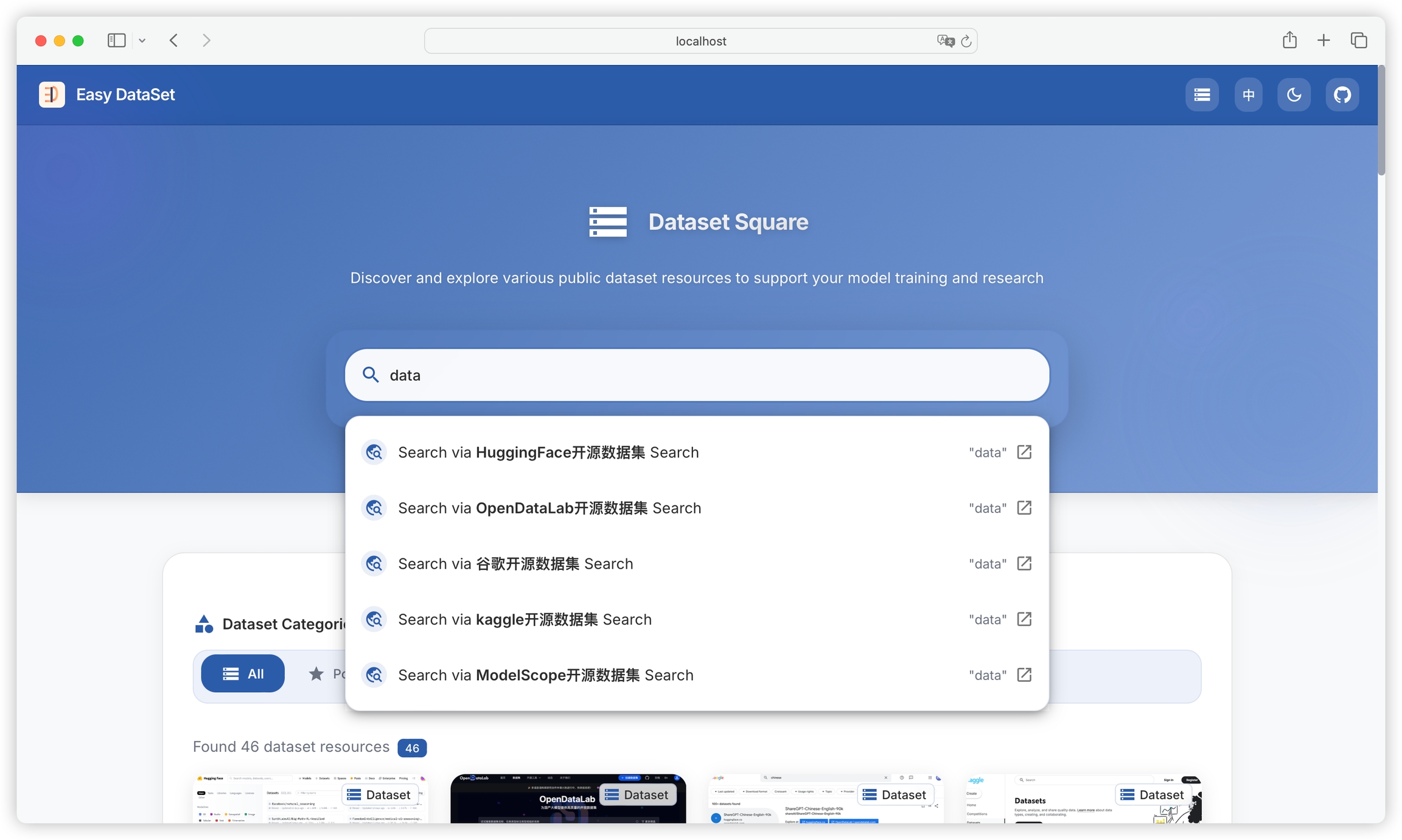
Supports one-click multi-platform search:
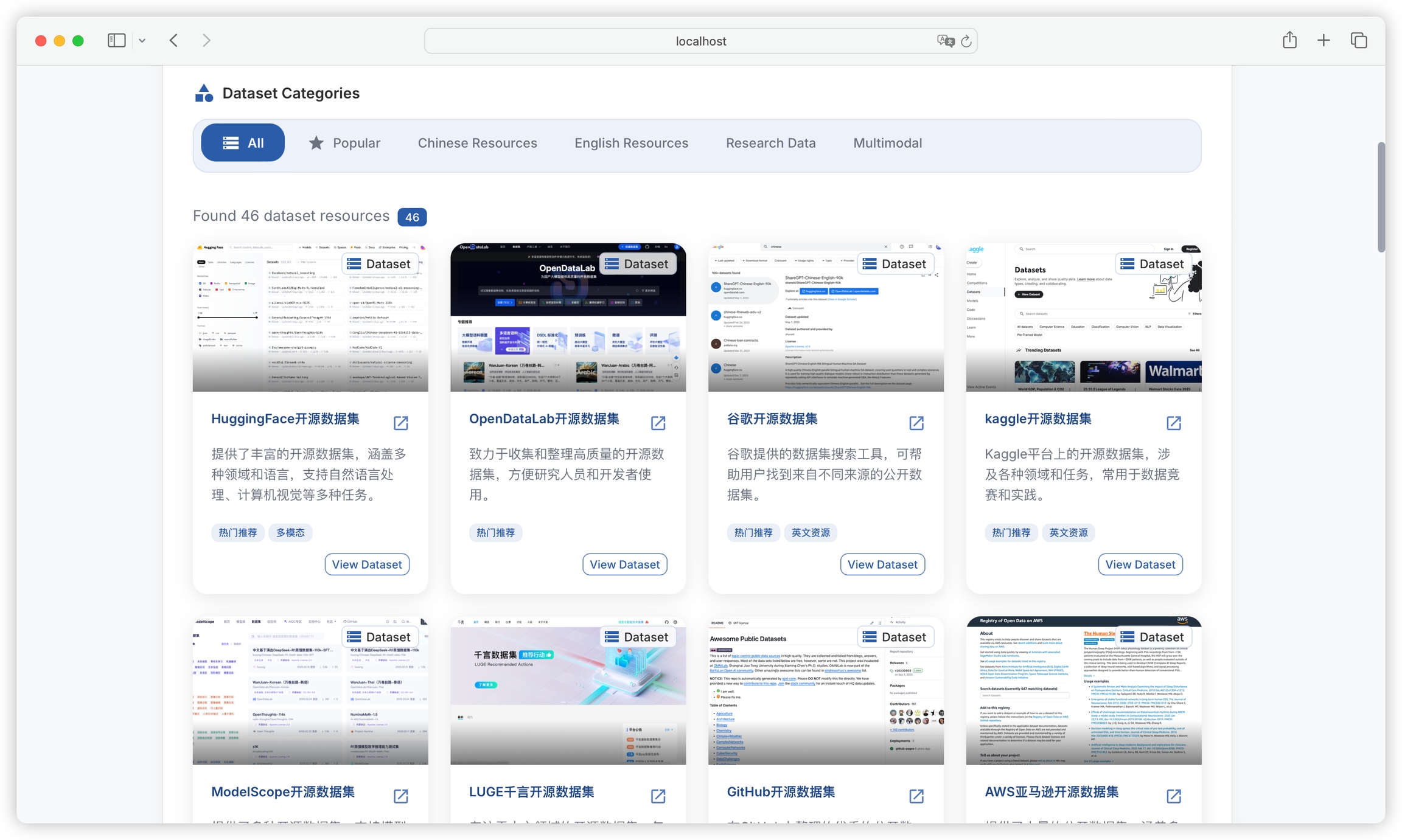
Built-in multiple platforms for publicly accessible datasets:
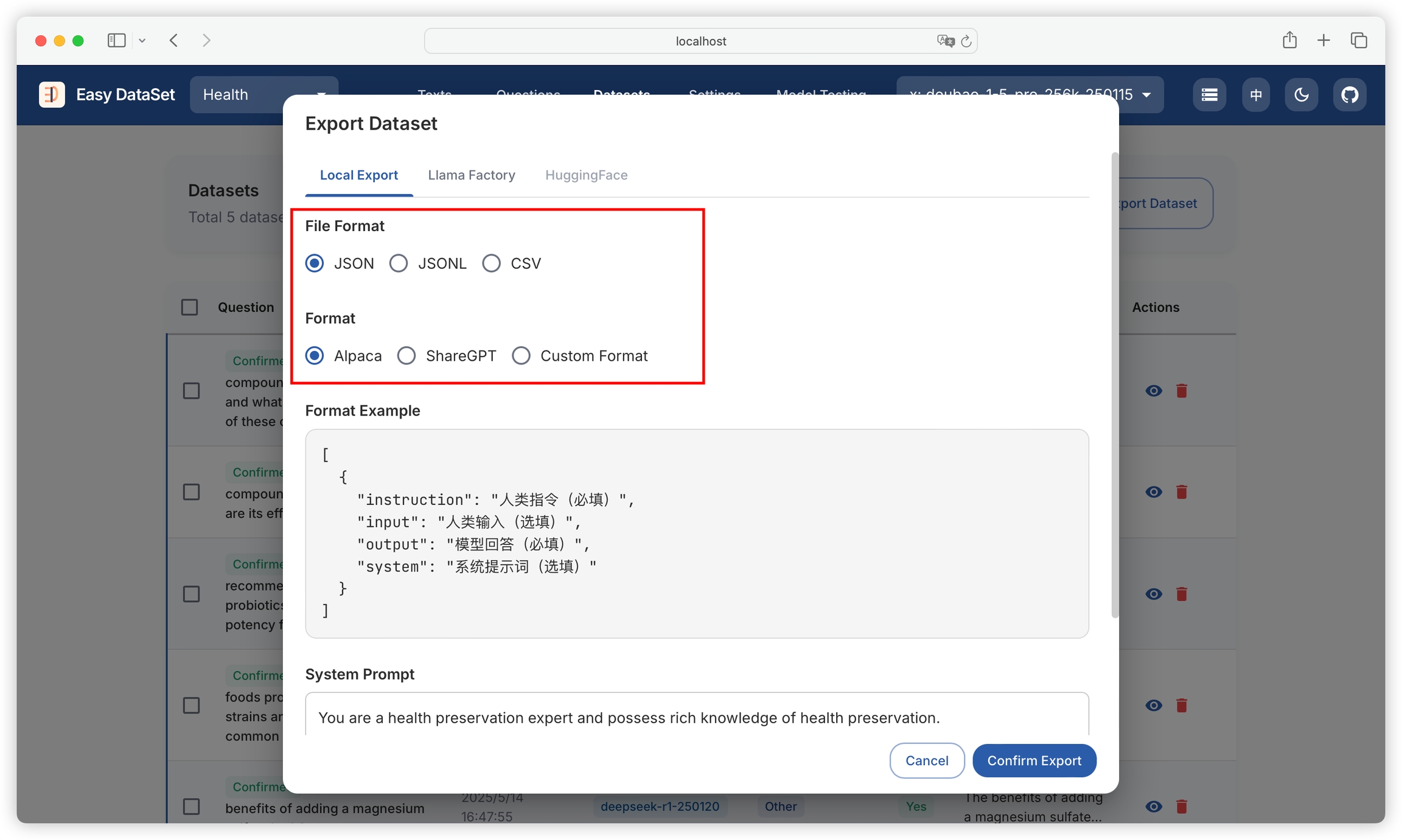
Select file format: Supports three formats - JSON, JSONL, Excel
Select dataset style: Fixed styles support Alpaca, ShareGPT
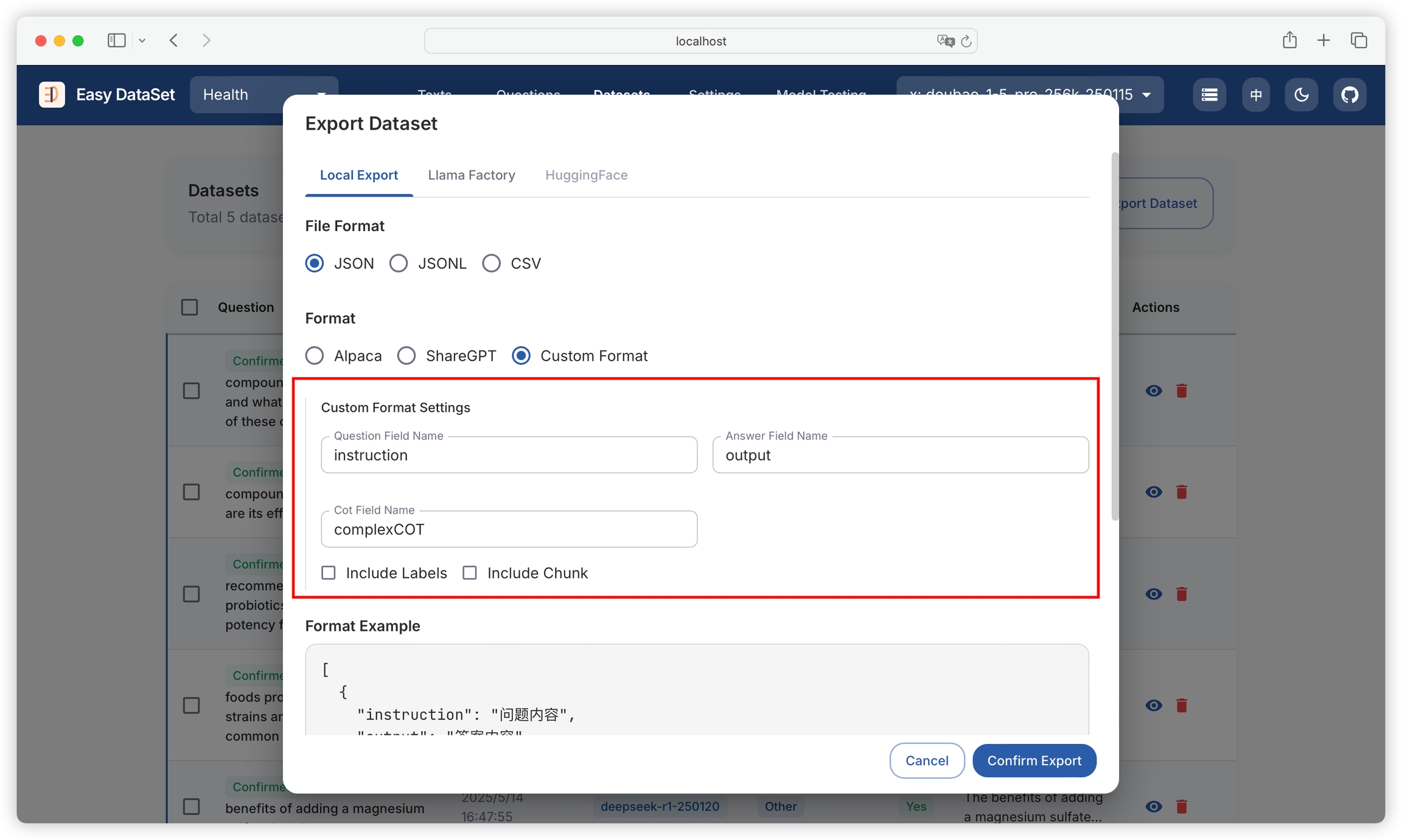
Supports custom styles, allowing configuration of field formats for questions, answers, chain of thought, and whether to include domain tags:
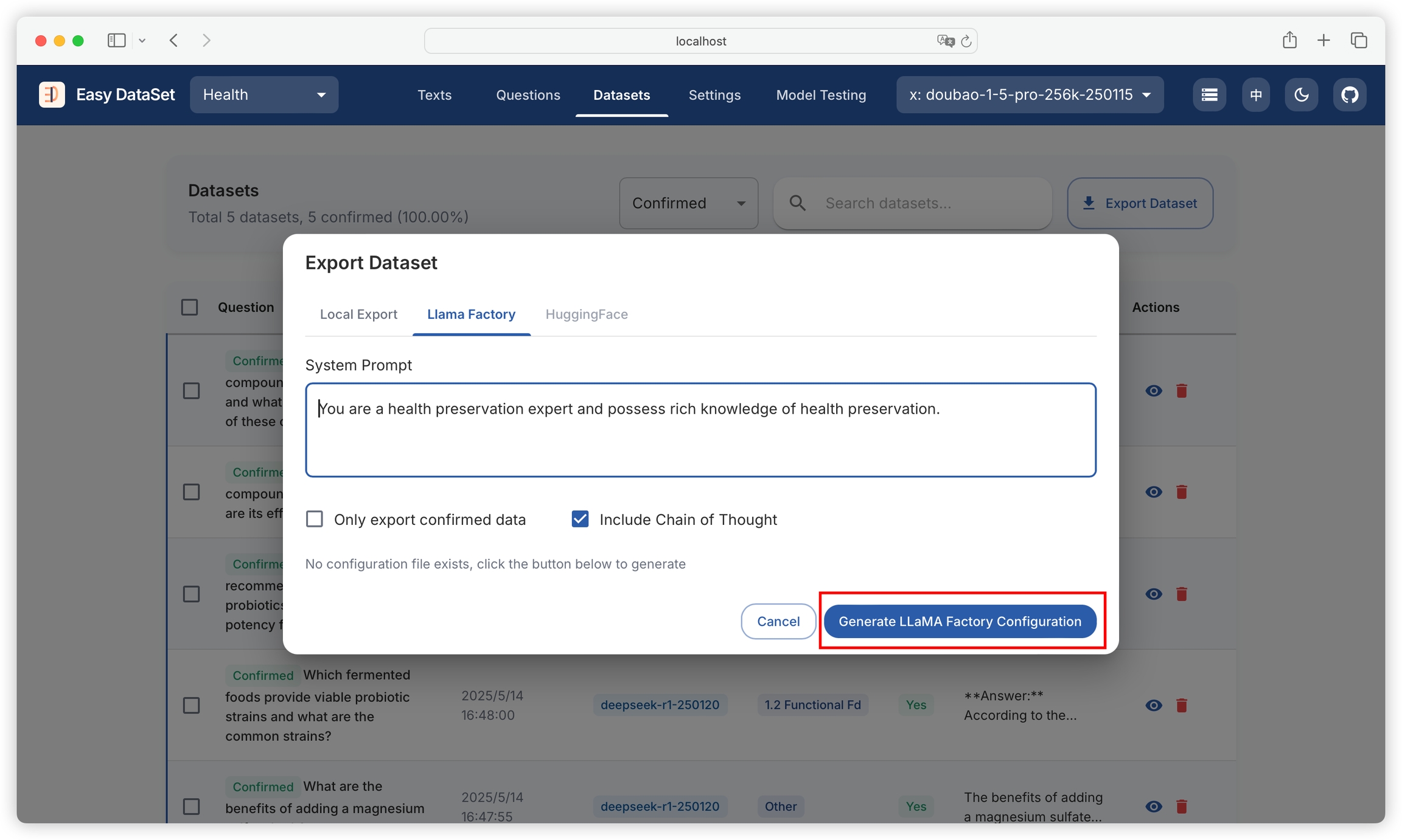
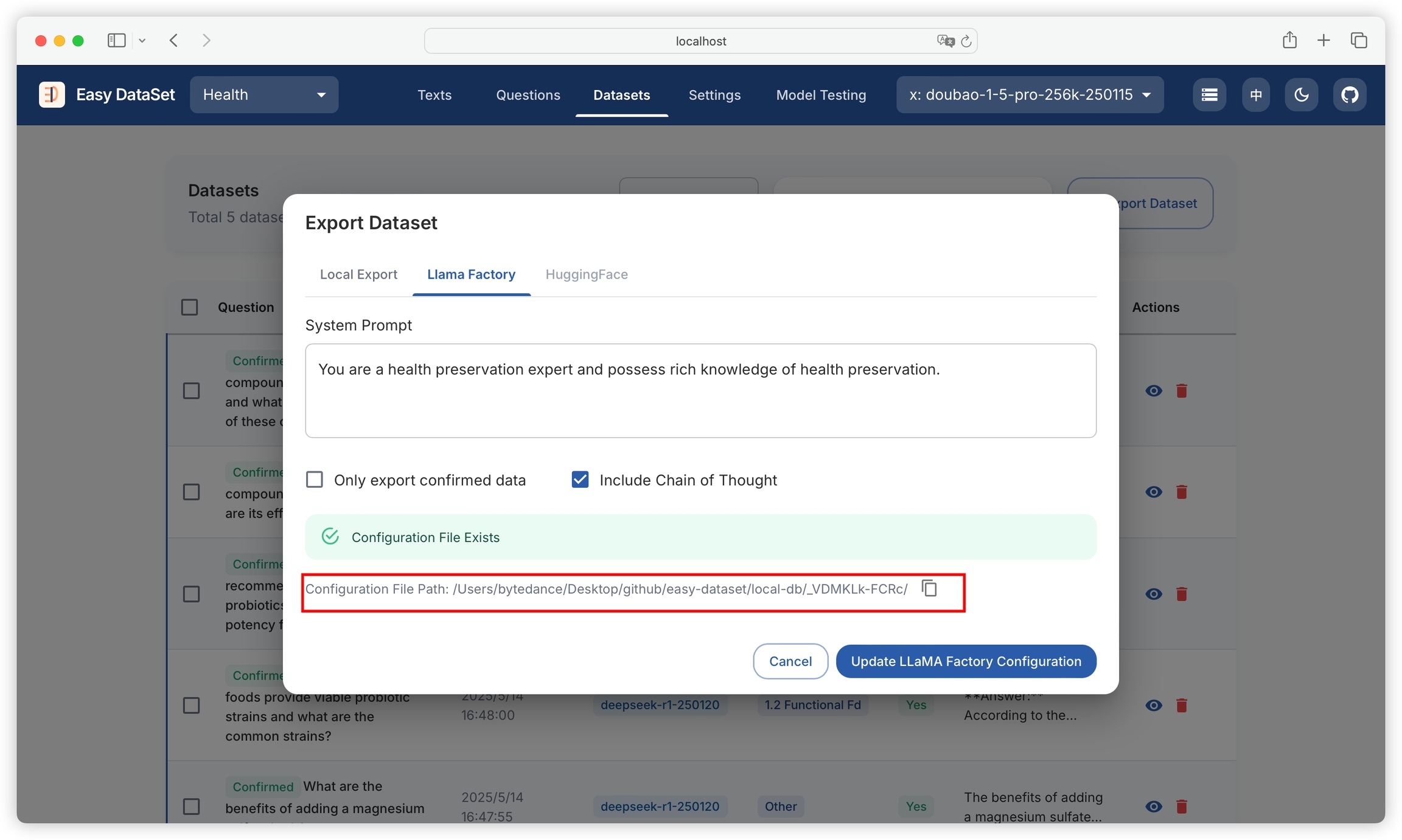
After generation, click to copy the configuration file path with one click:
Then paste the path into LLaMA Factory:
Click Preview Dataset, if the dataset can be loaded, it indicates the configuration is successful:\
In Easy Dataset, you can customize different chunking strategies for literature processing through "Settings - Task Settings - Chunking Settings".
The purpose of text chunking is to split documents into small segments, making it easier for subsequent applications to use. Through chunking, we can:
Solve the problem of inconsistent document lengths: In real document libraries, text lengths vary. Splitting ensures that all documents can be processed in the same way.
Break through model limitations: Many models have a maximum input length limit. After splitting documents, those that were too long to use can now be processed.
Improve representation quality: For long documents, extracting too much information at once may reduce quality. Splitting allows each chunk to be more precise and targeted.
Increase retrieval accuracy: In information retrieval systems, splitting documents enables more granular search results, allowing queries to match relevant parts of documents more accurately.
Optimize use of computing resources: Processing small text chunks saves memory and allows for more efficient parallel task processing.
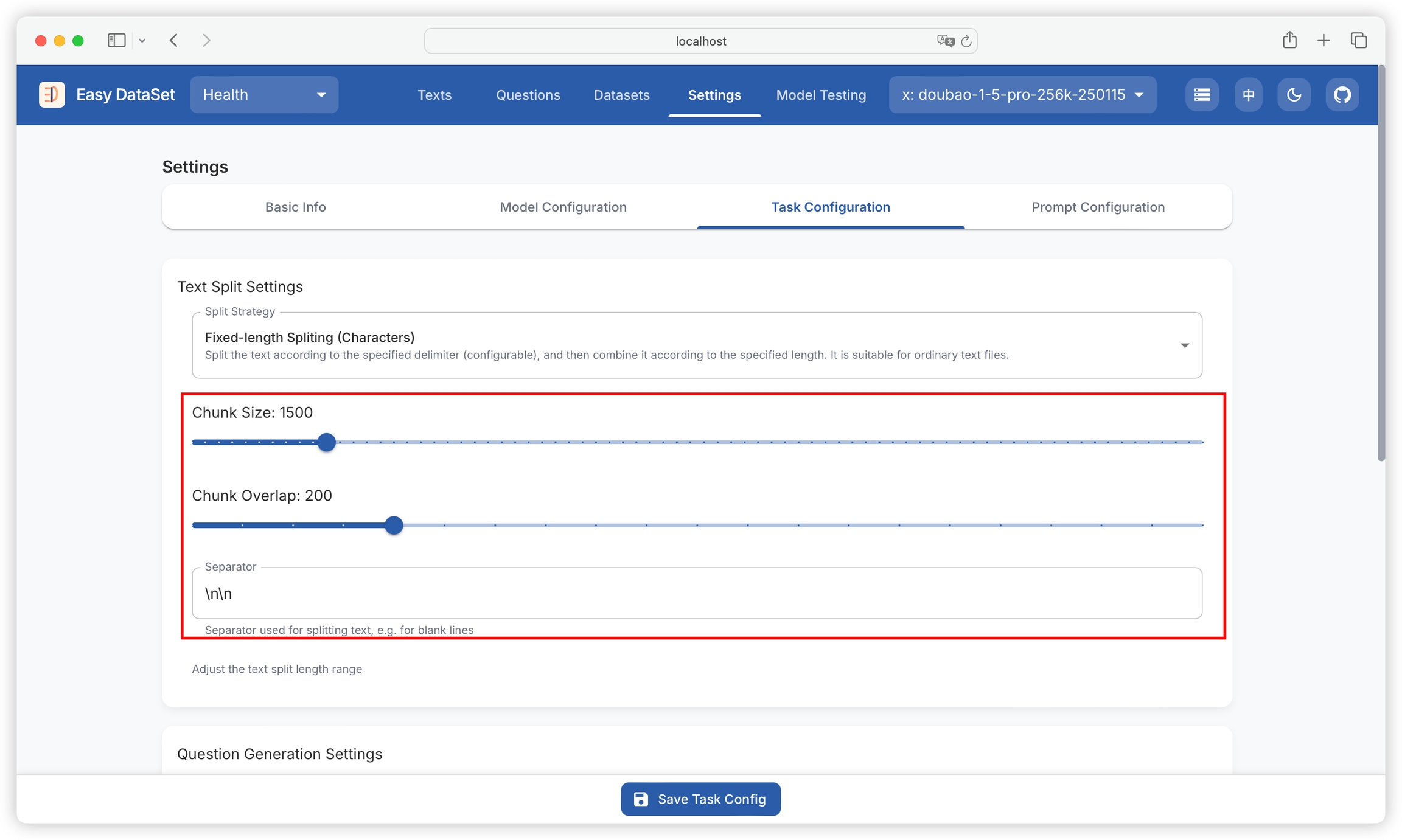
The simplest and most intuitive splitting strategy is to divide by document length. This method is simple and effective, ensuring that each chunk does not exceed the set maximum length. The advantages of length-based splitting include being easy to implement and understand, producing chunks of relatively consistent length, and being easily adjustable for different model requirements. Length-based splitting can be further divided into:
Token-based splitting: Split text according to the number of tokens, which is very useful when working with language models.
Character-based splitting: Split text based on the number of characters, which maintains good consistency across different types of text.
When using fixed-length chunking, you can configure:
separator: "\n\n": Specifies the boundary marker for splitting text. By default, two consecutive line breaks (\n) are used as the separator. This means the text will be split at every blank line, breaking the original content into independent paragraph chunks. For example, an article with multiple blank lines will be split into several subtexts by paragraph. Adjusting the separator (such as changing to "\n" or "---") allows flexible control over the granularity of splitting, suitable for different text formats (such as code, Markdown documents, etc.).
chunkSize: 1000: Defines the maximum character length for each chunk. After splitting by the separator, if a chunk exceeds this value, it will be further divided into smaller chunks, ensuring all chunks do not exceed the specified size. For example, a paragraph with 3000 characters will be split into up to 3 chunks (each ≤1000 characters). This parameter directly affects the granularity of subsequent processing: smaller values generate more, finer chunks suitable for scenarios requiring precise context; larger values reduce the number of chunks, retaining more complete semantic units.
chunkOverlap: 200: Controls the number of overlapping characters between adjacent chunks. At the end of each chunk, a specified number of characters are retained as an overlap with the next chunk. For example, when chunkOverlap: 200, the last 200 characters of the previous chunk will be repeated at the beginning of the next chunk. This design ensures semantic continuity, preventing key information from being lost due to splitting, which is especially important for context-dependent tasks (such as retrieval and Q&A). The overlap area acts as a transition buffer, helping the model access the context of adjacent content when processing a single chunk.
Text is naturally organized into hierarchical structures such as paragraphs, sentences, and words. We can leverage this inherent structure to formulate splitting strategies, ensuring that the chunked text maintains the fluency of natural language, semantic coherence within the chunk, and adapts to different levels of text granularity. The splitter will first try to keep larger units (such as paragraphs) intact. If a unit exceeds the chunk size limit, it will move to the next level (such as sentences). If necessary, this process will continue down to the word level.
Recursive text structure chunking also supports configuring the maximum chunk size, overlap characters, and multiple custom separators:
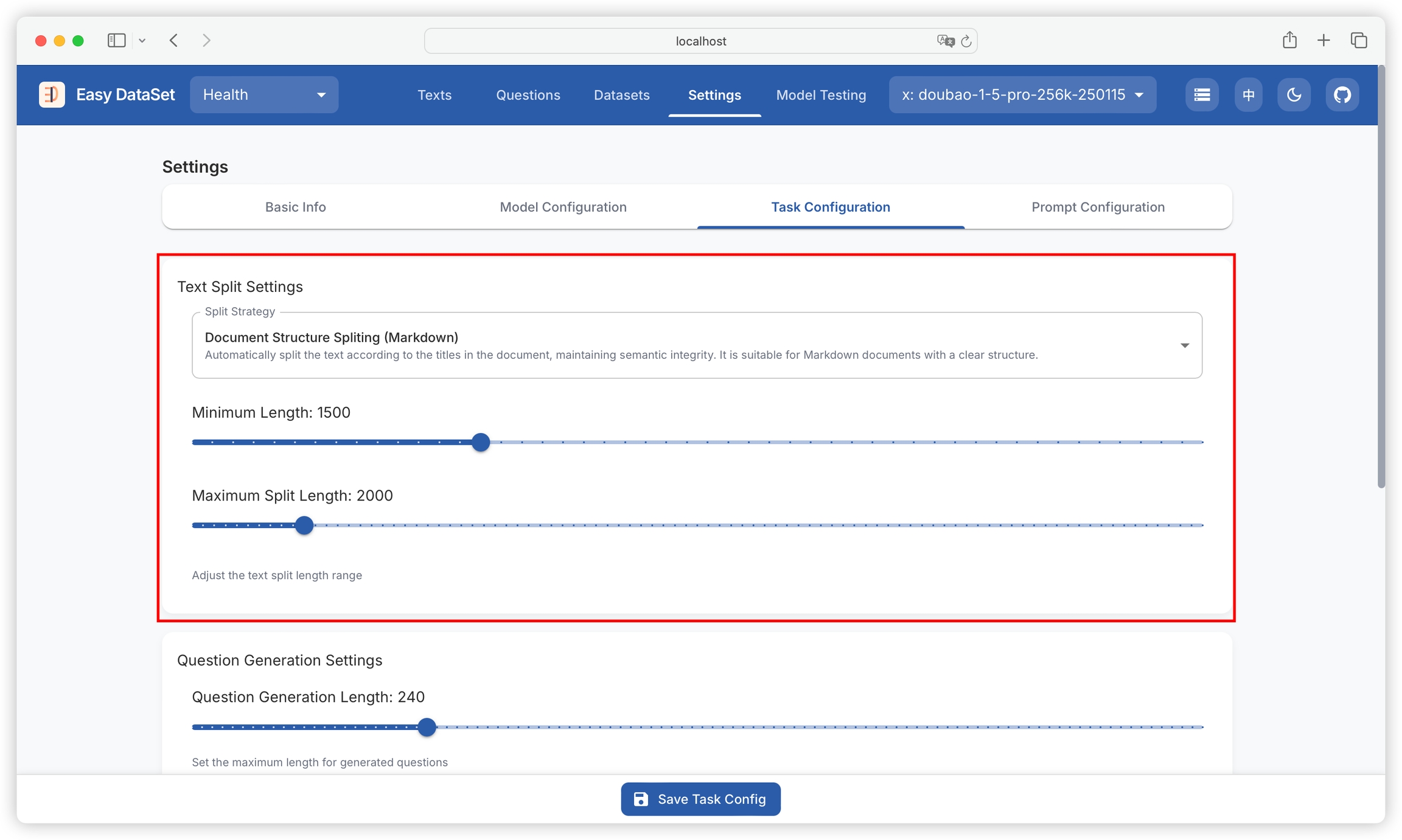
Markdown-based document structure chunking is the platform's default chunking strategy:
First, you need to set the minimum and maximum split lengths for the text block;
Then, automatically identify chapters (such as #, ##, ### in Markdown);
Count the number of words in the identified chapters, and split them into segments when the length is between the minimum and maximum split lengths;
When encountering overly long paragraphs (exceeding the maximum split length), recursively split the paragraphs to ensure semantic integrity.
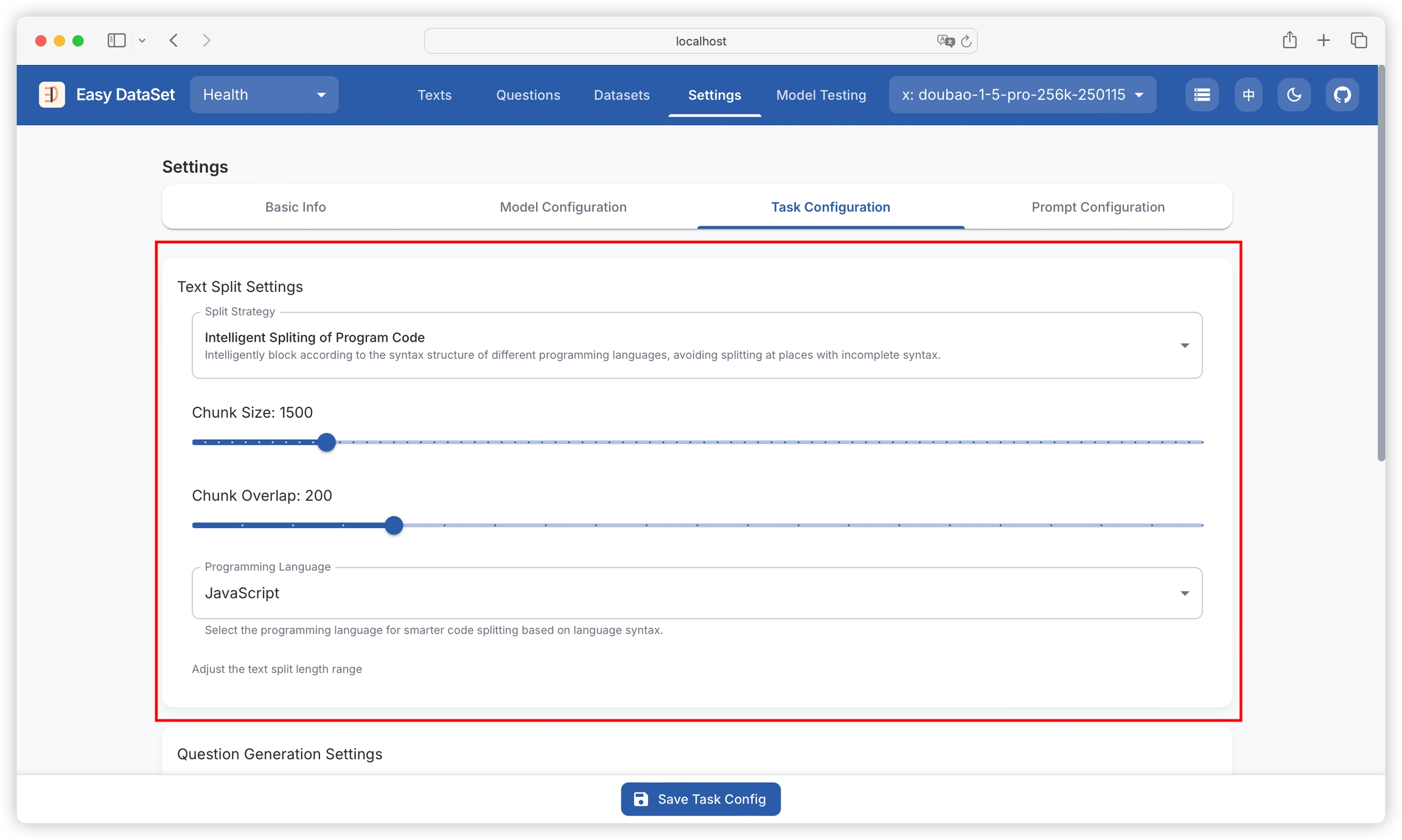
When the target text contains a large amount of code, traditional splitting methods are not applicable, and may cause code fragmentation. Easy Dataset also provides a splitting method based on intelligent code semantic understanding, which can choose the target language for chunking:
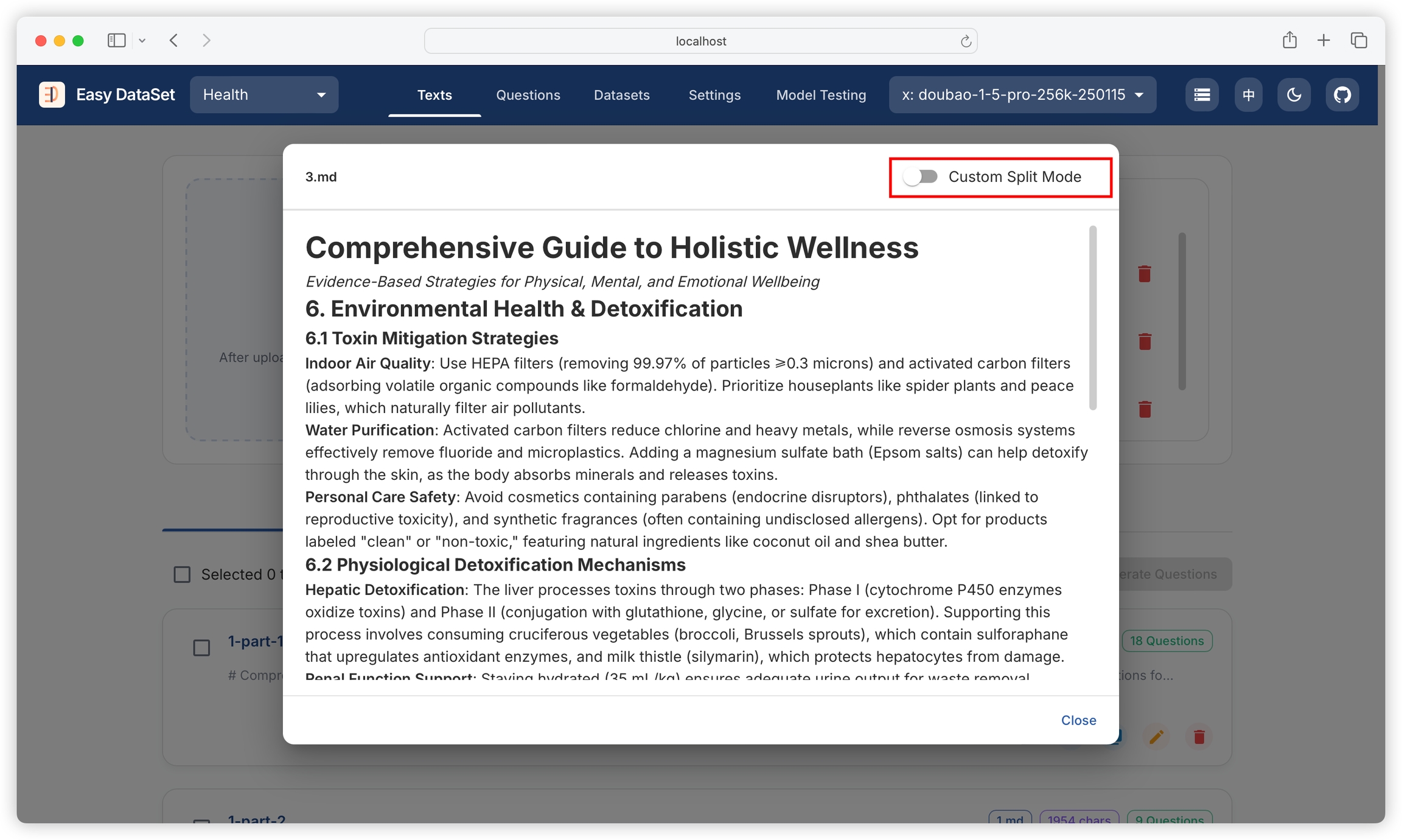
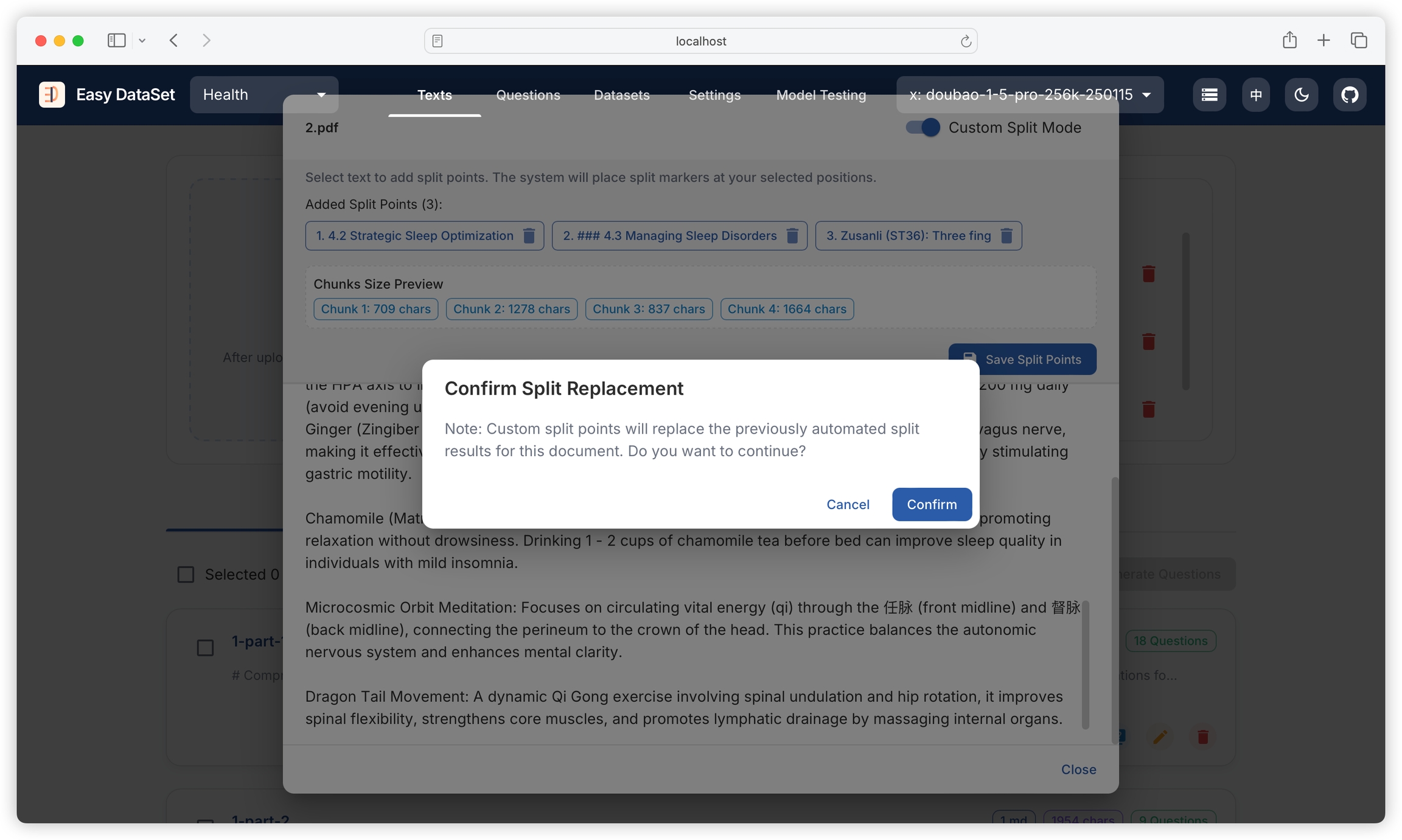
When the above chunking strategies cannot meet your needs, you can choose to use the visual custom chunking function. First, find the literature to be chunked and click to view details:
After opening the file preview view, click the top right corner to enable custom chunking mode:
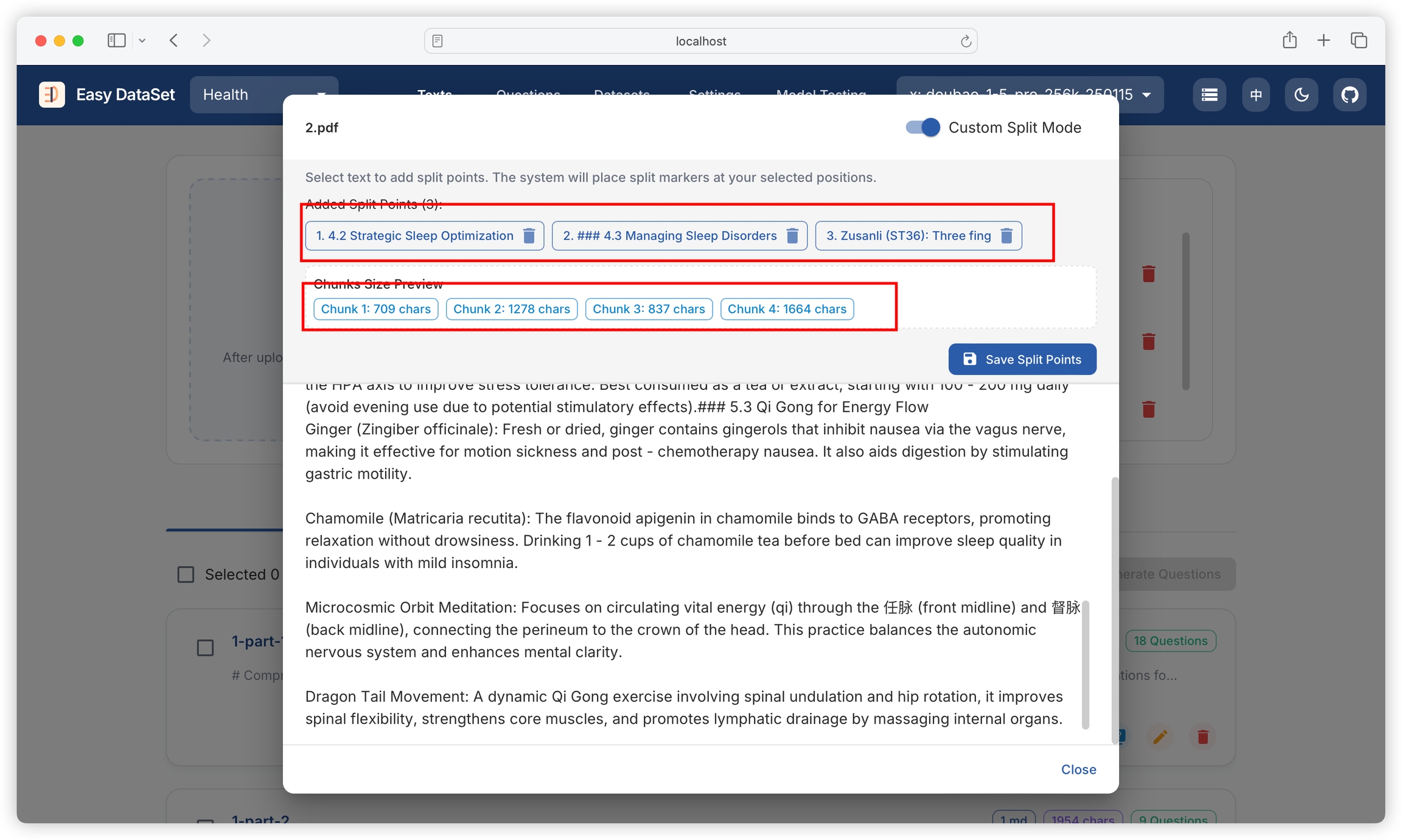
Select the text at the position where you need to chunk:
The top will display the current chunking position, chunk count, and character count for each chunk:
Click to save the chunk:
After saving, it will completely replace the current literature's historical chunking content:
For example, in the custom prompts below, we:
Use custom global prompts to require the use of English
Use custom question generation prompts to require questions to be concise
Use custom answer generation prompts to require answers to be humorous and witty
The final effect after intervention:
Click on the magic wand 🪄 icon on a single question to generate an answer (construct a dataset) for that question:
After generating an answer for the question, the number of answers already generated will be displayed on the right side (a single question can generate multiple answers):
When a reasoning model is selected in the upper right corner, the chain of thought (COT) in the model's reasoning process will be preserved:
You can filter questions with generated answers and questions without generated answers:
You can multi-select or select all questions to batch produce answers:
You can view the progress of batch tasks:
The number of concurrent tasks in Task Settings - Question Generation Settings can still control the maximum number of concurrent tasks for batch dataset generation:
This update makes significant optimizations to the storage method, reconstructing local file storage as local database storage, greatly improving the user experience for large amounts of data. Due to the large changes made, a beta version is released for everyone to experience. If you encounter any issues while using this version, please submit feedback through Issues to help us further improve the product.
🔧 Fixes
Fixed the issue of unexpectedly generating COT during dataset optimization
Fixed the issue of processing removed files on the text processing page, causing errors
⚡ Optimizations
Reconstructed local file storage as local database storage, greatly optimizing the user experience for large amounts of data
Randomly removed question marks from problems (configurable)
Optimized multiple functional experiences
✨ New Features
Added local log storage to the client, allowing users to open the log directory to troubleshoot issues
Added a cache clearing function to the client, allowing users to clear historical log files and backed-up database files
🔧 Fixes
Fixed the issue of the model configuration error on the first configuration
Fixed the issue of Docker image packaging errors
⚡ Optimizations
Used the OPEN AI SDK to reconstruct the model interaction interface, improving compatibility
✨ New Features
Supported visual model configuration
Supported using custom visual models to parse PDFs, with higher accuracy
Model testing supported sending images to test visual models
Dataset details page supported viewing belonging text blocks
Supported users editing text blocks themselves
Supported downloading and previewing parsed Markdown files
⚡ Optimizations
Enhanced the default maximum output token limit of the model
Removed the update failure pop-up window
Removed some interfering error log outputs
✨ New Features
Supported one-click opening of the client data directory
Supported model temperature and maximum generated token number configuration
Supported two types of PDF file parsing (basic parsing and MinerU parsing)
Supported exporting datasets in CSV format
🔧 Fixes
Fixed the issue of unable to select problems and delete problems failing in the domain tree view
Fixed the issue of the upgrade link to the new version possibly being inaccurate
⚡ Optimizations
Removed extra line breaks from answers and thought chains
Removed the update failure pop-up window and the update download link for the latest installation package
✨ New Features
Literature management supported filtering generated and ungenerated problems
🔧 Fixes
Fixed the issue of inaccurate text block sorting
⚡ Optimizations
Lowered the default concurrency to 3 (solving the problem of triggering some model flow limits)
Optimized problem generation prompts, improving problem generation quality
Lowered the minimum split character number to 100 and raised the maximum split character number to 10000
When the model did not output in the standard format, the log added the original output information
✨ New Features
Supported editing problems and customizing problems
Supported using datasets directly in LLaMa Factory
Supported configuring user-defined prompts
🔧 Fixes
Fixed the issue of extractThinkChain errors
Fixed the issue of NPM dependency deprecation
Fixed the issue of problem filtering and full selection linkage
⚡ Optimizations
Optimized the operation of rebuilding the domain tree after deleting literature when uploading multiple literatures
The client opened by default in maximized mode, no longer full-screen
Optimized the content of thought chains, removing the rhetoric of reference literature
🔧 Fixes
Fixed the issue of the project list being empty due to caching
Fixed the issue of the problem split character number configuration not taking effect
Fixed the issue of some special file names causing errors
Fixed the issue of some loading states being invalid
⚡ Optimizations
The client opened external links by default, jumping to the browser
Continued to optimize the success rate of dataset result generation
Optimized the performance of displaying domain trees for a large number of problems
✨ New Features
New projects could choose to reuse model configurations from other projects
Single projects supported uploading multiple files (shared domain trees)
Problem management added filtering for generated and ungenerated datasets
Supported uploading docx type files
Imagine a "professor" (large model) who is highly knowledgeable but "temperamental": training them requires a huge tuition fee (high training cost), inviting them to give lectures requires a luxurious classroom (high-performance hardware), and each lecture costs a fortune (high inference cost). On the other hand, the "elementary student" (small model) is well-behaved and lightweight (low deployment cost) but has limited knowledge.
Model distillation is the process of having the professor "condense" their problem-solving approach into a "cheat sheet" to teach the student.
The professor doesn't just say "choose A for this question," but provides a probability distribution (e.g., 80% for option A, 20% for option B). This "soft answer" contains their reasoning logic.
By imitating the professor's approach, the student can learn the core knowledge without incurring high costs, much like using a "problem-solving cheat sheet" to quickly grasp the key points.
Simply put: Extract the original dataset and reasoning process from a large model, then fine-tune a smaller model.
While large models are powerful, they face two major challenges in practical applications:
High Computational Requirements: Training a model with hundreds of billions of parameters can cost millions of dollars, making it unaffordable for most companies and individuals.
Deployment Difficulties: Large models require dozens of GBs of memory to run, which exceeds the capacity of ordinary personal devices.
Core Value of Distillation: While individuals and small businesses may not have the resources to deploy large-parameter models, they can distill smaller models for specific domains from large models. This significantly reduces deployment costs while maintaining performance in the target domain.
DeepSeek's series of open-source distilled models:
The paper "s1: Simple test-time scaling" by Fei-Fei Li's team mentioned that for just $50, they trained a model comparable to ChatGPT o1 and DeepSeek R1. This was achieved by fine-tuning the open-source model Qwen2.5-32B from Tongyi, using a dataset partially distilled from Google Gemini 2.0 Flash Thinking.
The creation of this model involved first using knowledge distillation to obtain reasoning trajectories and answers from the Gemini API, which helped filter out 1,000 high-quality data samples. This dataset was then used to fine-tune the Tongyi Qwen2.5-32B model, ultimately resulting in the well-performing s1 model.
Distillation
Small model imitates the problem-solving approach of large models
Lightweight deployment (mobile devices, enterprise private clouds)
Fine-tuning
"Tutoring" the model with specific data (e.g., medical data)
Vertical domain customization (e.g., legal, medical Q&A)
RAG
Model "cheats" by calling external knowledge bases
Enterprise document retrieval (e.g., internal training materials)
Prepare the "Cheat Sheet" (Soft Label Generation)
The "professor" first "solves the problems": Input raw data (e.g., "this movie is great") into the large model to generate probability distributions.
Student "Practices" (Model Training)
The small model takes the same data and outputs its own predictions (e.g., "85% positive, 15% negative"), then compares them with the professor's "cheat sheet" to calculate the difference (loss function).
Through repeated parameter adjustments (backpropagation), the small model's answers gradually align with the professor's thinking.
Incorporate "Standard Answers" (Combining Soft and Hard Labels)
The small model needs to learn both the professor's approach (soft labels) and ensure accuracy on basic questions (hard labels, e.g., "a cat is a cat"). The balance between the two is controlled by a coefficient (α) to prevent overfitting.
In the model distillation process, dataset construction is crucial as it directly determines the quality of the distilled model. The following requirements must be met:
Task Scenario Coverage: The dataset should align with the true distribution of the original task (e.g., image classification, natural language processing) to ensure the features learned by both teacher and student models are meaningful.
Diversity and Balance: The data should include sufficient sample diversity (e.g., different categories, noise levels, edge cases) to prevent the distilled model from having poor generalization due to data bias.
To meet these requirements, we cannot simply extract datasets randomly for specific domains. The approach in Easy Dataset is as follows:
First, we use the top-level topic (defaulting to the project name) to construct a multi-level domain label hierarchy, forming a complete domain tree. Then, we use the "student model" to extract questions from the leaf nodes of this domain tree. Finally, we use the "teacher model" to generate answers and reasoning processes for each question.
Let's create a new project for Physical Education and Sports:
Then, we go to the data distillation module and click to generate top-level tags:
This operation allows us to generate N subtopics (tags) from the top-level topic (defaulting to the project name). The number of subtopics can be customized. After the task succeeds, a preview of the tags will be generated in the dialog:
We can click "Add Sub-tag" on each subtopic to continue generating multiple levels of subtopics:
To ensure the relevance of generated subtopics, the complete tag path will be passed when generating multi-level subtopics:
After building the multi-level domain label tree, we can start extracting questions from the leaf tags:
We can choose the number of questions to generate. Additionally, the complete domain label path will be passed when extracting questions:
After generation is complete, we can preview the questions:
We can see the generated questions from the leaf nodes of the domain tree:
Then, we can click to generate answers for each question:
We can also go to the question management module to batch generate answers for the generated questions (distilled questions will be displayed as "Distilled Content" by default since they are not associated with text chunks):
If you don't need fine-grained control over each step mentioned above, you can choose fully automatic dataset distillation:
In the configuration box, we can see the following options:
Distillation topic (defaults to project name)
Number of levels for the domain tree (default is 2)
Number of tags to generate per level (default is 10)
Number of questions to generate per sub-tag (default is 10)
After the task starts, we can see detailed progress including the specific progress of building tags, questions, and answers:
The system will decide the final language of the generated dataset based on the current user's language selection. Currently, it supports Chinese and English. The default language environment is Chinese. If you need to generate an English dataset, you need to manually switch to English.
Currently, it supports OpenAI standard protocol model access, compatible with Ollama. The system only has some common model configurations built-in. If you can't find the desired model, you can customize the model provider, model name, API address, and key.
In many cases, the system requires the model to output in a specified JSON format. If the model's understanding ability or context length is insufficient, the output may be unstable. It is recommended to replace it with a model with a larger parameter quantity and longer context length.
The processing speed of the task is largely determined by the processing speed of the selected model. If it is a local model, please check the resource utilization rate. If it is a remote model, it is recommended to replace it with a faster and more stable platform.
It is likely that the model's rate limiting strategy has been triggered, which is common in unpaid Silicon Flow and free OpenRouter models. You can manually reduce the concurrent processing number in the task configuration, which is currently set to 5 by default.
You can add custom prompt words in the project configuration - prompt word configuration to actively intervene.
Welcome to Easy Dataset (hereinafter referred to as "this software" or "we"). We highly value your privacy protection, and this privacy agreement will explain how we handle and protect your personal information and data. Please read and understand this agreement carefully before using this software:
To maximize the protection of your privacy and security, we explicitly commit to:
Not collecting, storing, transmitting, or processing any third-party service API Key information that you input into this software;
Not collecting, storing, transmitting, or processing any data set content generated during your use of this software, including but not limited to user-uploaded files, custom annotation data, analysis results, and other business data;
Not collecting, storing, transmitting, or processing any personally identifiable sensitive information (such as name, contact information, address, etc.).
This software supports third-party services (such as data storage platforms, analysis tools, API interfaces, etc.) that you apply for and configure independently, to complete data set management, processing, or analysis functions. The third-party services you use are independently operated and fully responsible by the providers you choose, and Easy Dataset only provides local tool functionality for interface calls with third-party services.
Therefore:
All data generated by your interaction with third-party services through this software (including data sets, operation records, etc.) are unrelated to Easy Dataset, and we do not participate in data storage or perform any form of data transmission or transfer;
You need to independently view and accept the privacy agreements and related policies of the corresponding third-party service providers, which can be accessed on the official websites of the respective providers.
You must assume the potential privacy risks involved in using third-party service providers. For specific privacy policies, data security measures, and related responsibilities, please refer to the official website of the selected service provider. We do not assume any responsibility for this.
This agreement may be adjusted accordingly with software version updates. Please pay attention to it regularly. When the agreement undergoes substantial changes, we will remind you in an appropriate manner (such as software pop-ups, announcements, etc.).
If you have any questions about the content of this agreement or Easy Dataset's privacy protection measures, please feel free to contact us through official channels (email/customer service phone/online form). Thank you for choosing and trusting Easy Dataset. We will continue to provide you with a safe and reliable product experience.
Many people are confused about what format the data fed to the model should be in, which is actually because they haven't distinguished several common types of fine-tuning tasks. In order to solve different problems in different business scenarios, the types of fine-tuning tasks we may adopt are different, so the dataset formats used will also differ. Therefore, to clarify what kind of dataset format we need to organize, we first need to understand what kind of task scenario our fine-tuning belongs to. Below is a classification diagram of common fine-tuning tasks that I have sorted out:
Training a model from scratch is generally called pre-training. The purpose of this process is to enable the model to master the general rules of language and basic language understanding capabilities. Currently, mainstream large models in the market, such as ChatGPT, DeepDeek, etc., are all "autoregressive models", and the essence of "autoregressive models" is:
Using past self to predict future self.
We all know that when large models output text, they output according to Token. Token can be simply understood as breaking sentences into minimal semantic units (such as Chinese characters/words, English words or subwords). The answer is divided into 4 Tokens, each Token is predicted based on the previous question + already output Tokens. The more frequently these keywords appear together in the pre-training dataset, the greater the probability the model will output them. So the richer our dataset, the higher the accuracy of the model's prediction of Token output, and the better the final output effect. Therefore, in the pre-training process, we generally use massive unstructured text (such as books, web pages, conversations) to train the model by "predicting the next word", which means that there are no explicit requirements for the format of the pre-training dataset. For example, the following data can be used directly for training: But for fine-tuning in specific domains, unstructured text cannot be used. We can understand it this way:
Pre-training stage: Like a baby learning to speak, hearing various sounds (unstructured), regardless of what they are, just let them listen more, and gradually they will learn the rules of language;
Instruction fine-tuning stage: Like teaching a child what to do "when hearing a question, answer it", you need to clearly tell them what the question is and what the correct answer is. If you continue to use irregular (unstructured) conversation, they won't have a deep impression of what you want them to learn.
And the pre-training process can be understood as a process of learning and developing abilities without human supervision. Correspondingly, if we want the model to have specific capabilities, supervised fine-tuning is needed.
Supervised Fine-Tuning (SFT), as the name suggests, requires human supervision during the fine-tuning process. For example: if we want to train an English-Chinese translation model, translating English to Chinese is a very clear demand scenario, so in the dataset, we only need to have input and output:
{"input": "Hello", "output": "你好"}1.2.1 Instruction Fine-tuning
What if we want the model to have the ability to understand multiple languages? In this case, two fields alone are not enough, because when the Input is the same word, according to the different tasks we want the model to complete, the output may be different. At this time, we need to introduce the concept of instruction, such as this dataset:
[
{
"instruction": "Translate this English sentence into French",
"input": "Hello, how are you?",
"output": "Bonjour, comment ça va ?"
},
...
]We tell the model the clear instruction: translate English to French, and then tell the model the Input (English) and Output (French), so that the model can accurately understand what to do. This is instruction fine-tuning. Common business scenarios for instruction fine-tuning:
Intelligent Education: Implement homework assistance, plan personalized learning paths, assist language learning.
Intelligent Office: Can handle documents, emails, and schedule management.
Intelligent Translation: Applied to professional field translation, specific scenario translation, and multilingual interaction.
Data Analysis: Let the model provide accurate interpretation and insights of data according to analysis requirement instructions.
Typical open-source datasets for instruction fine-tuning (including instruction, input, output fields):
Alpacadataset: Created by Stanford University, generated through fine-tuning models, containing about 52,000 instruction following data samples. It covers various tasks, such as common sense Q&A, text generation, etc., helping models optimize in terms of instruction understanding and generation.
1.2.2 Dialogue Fine-tuning
Dialogue Fine-tuning (Dialogue Tuning) is to train models to generate coherent, contextual responses through multi-turn dialogue data, emphasizing the understanding of dialogue history context and the naturalness and fluency of responses. Its core is to teach the model to handle logical relationships, emotional expressions, and role identities in dialogues. Dialogue fine-tuning datasets typically include the context of the dialogue and the corresponding responses.
[
{
"dialogue": [
{"role": "user", "content": "今天天气怎么样?"},
{"role": "assistant", "content": "北京今日多云转晴,气温22℃,适合户外活动。"},
{"role": "user", "content": "那适合去长城吗?"},
{"role": "assistant", "content": "长城景区海拔较高,建议携带外套,注意防晒。"}
]
},
...
]The core features of dialogue fine-tuning datasets: containing multi-turn dialogue context, annotated role identities, focusing on response coherence and logic. Through such data, the model can learn how to generate appropriate responses in different dialogue scenarios, thereby improving the coherence and relevance of dialogues. Common business scenarios for dialogue fine-tuning:
Intelligent Customer Service Systems: Improve the dialogue ability of customer service robots in handling user inquiries, more accurately understanding user intentions and providing solutions.
Chatbots: Make chatbots more naturally engage in multi-turn conversations with users, improving user experience.
Voice Assistants: Optimize voice assistants' dialogue performance in voice interactions, making them more in line with user expectations.
Typical open-source datasets for dialogue fine-tuning:
A multilingual Q&A dataset for training dialogue models, with content structure and style conforming to the ShareGPT dialogue format. Each sample in the dataset is a dialogue turn, including human questions and model answers. The data covers multiple languages (English, Spanish, Chinese, Russian, etc.) and diverse domains.
1.2.3 Domain Adaptation
Domain Adaptation refers to fine-tuning models on data from specific domains to better adapt them to tasks and requirements in those specific domains.
[
{
"instruction": "Analyze the patient's symptom description",
"input": "55-year-old male, persistent retrosternal pain for 3 hours, nitroglycerin sublingual ineffective",
"output": "Possible diagnosis: Acute myocardial infarction (STEMI), recommend immediate ECG examination and myocardial enzyme profile test",
"domain": "Medical"
},
{
"instruction": "Explain legal provisions",
"input": "Article 1032 of the Civil Code",
"output": "This provision stipulates that natural persons enjoy the right to privacy, and no organization or individual may infringe upon others' privacy rights by means of spying, harassment, disclosure, publication, etc.",
"domain": "Legal"
},
...
]Core features of domain adaptation datasets: domain terminology annotation (such as medical ontology library, legal terminology library), complex rule modeling (such as drug interactions, contract clause logic), scenario-based data augmentation (such as simulated medical consultation dialogues, contract review processes); Typical business scenarios for domain adaptation:
Medical Domain Adaptation: Used for medical record analysis, disease diagnosis assistance, medical literature retrieval, etc.
Legal Domain Adaptation: Assist in legal document analysis, case retrieval, contract review, etc.
Financial Domain Adaptation: Used for risk assessment, market analysis report generation, financial product recommendation, etc.
Typical open-source datasets for domain adaptation:
A medical Q&A dataset based on
PubMedliterature, containing medical research-related questions, suitable for medical information extraction and domain adaptation tasks.
1.2.4 Text Classification
Text Classification is a classic task in natural language processing, with the purpose of training models to predict categories or assign labels to text through annotated data. This type of task requires the model to understand the relationship between text semantics and category features, and is suitable for scenarios that require structured output.
[
{"text": "This phone has a battery life of up to 48 hours, and the photo effect is amazing", "label": "positive"},
{"text": "The system frequently stutters, and the customer service response is slow", "label": "negative"},
{"text": "Quantum computers breakthrough in new error correction code technology", "label": "science_news"},
{"text": "The central bank announced a 0.5 percentage point reduction in the reserve requirement ratio", "label": "finance_news"}
]Typical business scenarios for text classification fine-tuning:
Sentiment Analysis: Product review sentiment polarity recognition (positive/negative/neutral)
Content Moderation: Detecting inappropriate content (political/violent/advertising)
News Classification: Automatic categorization into finance/technology/sports sections
Intent Recognition: User query classification (inquiry/complaint/price comparison)
Typical open-source datasets for text classification:
imdbLarge Movie Review Dataset, containing the mapping relationship from user reviews to movie ratings, suitable for fine-tuning tasks to classify reviews as positive or negative.
1.2.5 Model Reasoning Fine-tuning
Fine-tuning reasoning models is actually a special form of supervised fine-tuning. By explicitly annotating the chain of thought (Chain of Thought, COT) in the dataset, the model is trained not only to provide the final answer but also to generate the logical reasoning process. The core lies in enabling the model to learn "step-by-step thinking", applicable to scenarios requiring complex logical reasoning (e.g., mathematical proofs, code debugging). In datasets used for reasoning model fine-tuning, it is usually necessary to additionally include the model's thought process:
[
{
"instruction": "Solve a math application problem",
"input": "Xiao Ming bought 3 pencils, each costing 2 yuan; he also bought 5 notebooks, each costing 4 yuan more than a pencil. How much did he spend in total?",
"chain_of_thought": [
"Pencil price: 2 yuan/each → 3 pencils total price: 3×2=6 yuan",
"Notebook price: 2+4=6 yuan/each → 5 notebooks total price: 5×6=30 yuan",
"Total cost: 6+30=36 yuan"
],
"output": "The total cost is 36 yuan"
},
...
]Note: Not all tasks are suitable for reasoning models, as reasoning models are prone to hallucinations. In some cases, using reasoning models may have counterproductive effects. When handling simple and straightforward tasks, reasoning models may overcomplicate problems, leading to overthinking, slower responses, and even increased hallucination risks. For example, if you ask a reasoning model to perform retrieval or explanation tasks, when it cannot find reference information, it will generate output based on its own reasoning process, which may not be accurate. The following are scenarios suitable for reasoning model fine-tuning:
Code Generation and Debugging: Reasoning models can understand complex programming problems, generate efficient code solutions, and assist developers in code debugging.
Mathematical Problem Solving: In mathematical modeling, complex calculations, and logical reasoning tasks, reasoning models excel at providing detailed problem-solving steps and accurate answers.
Complex Data Analysis: Reasoning models are adept at handling complex data analysis tasks requiring multi-step reasoning and strategic planning, aiding scientists and researchers in deeper data mining.
Legal and Financial Analysis: When processing complex documents like legal contracts and financial agreements, reasoning models can extract key clauses, interpret ambiguous information, and assist decision-making.
The chain of thought in datasets may be relatively easy to obtain in specific scenarios. For example, in mathematical reasoning task fine-tuning, the problem-solving process inherently present in the dataset can serve as the chain of thought, such as in the following mathematical problem-solving dataset:
Approximately 860,000 Chinese high school math practice problems, as well as problems from American and international math Olympiads, with each problem's solution presented in the chain of thought (CoT) format.
Another approach is through distillation from large models with reasoning capabilities, such as those derived from DeepSeek-R1 and other reasoning models.
Knowledge Distillation (Knowledge Distillation) is a technique that transfers knowledge from complex models (teacher models) to lightweight models (student models). By optimizing student models to produce outputs close to the teacher models' "soft labels", it reduces inference costs while maintaining performance. Constructing model distillation datasets should be the simplest scenario - when you fully trust the large model's outputs, you can directly use its generated Q&A pairs as the dataset, followed by manual quality assessment and validation. Typical open-source model distillation datasets:
Chinese dataset distilled from full-capability DeepSeek-R1, containing not only math data but also extensive general-purpose data, totaling 110K entries.
1.4.1 Reinforcement Learning Fine-tuning
Reinforcement learning fine-tuning builds upon supervised fine-tuning by actively incorporating human feedback to optimize model generation quality. Its core lies in introducing reward models (Reward Model) to evaluate the rationality of generated results and adjusting model parameters through reinforcement learning strategies (e.g., PPO algorithm) to make outputs better align with human preferences.
[
{
"input": "Recommend a science fiction movie",
"output": "Interstellar is a classic science fiction film that explores time and family.",
"reward_score": 4.5 // Human-annotated quality score (0-5)
},
{
"input": "Explain black hole theory",
"output": "Black holes are mysterious celestial bodies composed of dark matter, consuming all matter.",
"reward_score": 2.0 // Contains incorrect information, low score
}
]Reinforcement learning fine-tuning is typically applied in the following business scenarios:
Dialogue System Optimization: After supervised fine-tuning for relevance, further align the model with human values (safety, harmlessness, usefulness).
Content Generation: After supervised fine-tuning for writing ability, further optimize output style (e.g., humor, formality) or avoid sensitive information.
Code Generation: After supervised fine-tuning for code generation ability, further optimize code readability and correctness.
Typical open-source reinforcement learning datasets:
Human preference ranking dataset for reinforcement learning fine-tuning and training reward models.
1.4.2 Multimodal Fine-tuning
Multimodal fine-tuning (Multimodal Fine-Tuning) refers to training models with multiple modalities (text, images, audio, etc.) to enable cross-modal understanding and generation capabilities. This is a parallel category to text-based model fine-tuning, also encompassing supervised/unsupervised fine-tuning, reinforcement learning fine-tuning, and other categories.
[
{
"text": "A cat is chasing a butterfly",
"image_url": "https://example.com/cat.jpg",
"caption": "An orange cat is chasing a white butterfly in the garden"
},
{
"audio": "audio.wav",
"text": "Transcription of meeting recording: Today's agenda is...",
"summary": "The meeting discussed Q3 sales targets and market strategies"
}
]Note that the image, video, and audio data can be in the form of URLs, base64 encoding, or stored directly on Hugging Face. The key is that the data can be read during training.
Multimodal fine-tuning is typically applied in the following business scenarios:
Image-Text Question Answering: Input images and questions, generate answers.
Video Content Understanding: Analyze video frames and subtitles, generate summaries.
Cross-Modal Retrieval: Search for relevant images/videos based on text descriptions.
Typical open-source multimodal fine-tuning datasets:
A collection of 50 large-scale visual language training datasets (only training sets), used for multimodal vision-language model fine-tuning. The dataset structure includes
images(image list) andtexts(dialogue text), with dialogues presented in a user-question, model-answer format, covering tasks like TQA (Text-Image Question Answering).
There is no specific format requirement for model fine-tuning datasets. We generally eliminate differences in various fine-tuning dataset formats in the code. Let's review the code from the previous fine-tuning tutorial:
This code defines a template for formatting fine-tuning datasets, where the three "{}" represent the three variables to be passed in, corresponding to the original problem, thought process, and final answer, respectively.
Alpaca was initially released by Stanford University in 2023 as a 52k instruction fine-tuning dataset, generated by OpenAI's text-davinci-003 model to optimize large language models (like LLaMA) through instruction following tasks. Later, with community development, Alpaca's JSON structure evolved into a universal data format, extending fields like system (system prompts) and history (conversation history), supporting multi-turn dialogue tasks. Suitable for various fine-tuning scenarios, many mainstream frameworks (like LLaMA-Factory, DeepSpeed) can directly load Alpaca-formatted datasets. Here, we reference two examples of Alpaca-formatted datasets in different fine-tuning scenarios from LLaMA-Factory:
Alpaca format for instruction fine-tuning datasets:
Alpaca format for domain adaptation fine-tuning datasets:
Alpaca format for preference datasets:
ShareGPT was originally a data format standard designed by the community to normalize model training data storage for multi-turn dialogue and tool invocation scenarios. Its core objective is to support complex interactions (e.g., user query → tool invocation → result integration) through structured fields like conversations lists and tools descriptions. As the format gained popularity, the community built several specific datasets based on the ShareGPT format, collectively known as "ShareGPT-format datasets".
ShareGPT-format Instruction Fine-tuning Dataset:
ShareGPT-format Preference Dataset:
ShareGPT-format Multimodal Dataset:
Special ShareGPT-format Dataset: OpenAI Format
Below is a detailed comparison between the two dataset formats. You can choose the appropriate format based on your actual requirements:
Comparison Dimension
Alpaca Format
ShareGPT Format
Core Design Purpose
Single-turn instruction-driven tasks (e.g., Q&A, translation, summarization)
Multi-turn dialogues and tool invocation (e.g., chatbots, API interactions)
Data Structure
JSON objects centered around instruction, input, output
Multi-role dialogue chains (human/gpt/function_call/observation) with conversations list as core
Dialogue History Handling
Records history through history field (format: [["instruction", "response"], ...])
Naturally represents multi-turn dialogues through ordered conversations list (alternating roles)
Roles & Interaction Logic
Only distinguishes user instructions and model outputs, no explicit role labels
Supports multiple role labels (e.g., human, gpt, function_call), enforces odd-even position rules
Tool Invocation Support
No native support, requires implicit description through input or instructions
Explicit tool invocation through function_call and observation, supports external API integration
Typical Use Cases
- Instruction response (e.g., Alpaca-7B) - Domain-specific Q&A - Structured text generation
- Multi-turn dialogues (e.g., Vicuna) - Customer service systems - Interactions requiring real-time data queries (e.g., weather, calculations)
Advantages
- Concise structure, clear task orientation - Suitable for rapid single-turn dataset construction
- Supports complex dialogue flows and external tool extension - Closer to real human-machine interaction scenarios
Limitations
- Requires manual history concatenation for multi-turn dialogues
- Lacks dynamic tool interaction capabilities
- More complex data format - Requires strict adherence to role position rules
Training sets teach models "basic knowledge", validation sets optimize "learning methods", and test sets evaluate "practical abilities". The three are like a learning cycle of "pre-study, review, and examination", and none can be missing:
Training Set = Daily Practice Questions (master knowledge points through extensive practice)
Validation Set = Mock Exam Papers (detect learning outcomes, adjust learning methods)
Test Set = Final Exam (evaluate real learning abilities)
Complete Set = All Available Question Banks (includes the original data of the above three)
Role: Core learning materials for models
Example: When teaching AI to recognize cats, show it 10,000 labeled cat images (including different breeds, poses)
Key Points:
Must cover various possibilities (day/night, close-up/distant)
Equivalent to a student's textbook and exercise book
Role: Prevents rote memorization, tests ability to generalize
Typical Scenario: During training, use 2,000 new cat images to validate, discover the model mistakenly identifies "hairless cats" as dogs, and adjust the training strategy
Core Value:
Select the best model version (e.g., different neural network structures)
Adjust hyperparameters (equivalent to changing the learning plan)
Role: Evaluates model's real-world performance
Must Follow:
Absolute isolation principle: The 5,000 cat images in the test set have never appeared during training
Equivalent to a highly confidential exam paper
Common Misconceptions: If the test set is used to repeatedly adjust parameters, it's like cheating on the exam, and the results will be overly optimistic
Inclusion Relationship: Complete set = Training set + Validation set + Test set
Partition Proportion (example):
General situation: 70% training + 15% validation + 15% testing
Small data scenario: 80% training + 10% validation + 10% testing
Below are some frequently asked questions about these three types of datasets:
Why can't they be mixed?: If the test set data leaks into the training set, it's like cheating on the exam, and the model will fail in real-world applications.
What if there's not enough data?: Cross-validation method: Divide the complete set into 5 parts, rotate 4 parts for training and 1 part for validation (similar to "rotating seats for exams"), and synthesize data: Use image flipping, text replacement, and other methods to expand the data volume.
Special Scenario Handling: Time series data: Must be divided according to time order (cannot use random splitting). For example, predicting stock prices, you must use data before 2023 for training and data from 2024 for testing;
You are welcome to join the Code Secret Garden AI group chat. If the group chat link has expired, you can add our assistant on WeChat: codemmhy (remark "AI" to be invited into the group):
Add WeChat: codemmhy, and note "Business Cooperation" (please briefly state your purpose).
Please submit product suggestions and feedback via . Please make sure to strictly follow the Issue template; otherwise, you may not receive a reply.