









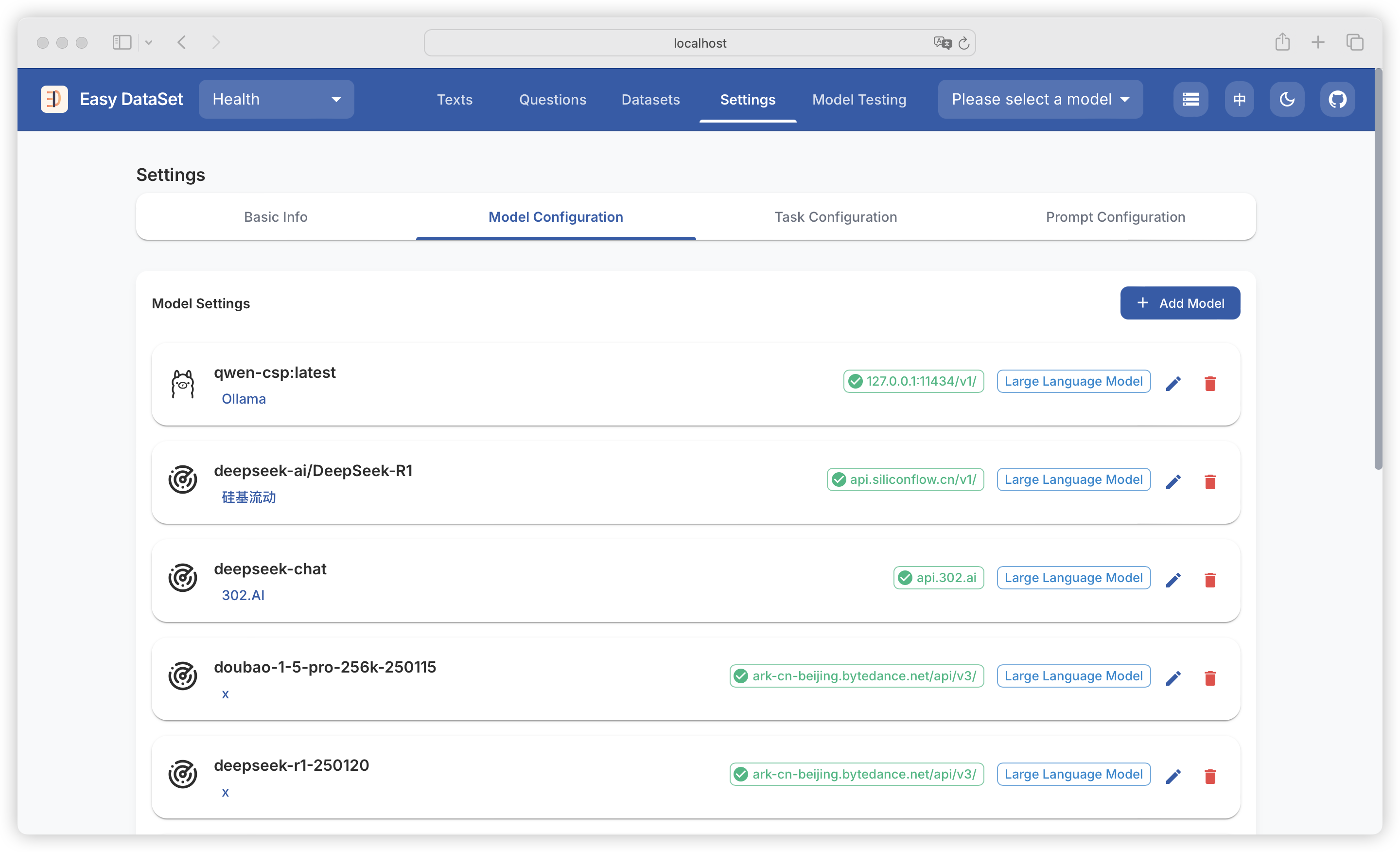
| ProviderId | Name | API URL |
|---|---|---|
| ollama | Ollama | http://127.0.0.1:11434/api |
| openai | OpenAI | https://api.openai.com/v1/ |
| siliconcloud | 硅基流动 | https://api.ap.siliconflow.com/v1/ |
| deepseek | DeepSeek | https://api.deepseek.com/v1/ |
| 302ai | 302.AI | https://api.302.ai/v1/ |
| zhipu | 智谱AI | https://open.bigmodel.cn/api/paas/v4/ |
| Doubao | 火山引擎 | https://ark.cn-beijing.volces.com/api/v3/ |
| groq | Groq | https://api.groq.com/openai |
| grok | Grok | https://api.x.ai |
| openRouter | OpenRouter | https://openrouter.ai/api/v1/ |
| alibailian | 阿里云百炼 | https://dashscope.aliyuncs.com/compatible-mode/v1 |


















































































| 方法 | 核心思路 | 适用场景 |
|---|---|---|
| 蒸馏 | 小模型模仿大模型的解题思路 | 轻量化部署(手机、企业私有云) |
| 微调 | 用特定数据给模型“补课”(如医疗数据) | 垂直领域定制(如法律、医疗问答) |
| RAG | 模型调用外部知识库“作弊” | 企业文档检索(如内部培训资料) |






























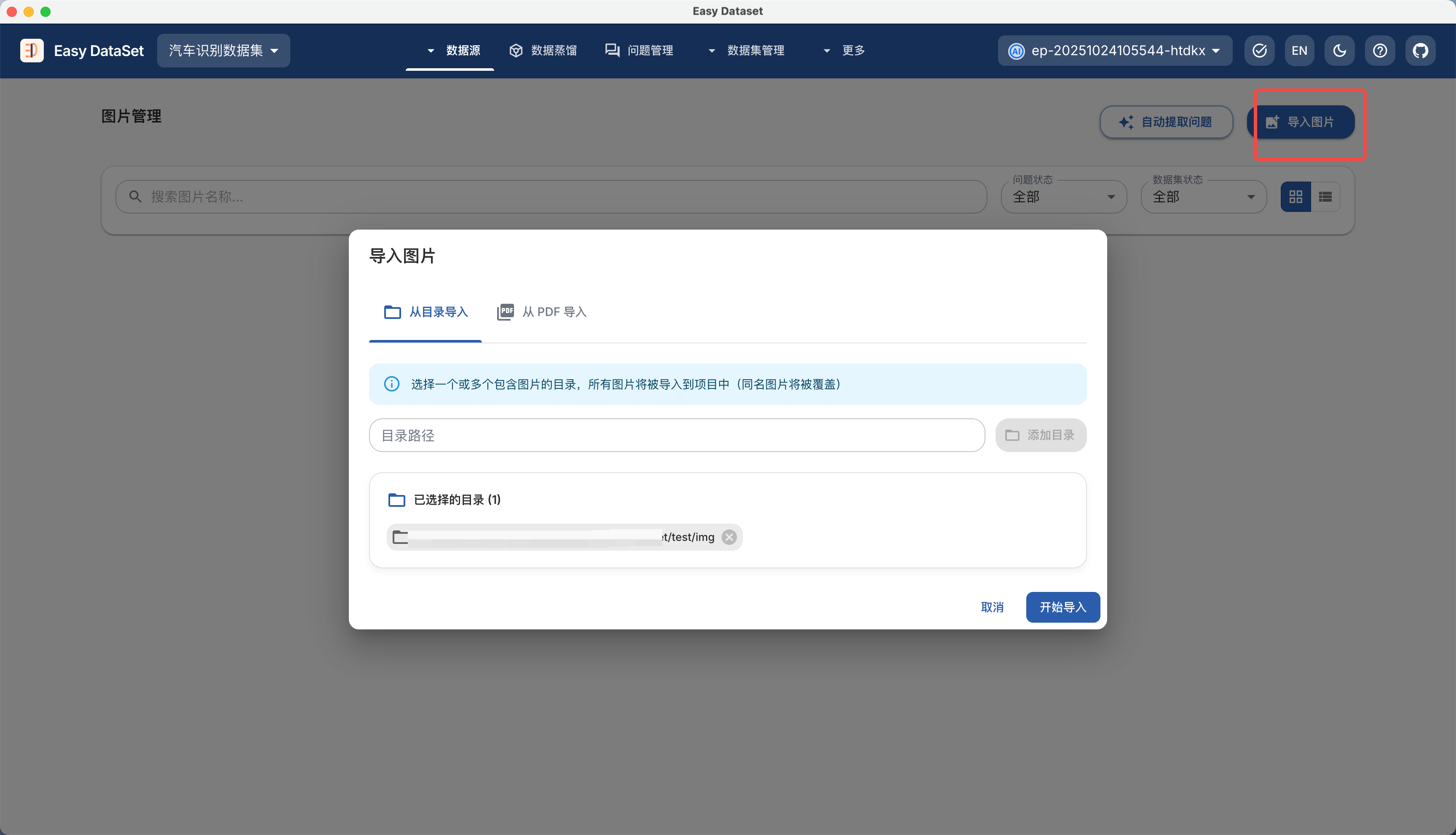
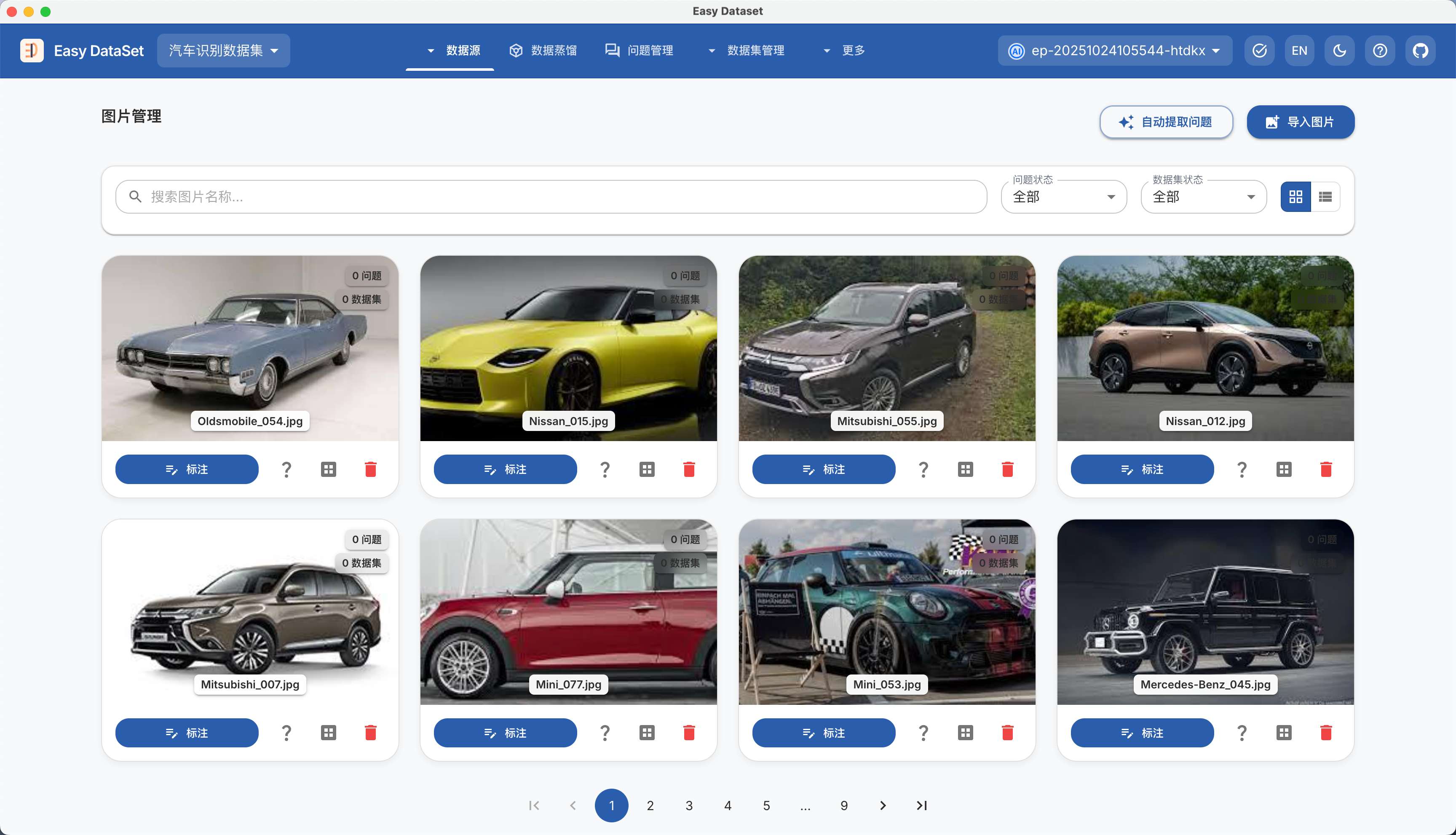
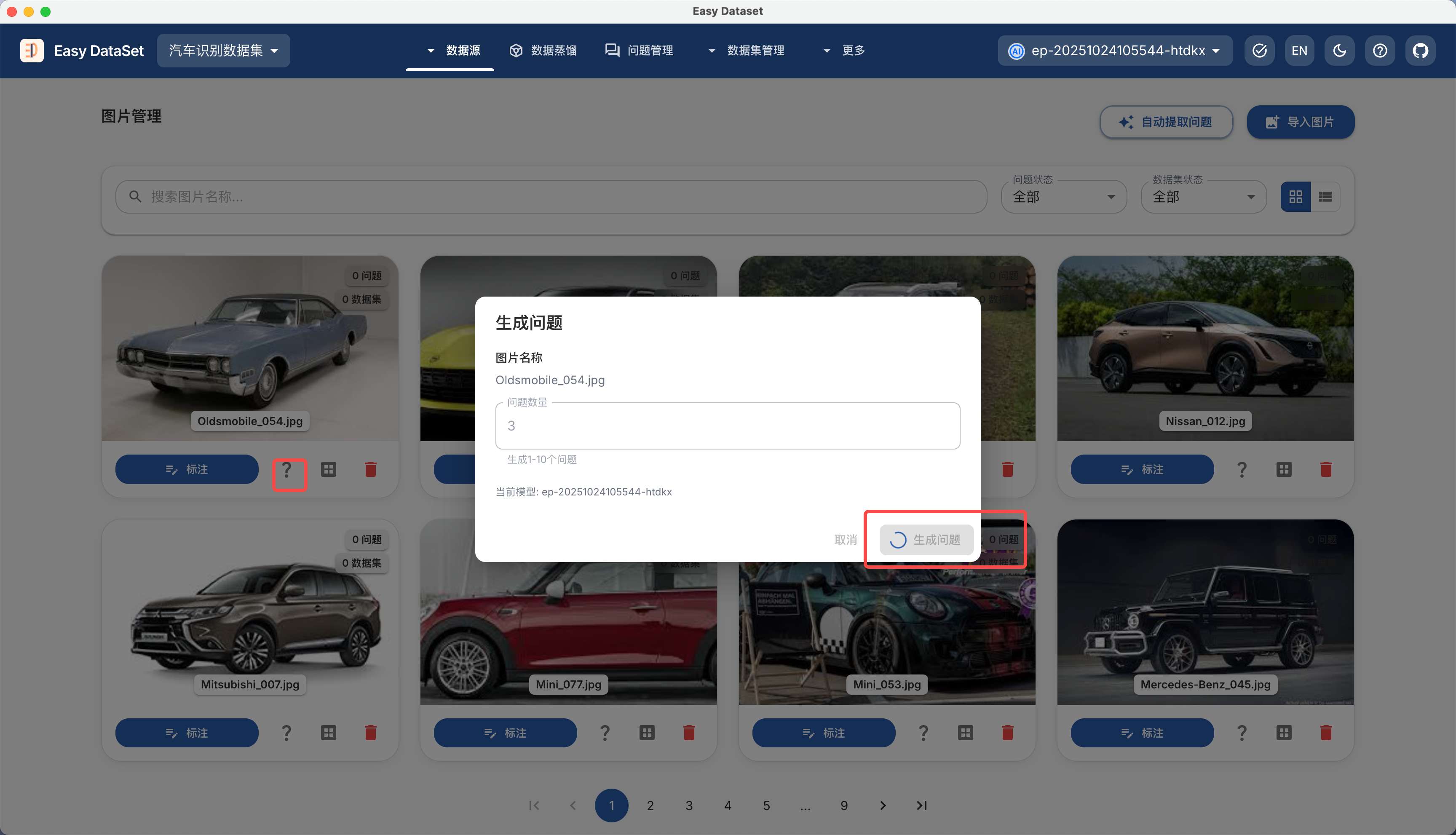
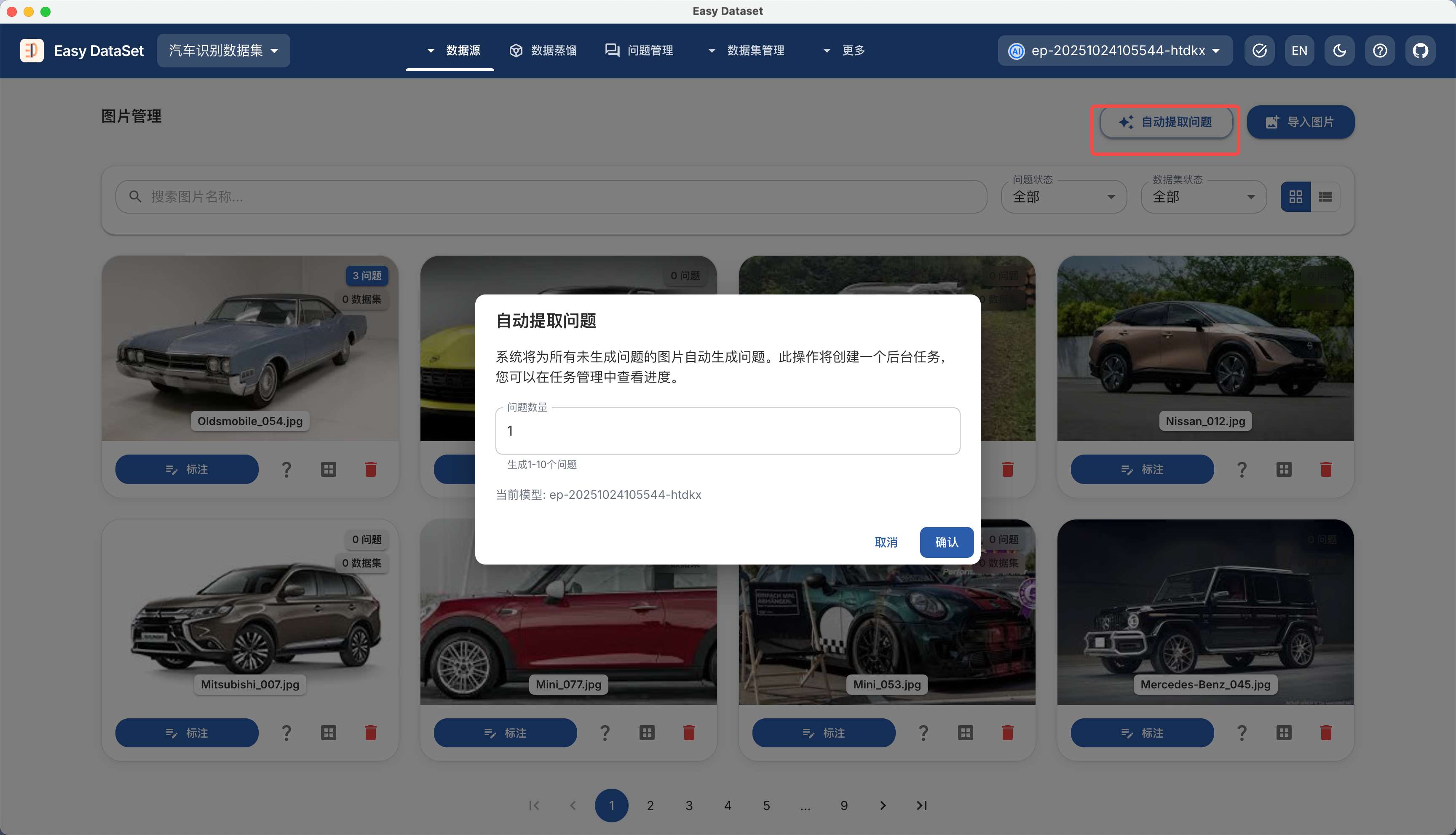
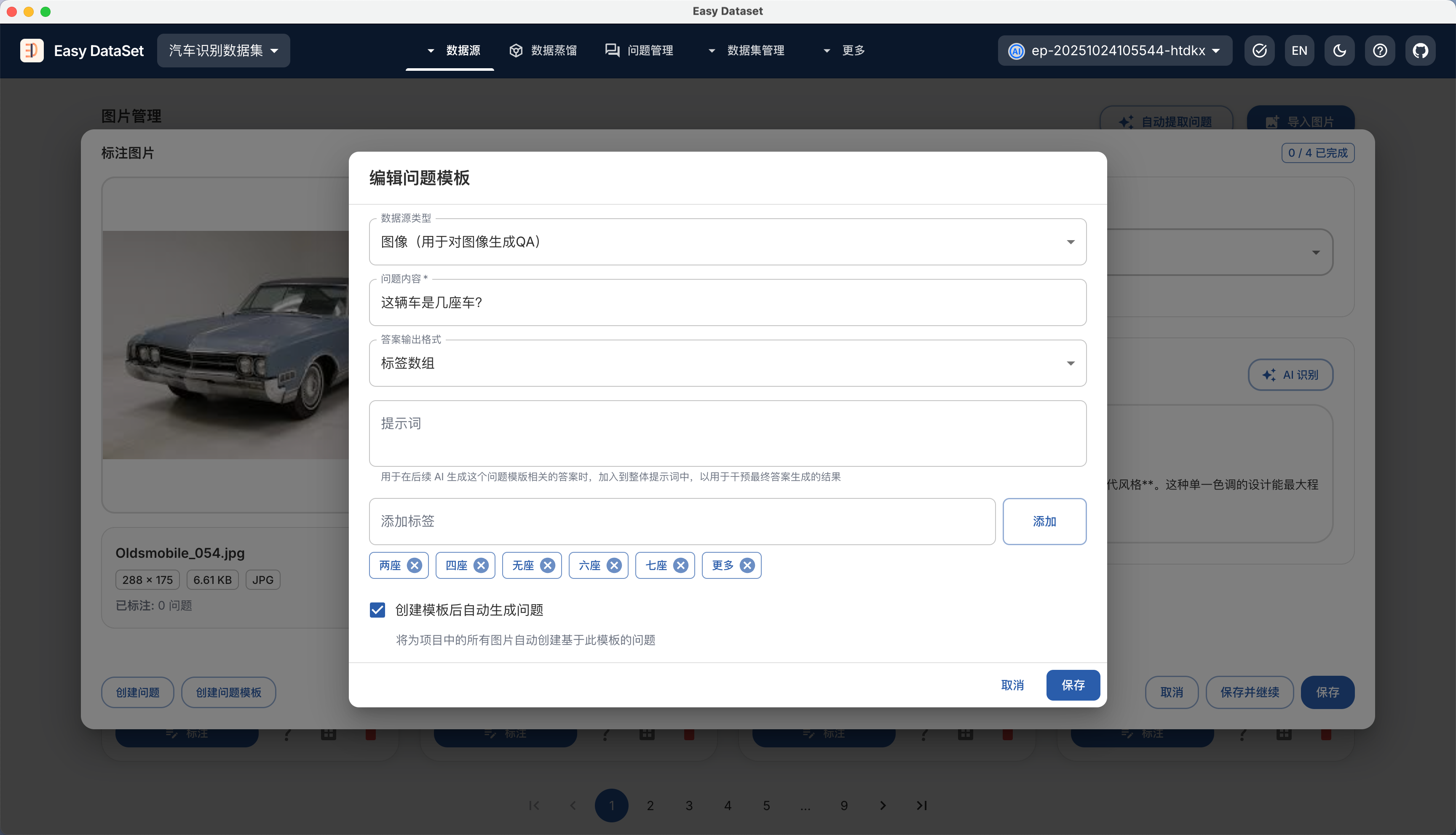
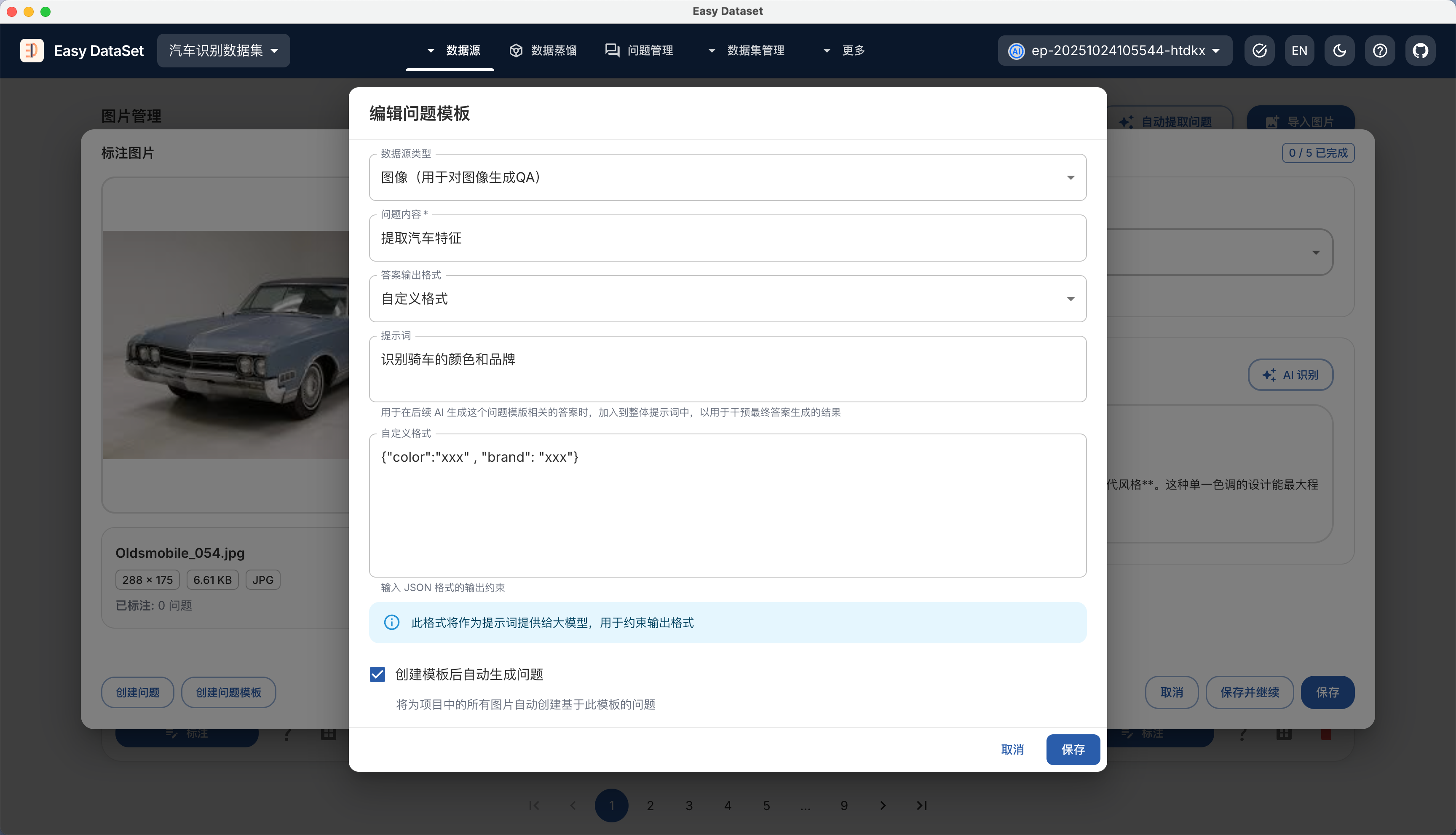
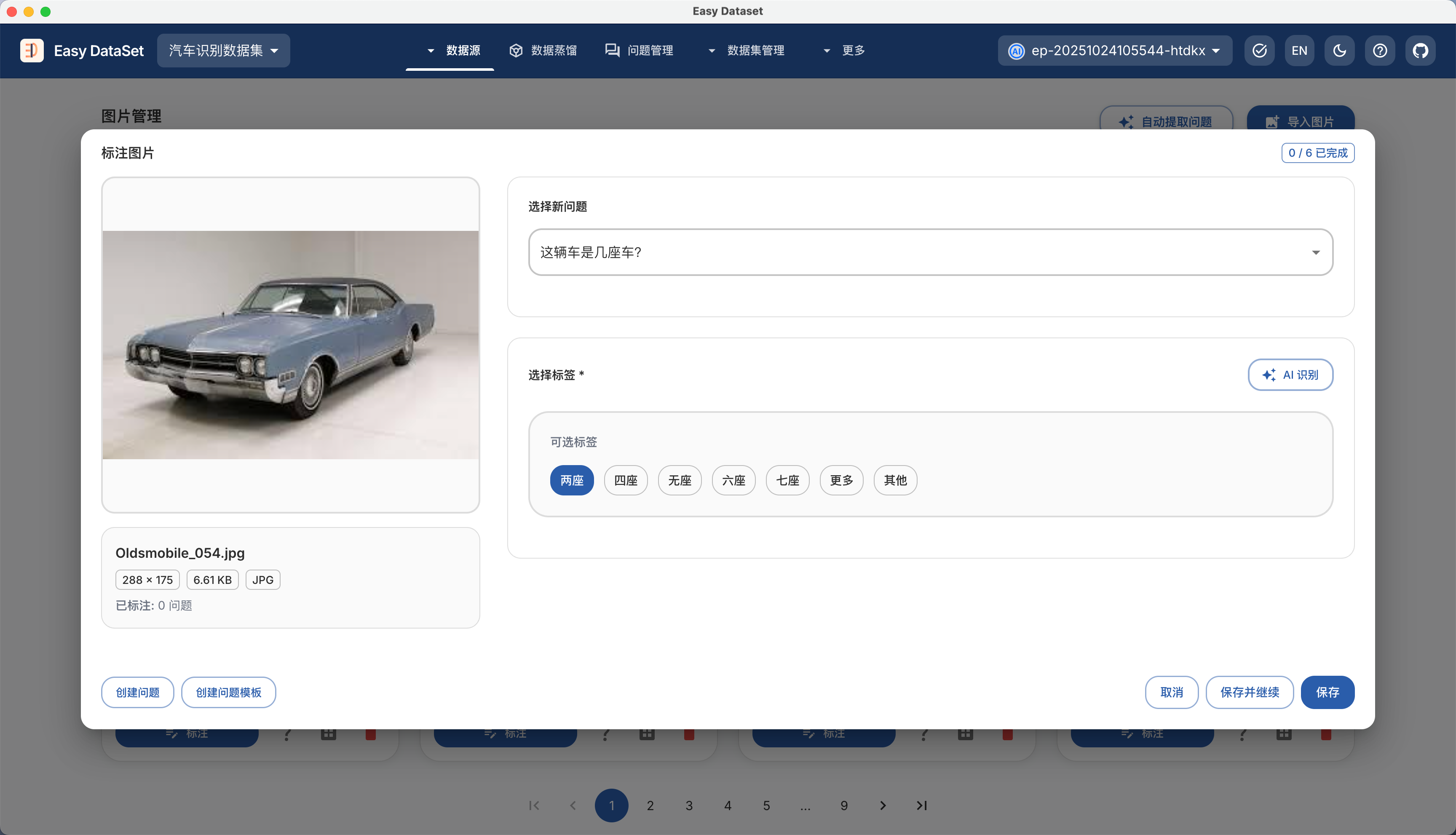
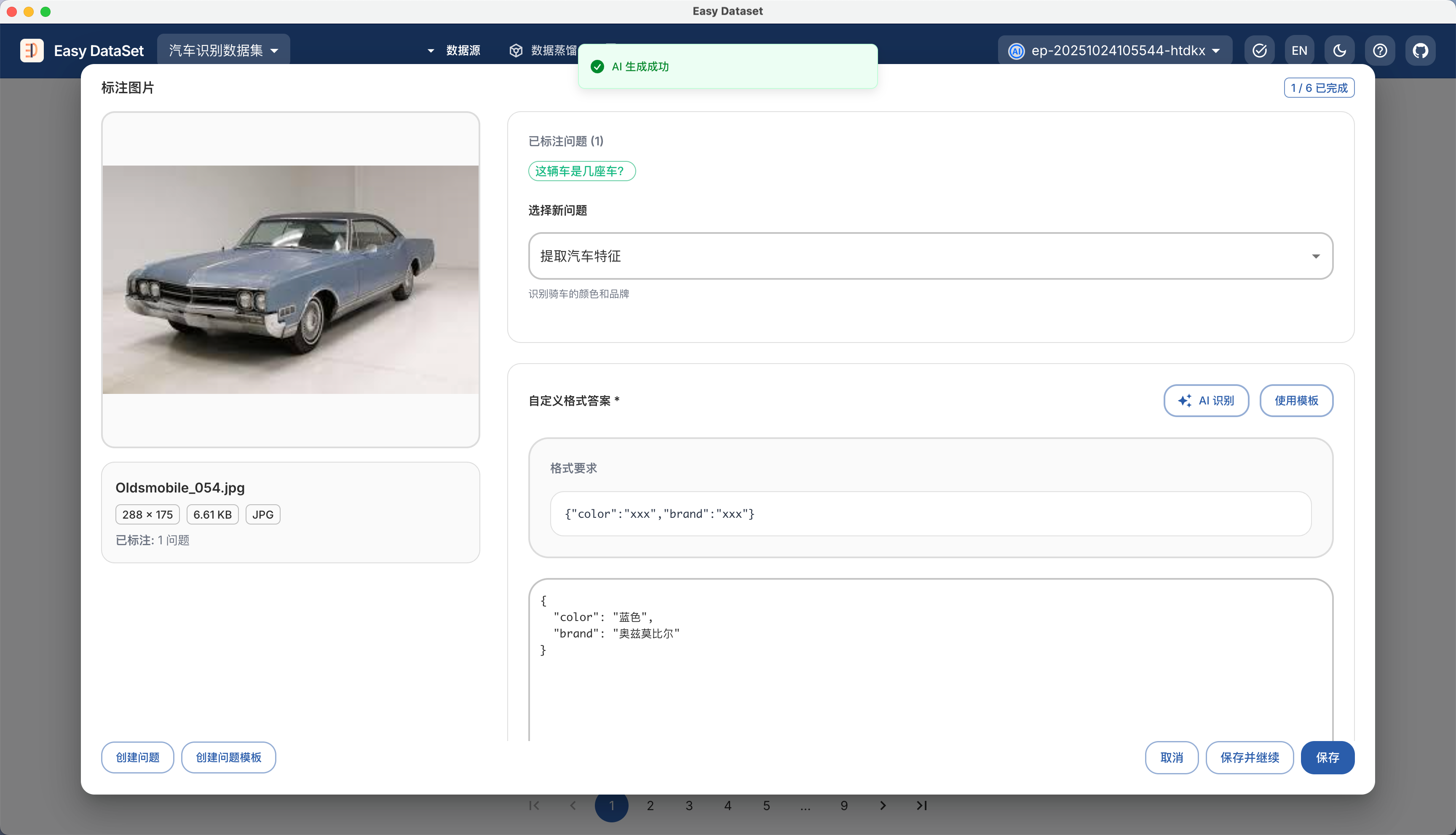
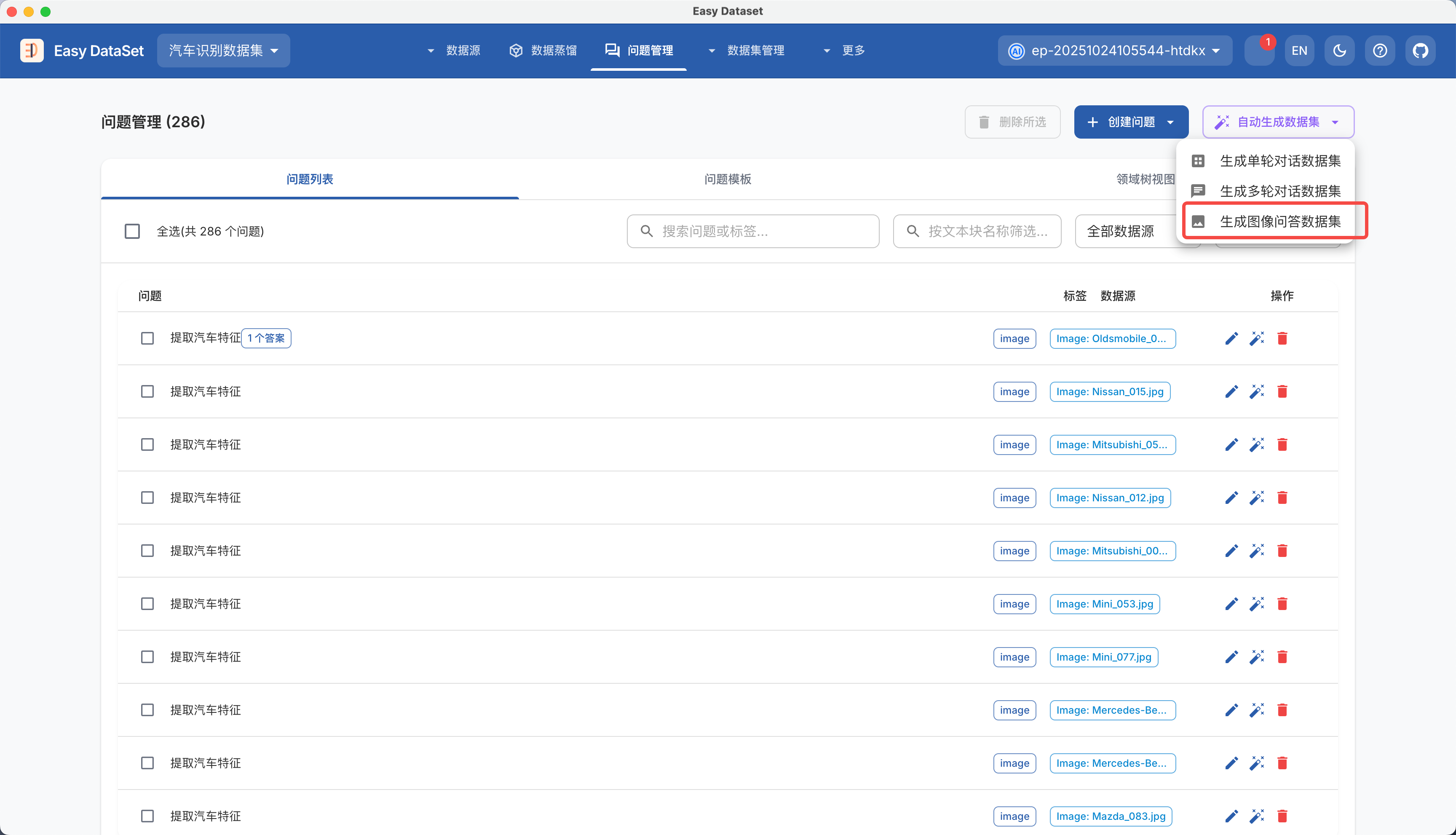
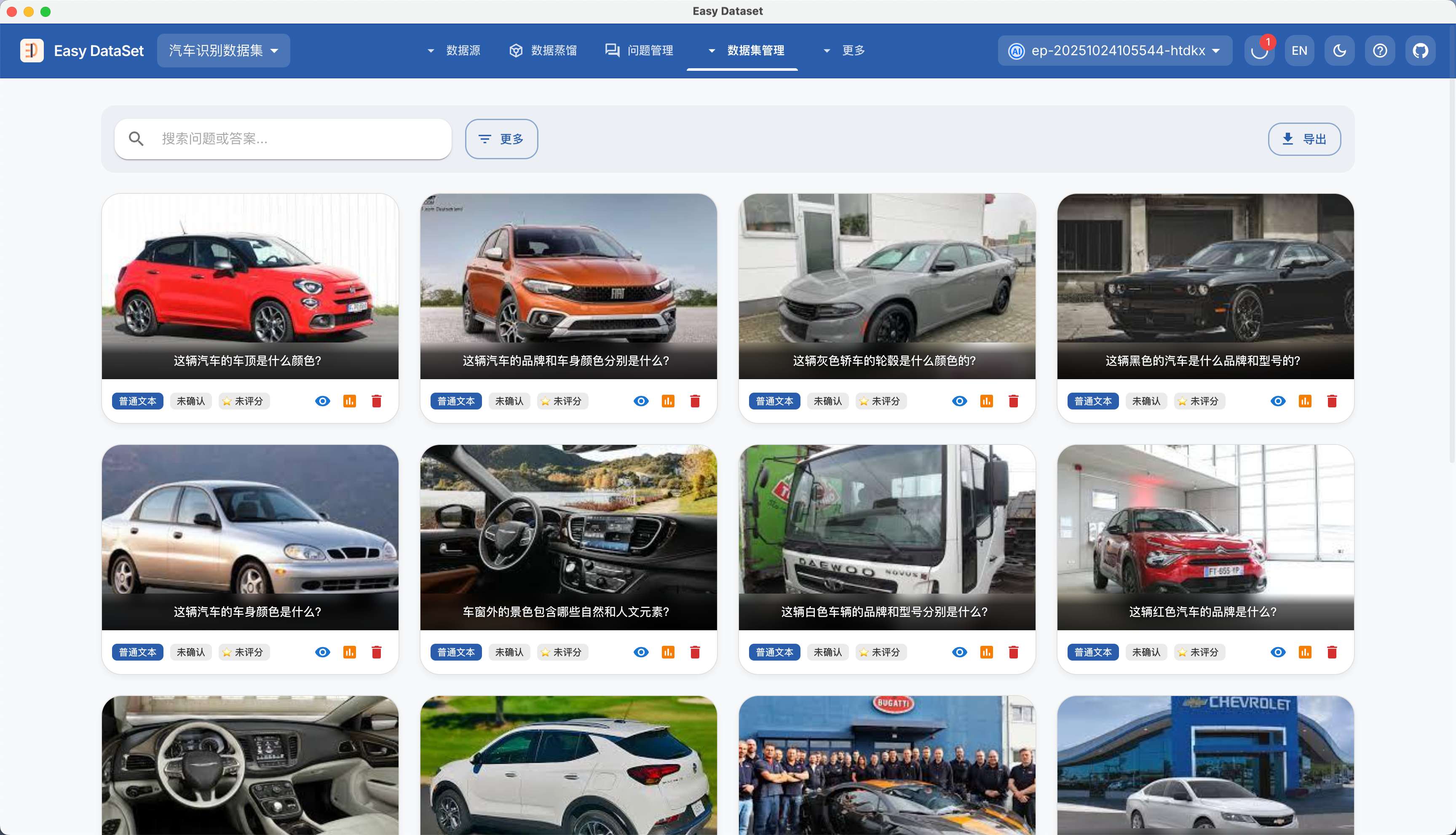
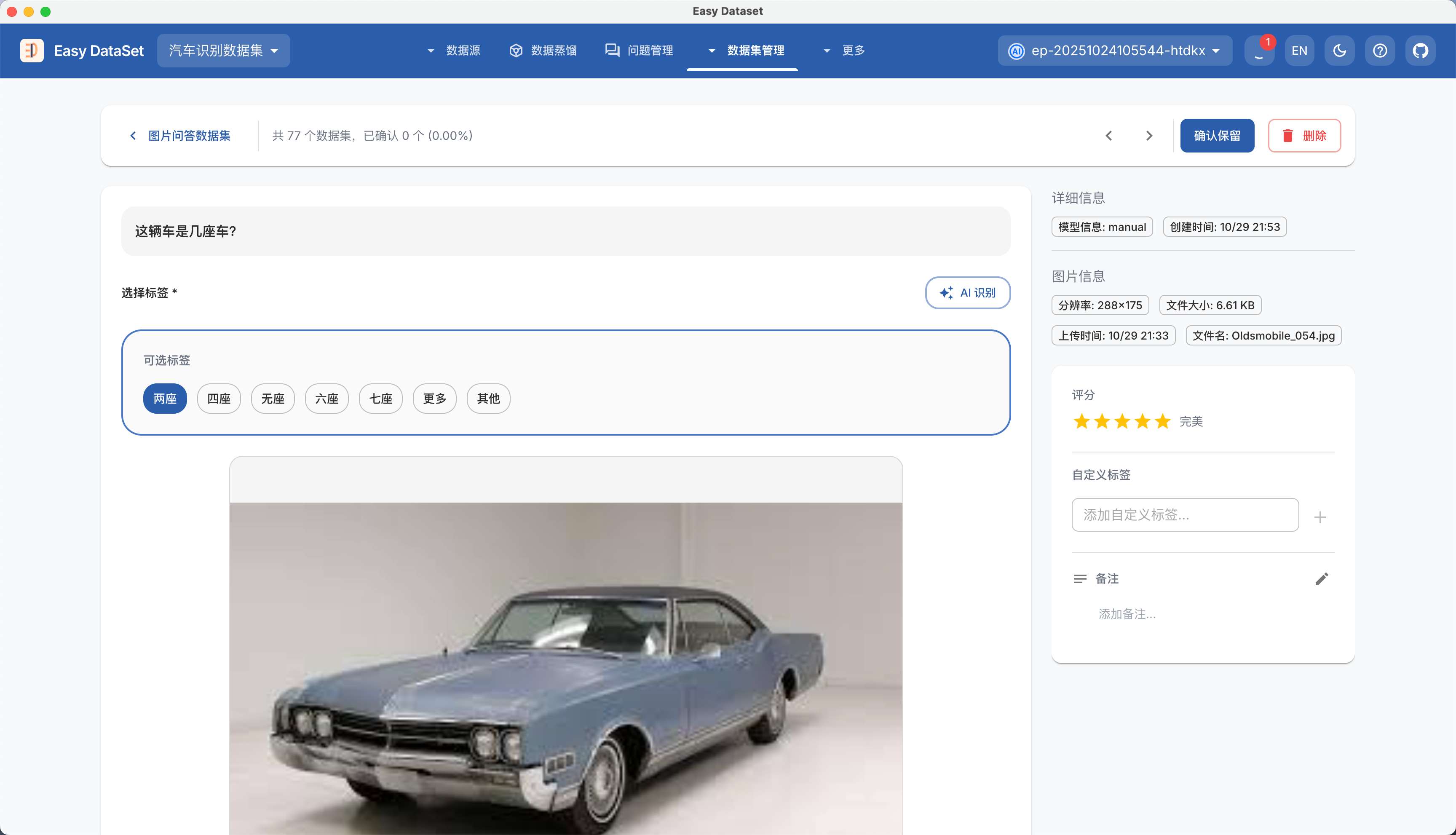
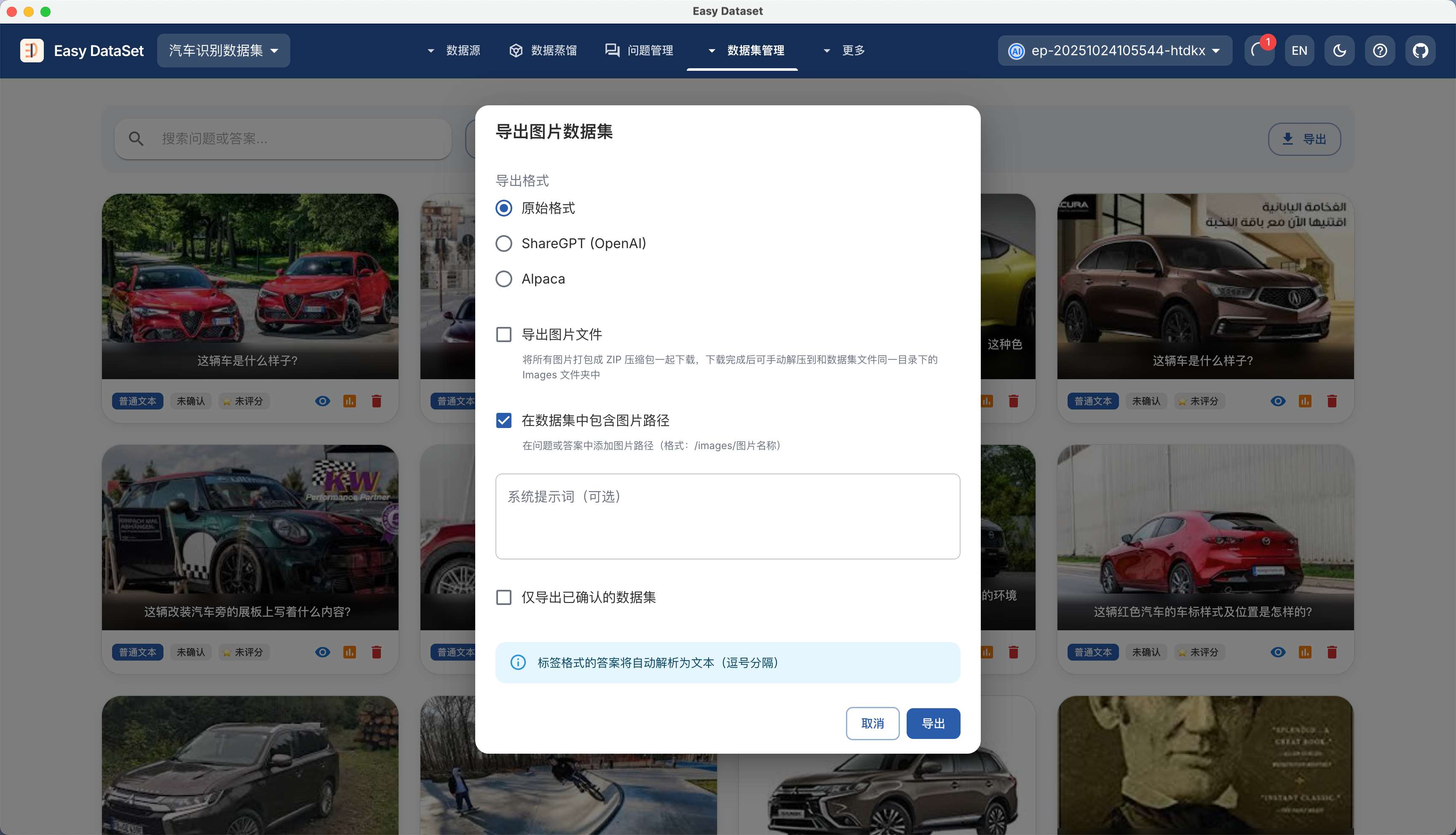
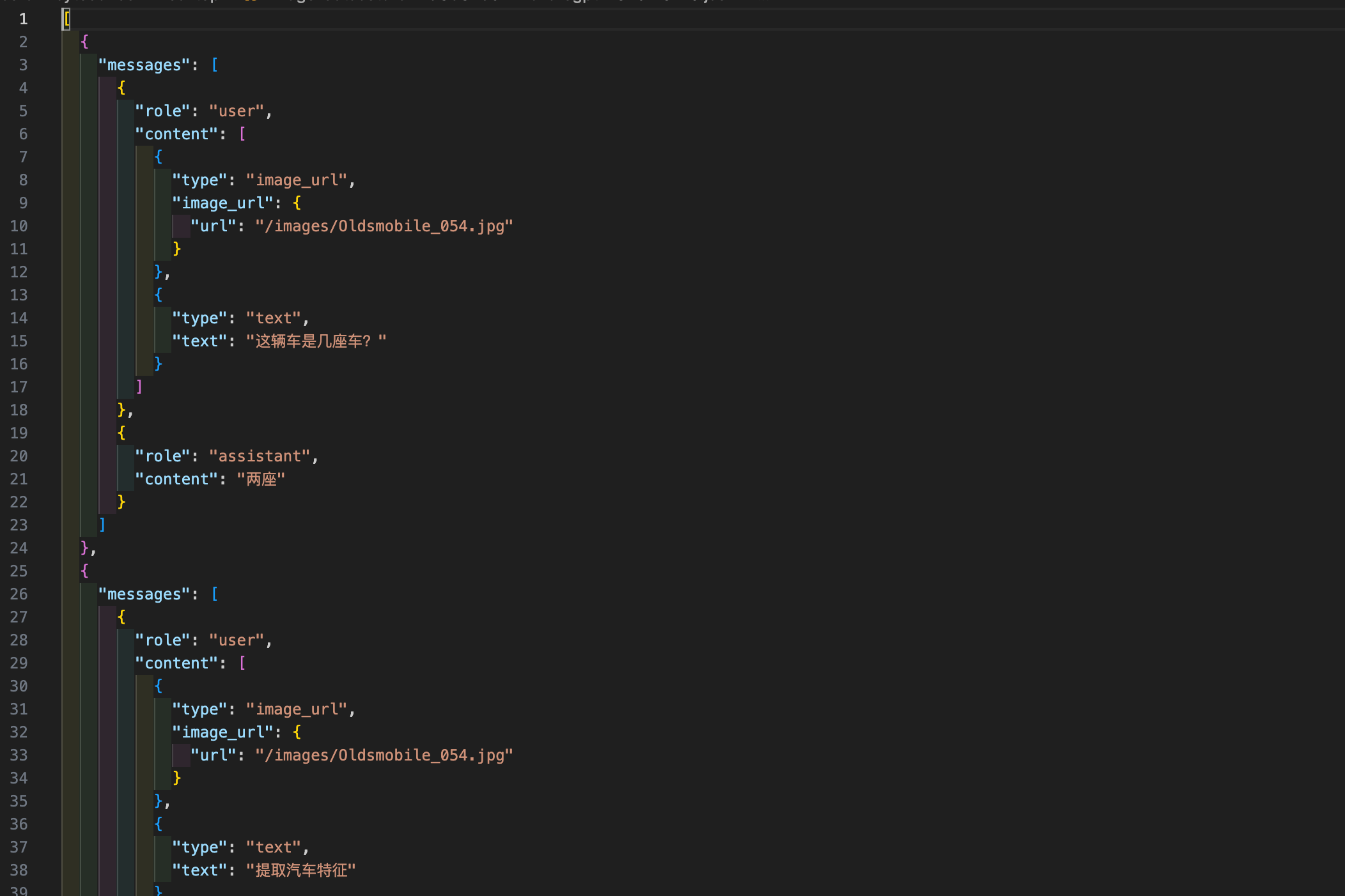

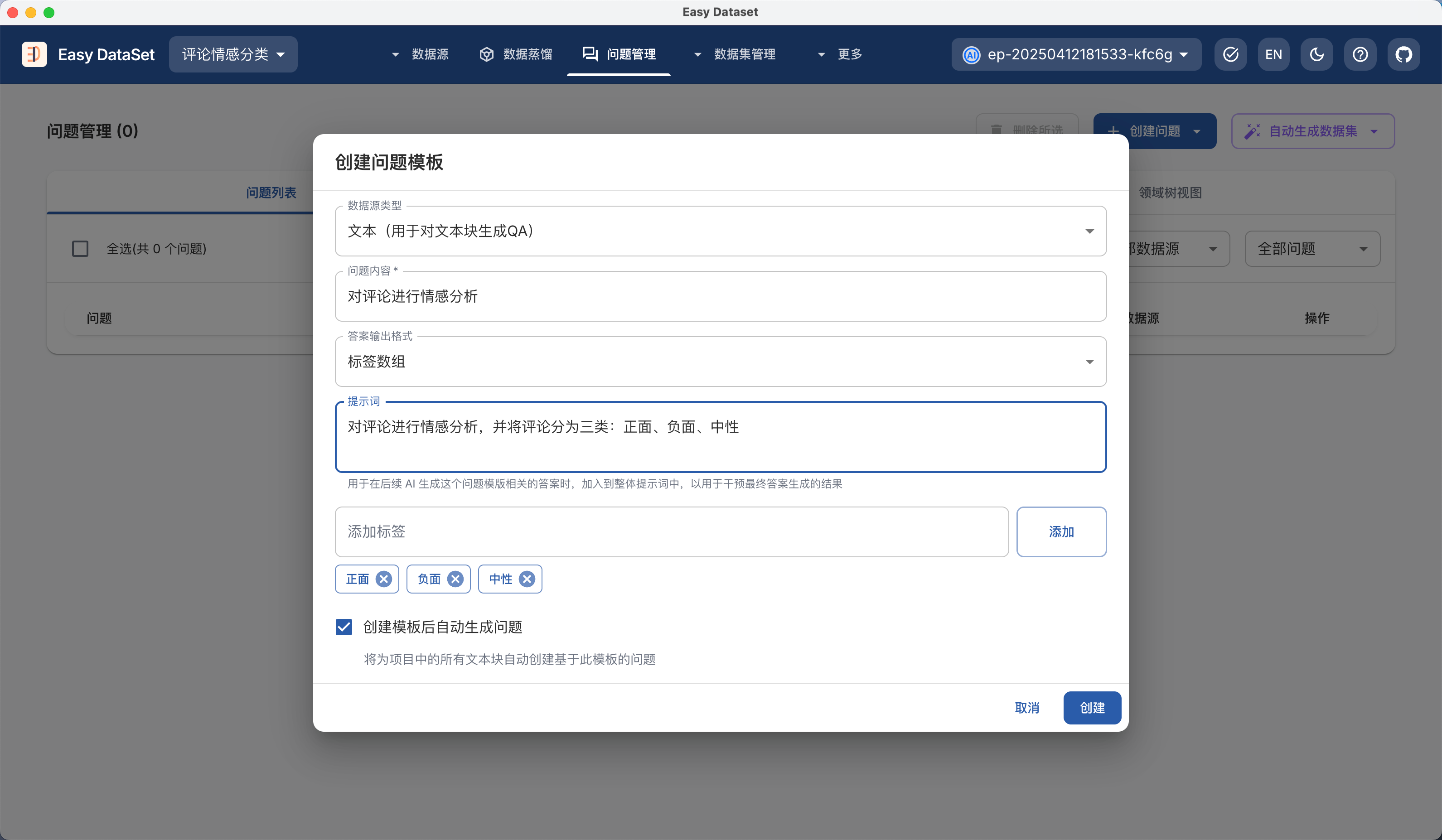
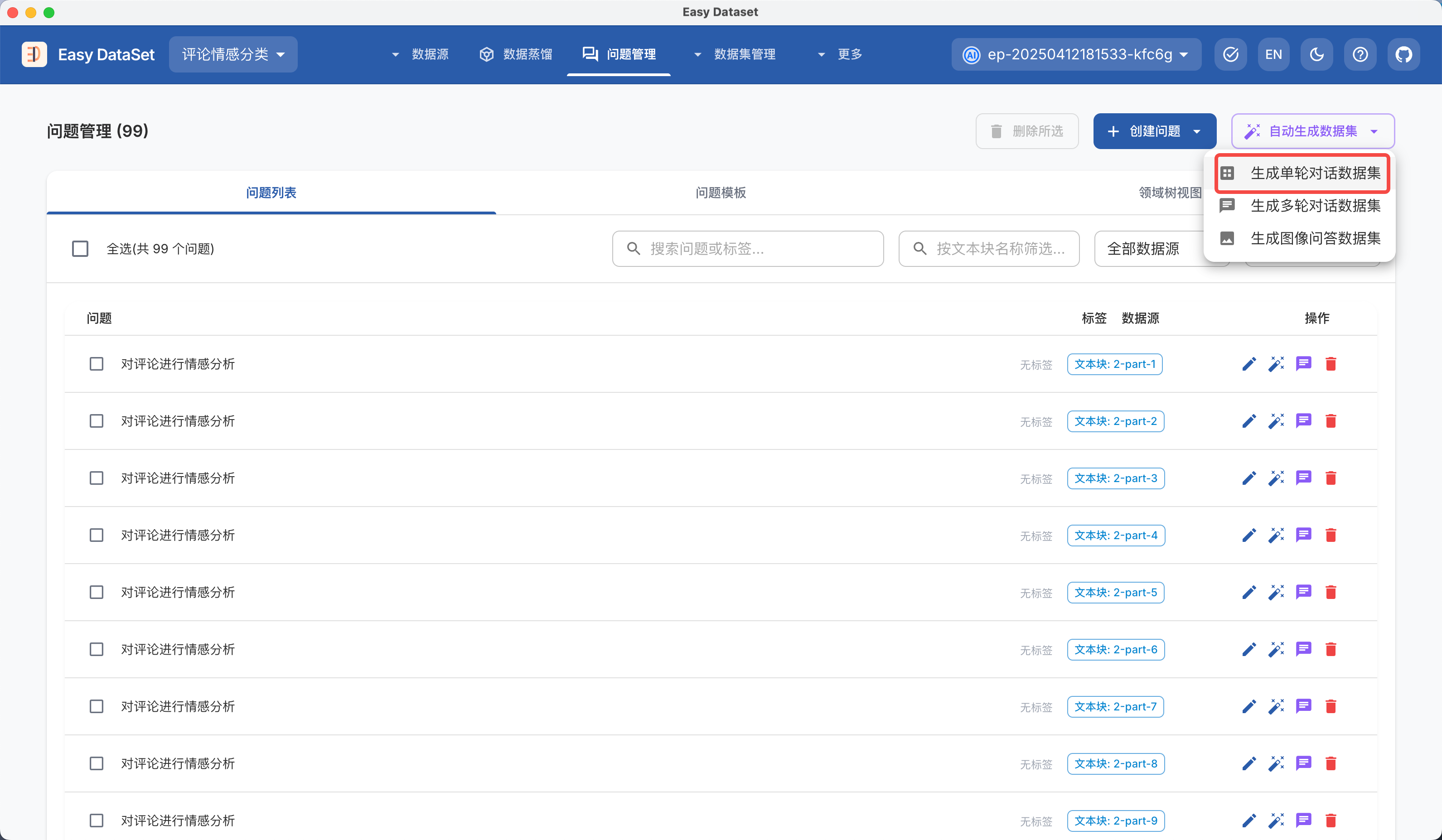
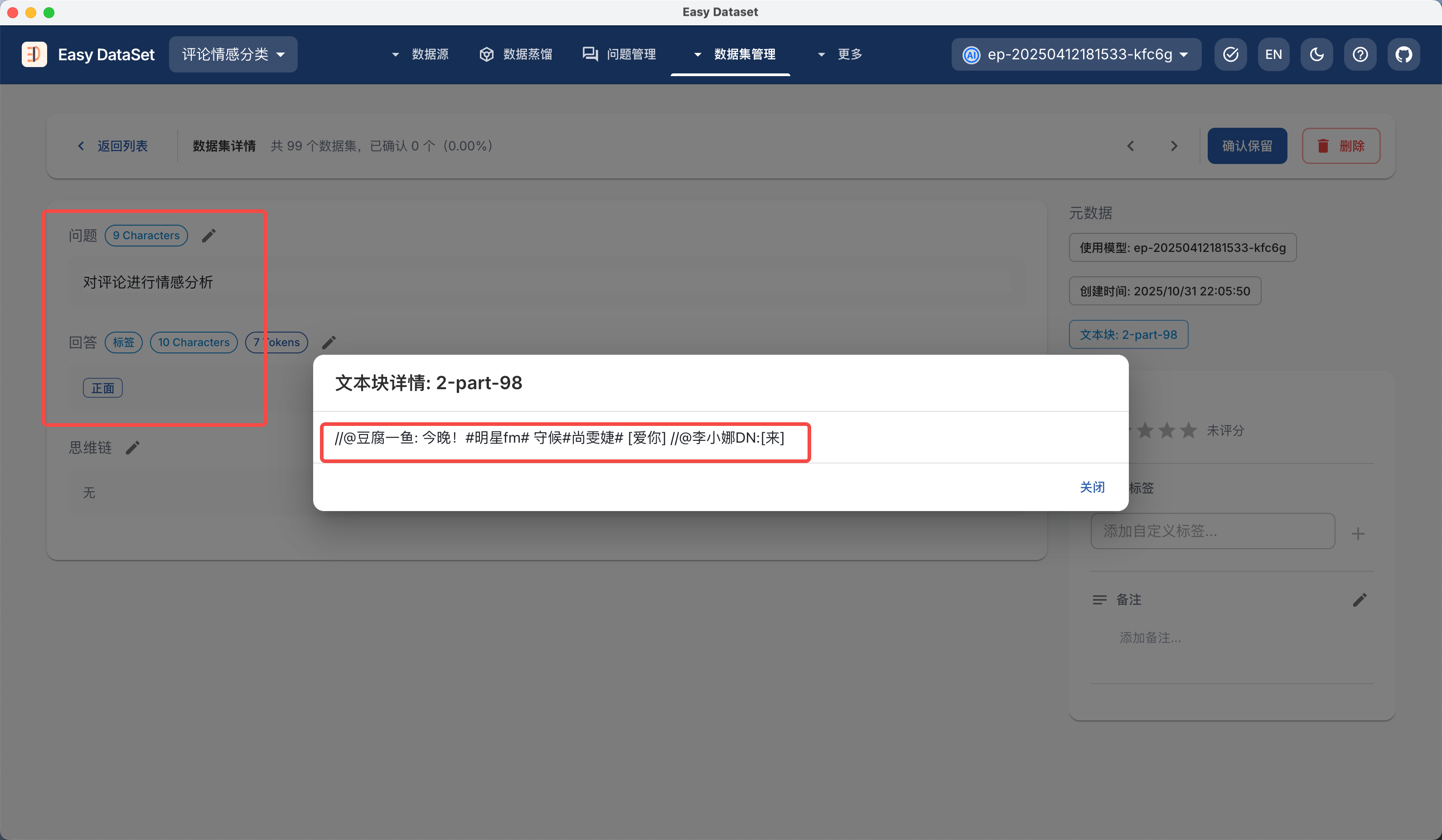
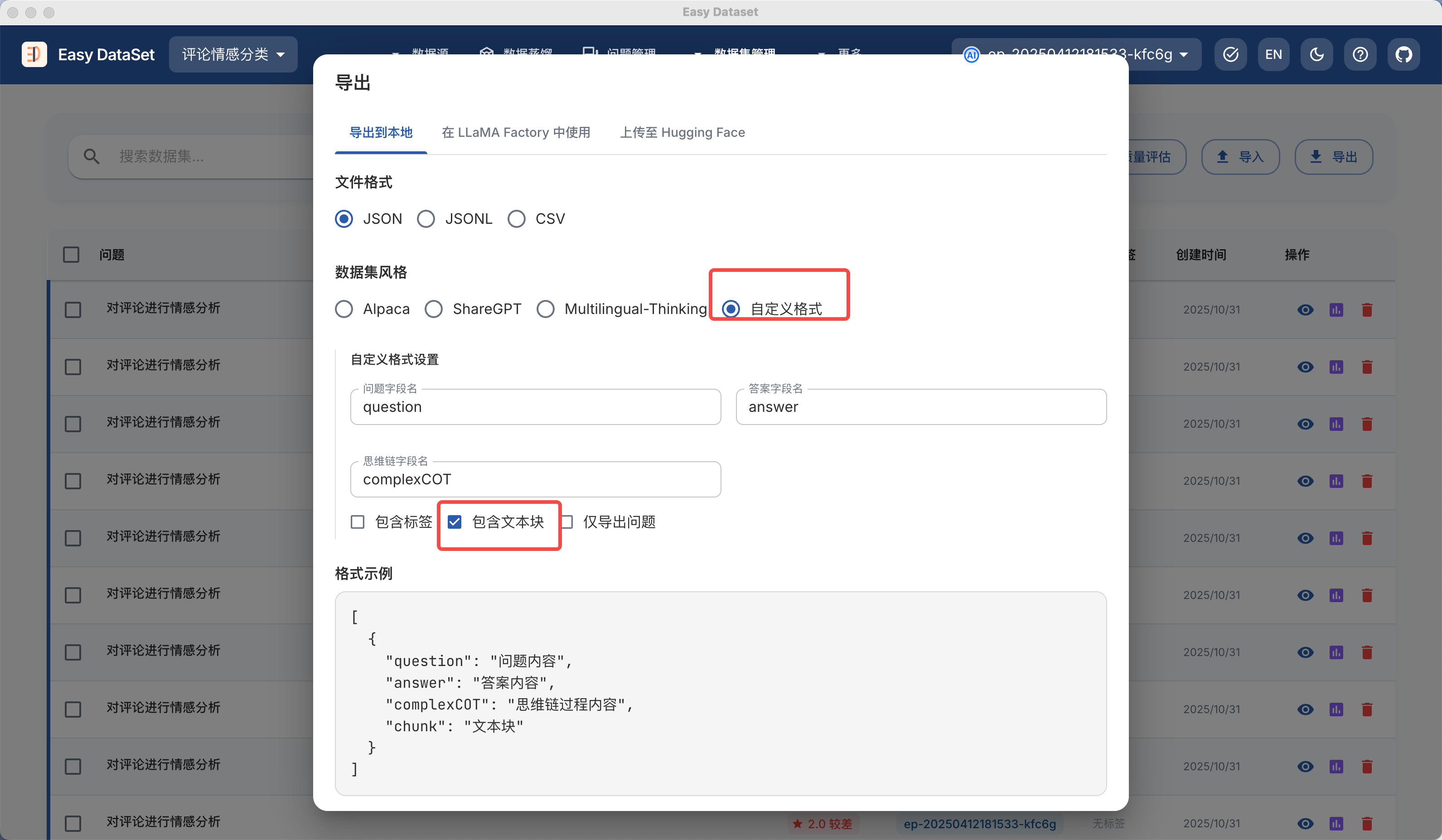
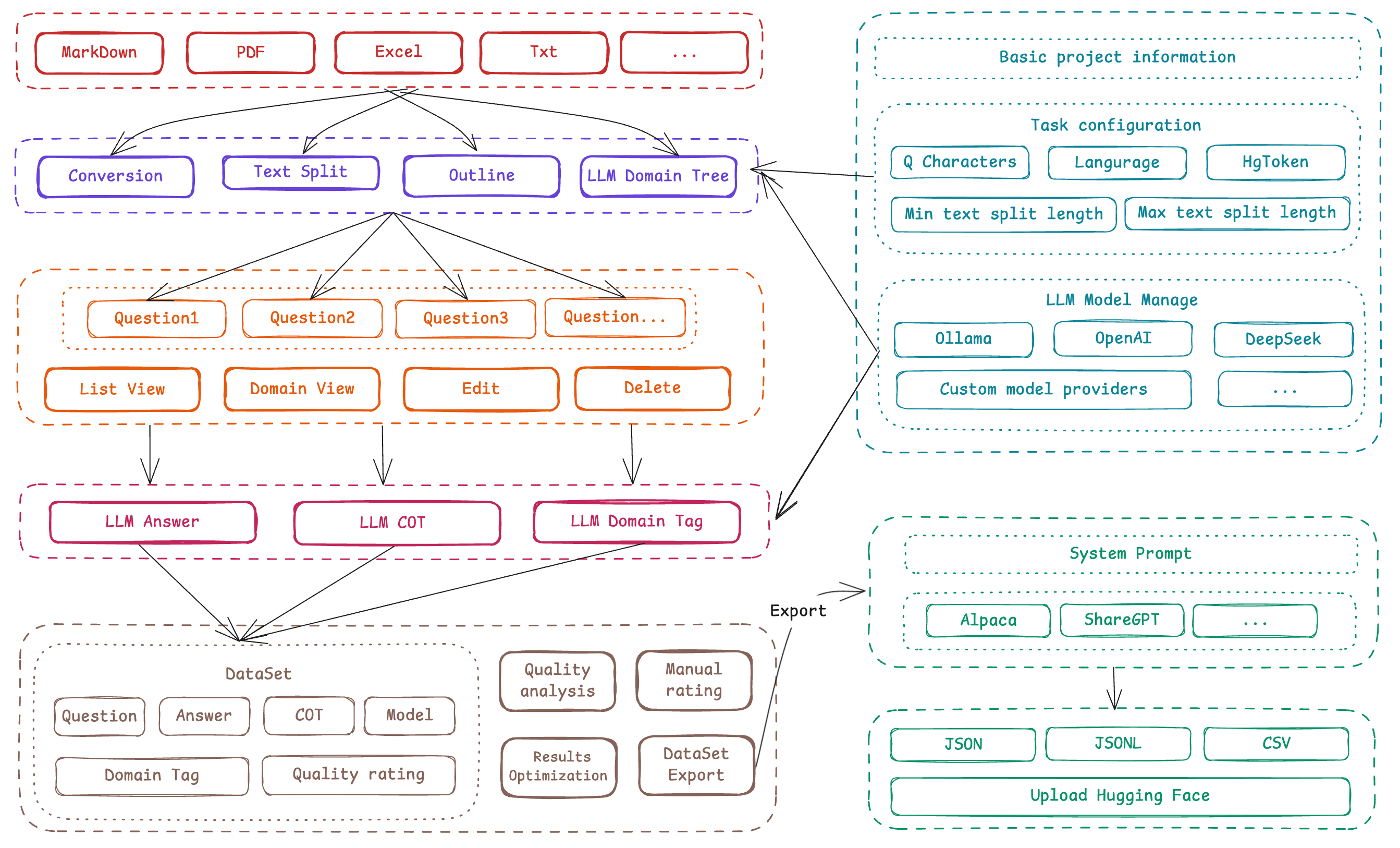
| 对比维度 | Alpaca 格式 | ShareGPT 格式 |
| 核心设计目标 | 单轮指令驱动任务(如问答、翻译、摘要) | 多轮对话与工具调用(如聊天机器人、API 交互) |
| 数据结构 | 以 instruction、input、output 为主体的 JSON 对象 | 以 conversations 列表为核心的多角色对话链(human/gpt/function_call/observation) |
| 对话历史处理 | 通过 history 字段记录历史对话(格式:[["指令", "回答"], ...]) | 通过 conversations 列表顺序自然体现多轮对话(角色交替出现) |
| 角色与交互逻辑 | 仅区分用户指令和模型输出,无显式角色标签 | 支持多种角色标签(如 human、gpt、function_call),强制奇偶位置规则 |
| 工具调用支持 | 不原生支持工具调用,需通过 input 或指令隐式描述 | 通过 function_call 和 observation 显式实现工具调用,支持外部 API 集成 |
| 典型应用场景 | - 指令响应(如 Alpaca-7B) - 领域知识问答 - 文本结构化生成 | - 多轮对话(如 Vicuna) - 客服系统 - 需实时数据查询的交互(如天气、计算) |
| 优势 | - 结构简洁,任务导向清晰 - 适合快速构建单轮任务数据集 | - 支持复杂对话流与外部工具扩展 - 更贴近真实人机交互场景 |
| 局限 | - 多轮对话需手动拼接 history - 缺乏动态工具交互能力 | - 数据格式更复杂 - 需严格遵循角色位置规则 |










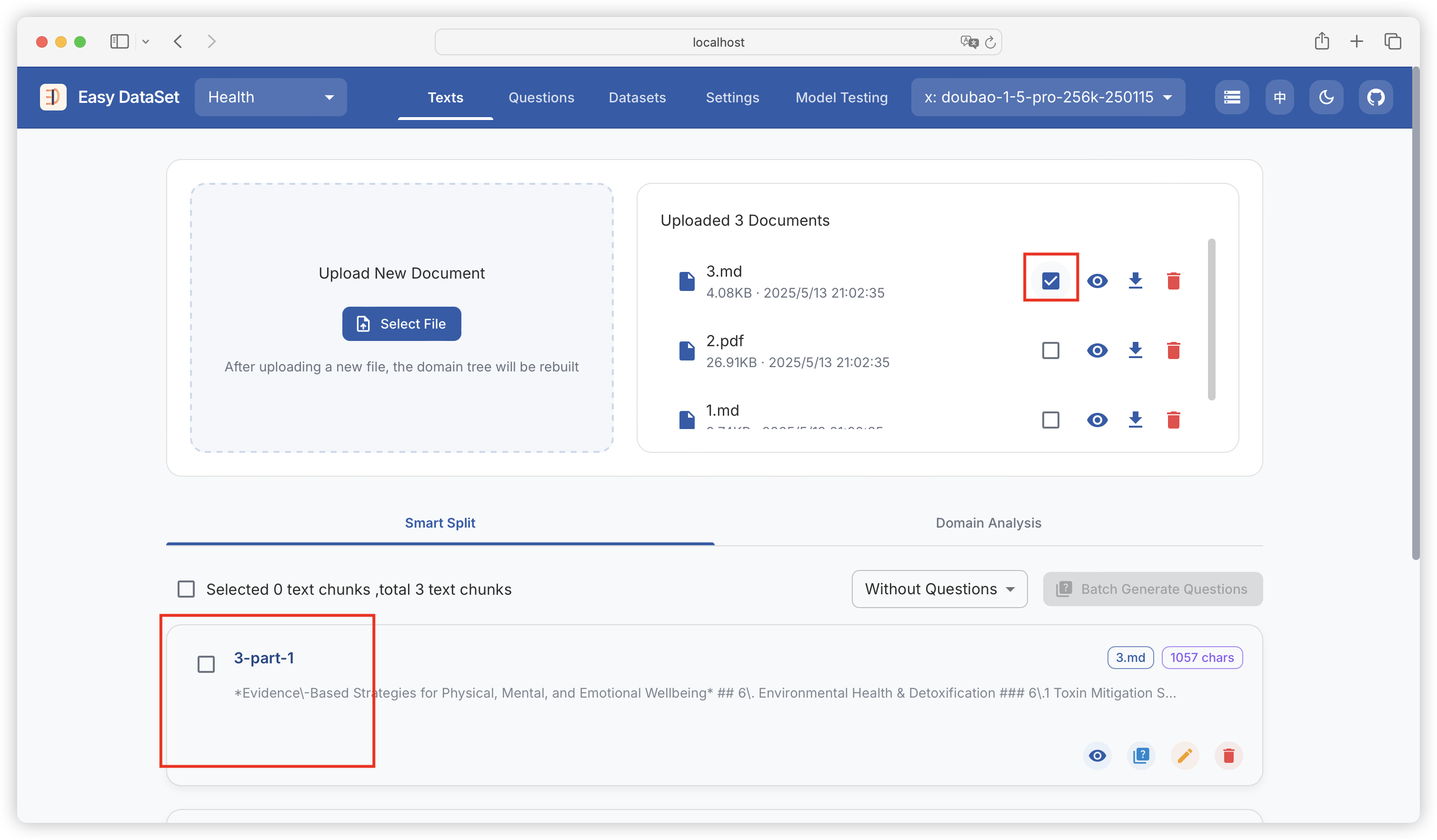
| ProviderId | Name | API URL |
|---|---|---|
| ollama | Ollama | http://127.0.0.1:11434/api |
| openai | OpenAI | https://api.openai.com/v1/ |
| siliconcloud | Silicon Flow | https://api.ap.siliconflow.com/v1/ |
| deepseek | DeepSeek | https://api.deepseek.com/v1/ |
| 302ai | 302.AI | https://api.302.ai/v1/ |
| zhipu | Zhipu AI | https://open.bigmodel.cn/api/paas/v4/ |
| Doubao | Volcano Engine | https://ark.cn-beijing.volces.com/api/v3/ |
| groq | Groq | https://api.groq.com/openai |
| grok | Grok | https://api.x.ai |
| openRouter | OpenRouter | https://openrouter.ai/api/v1/ |
| alibailian | Alibaba Cloud Bailian | https://dashscope.aliyuncs.com/compatible-mode/v1 |
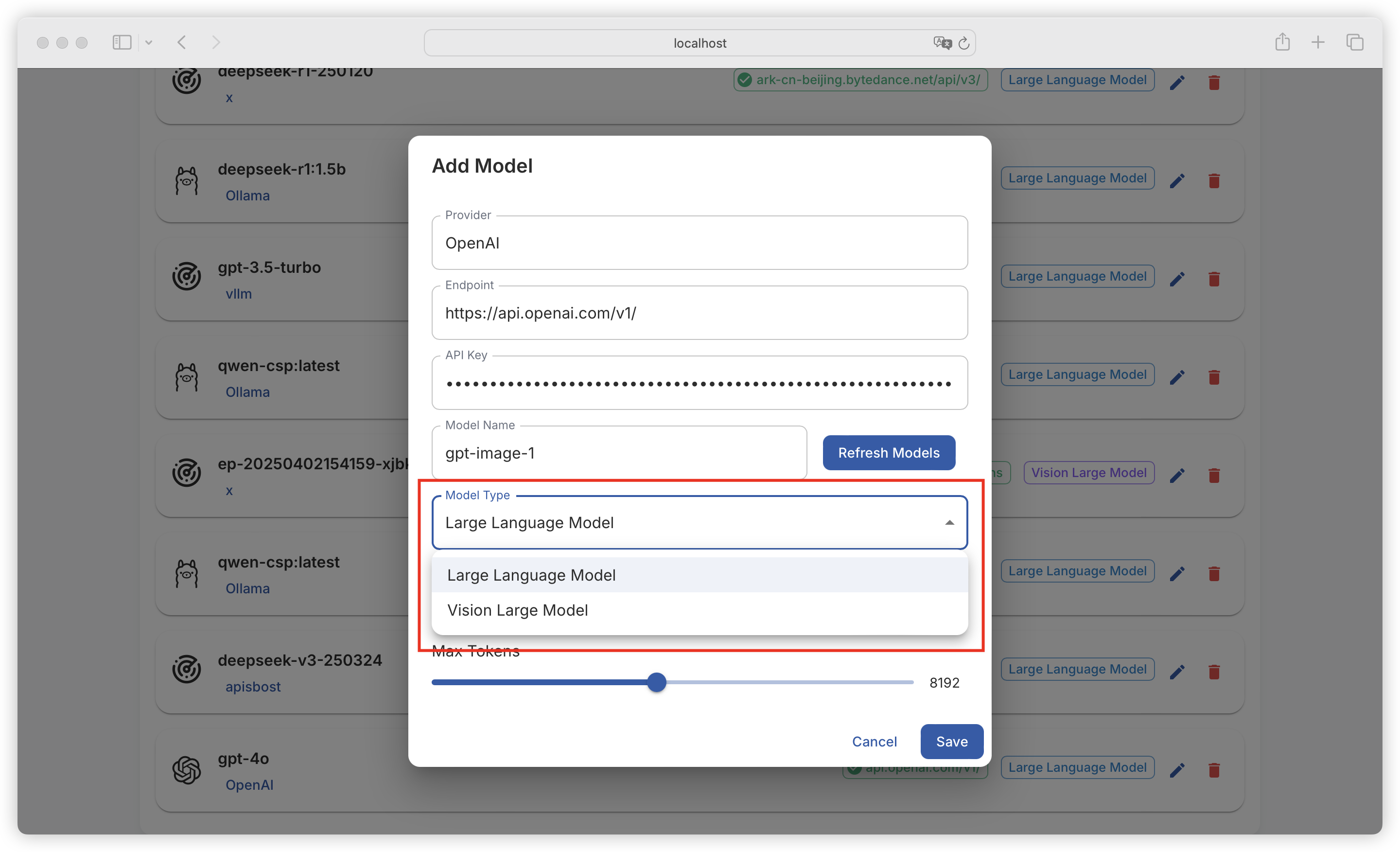
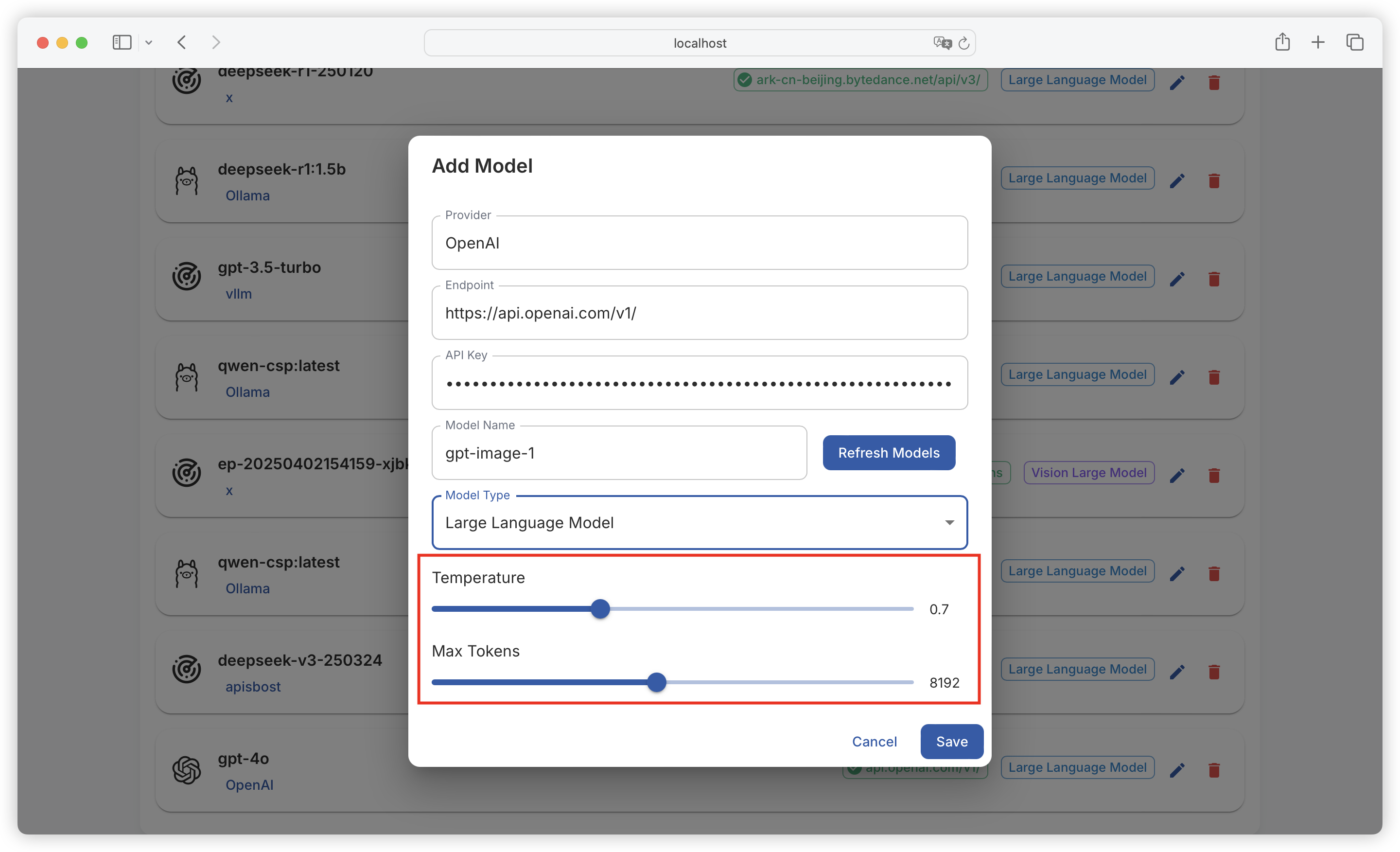
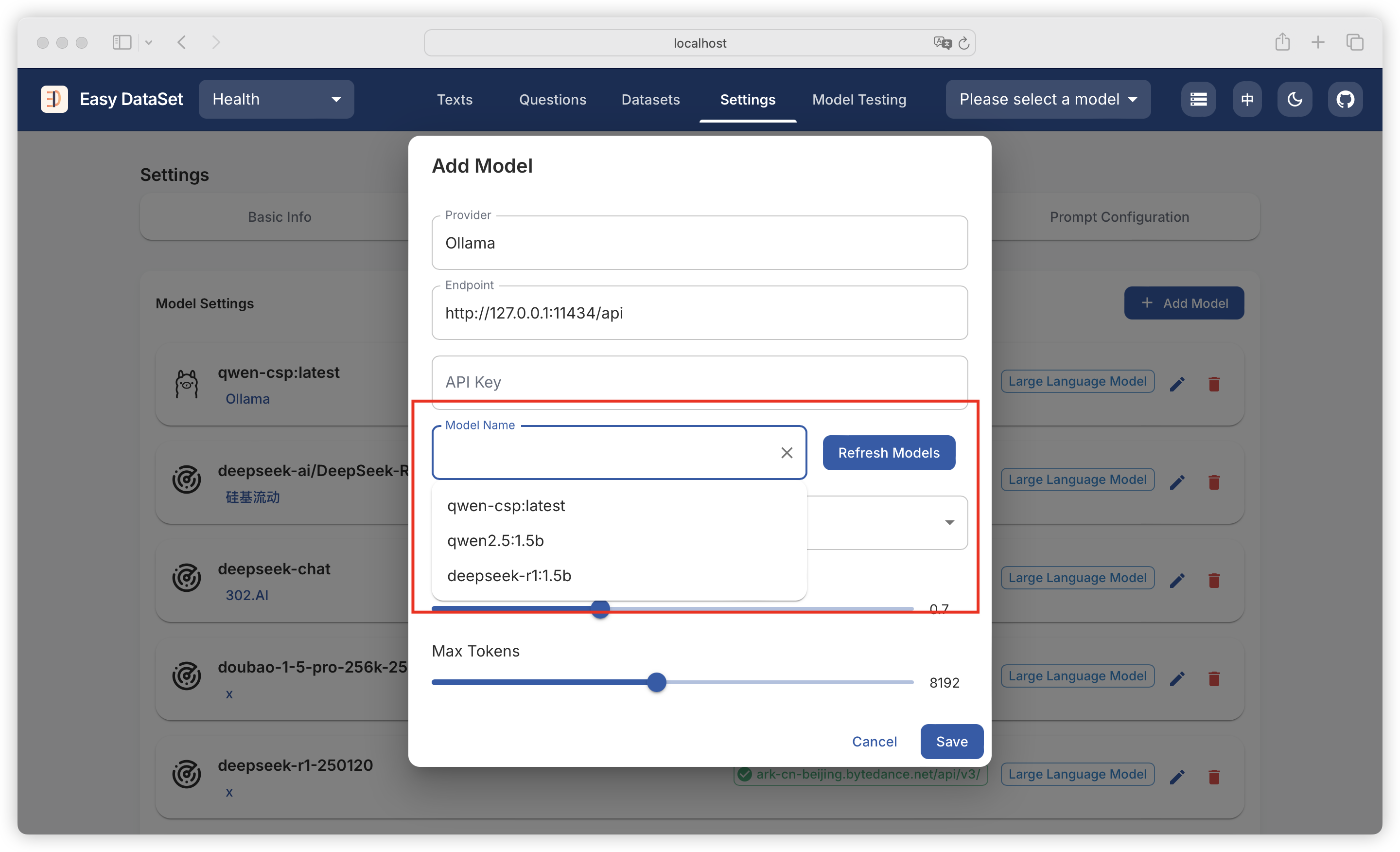
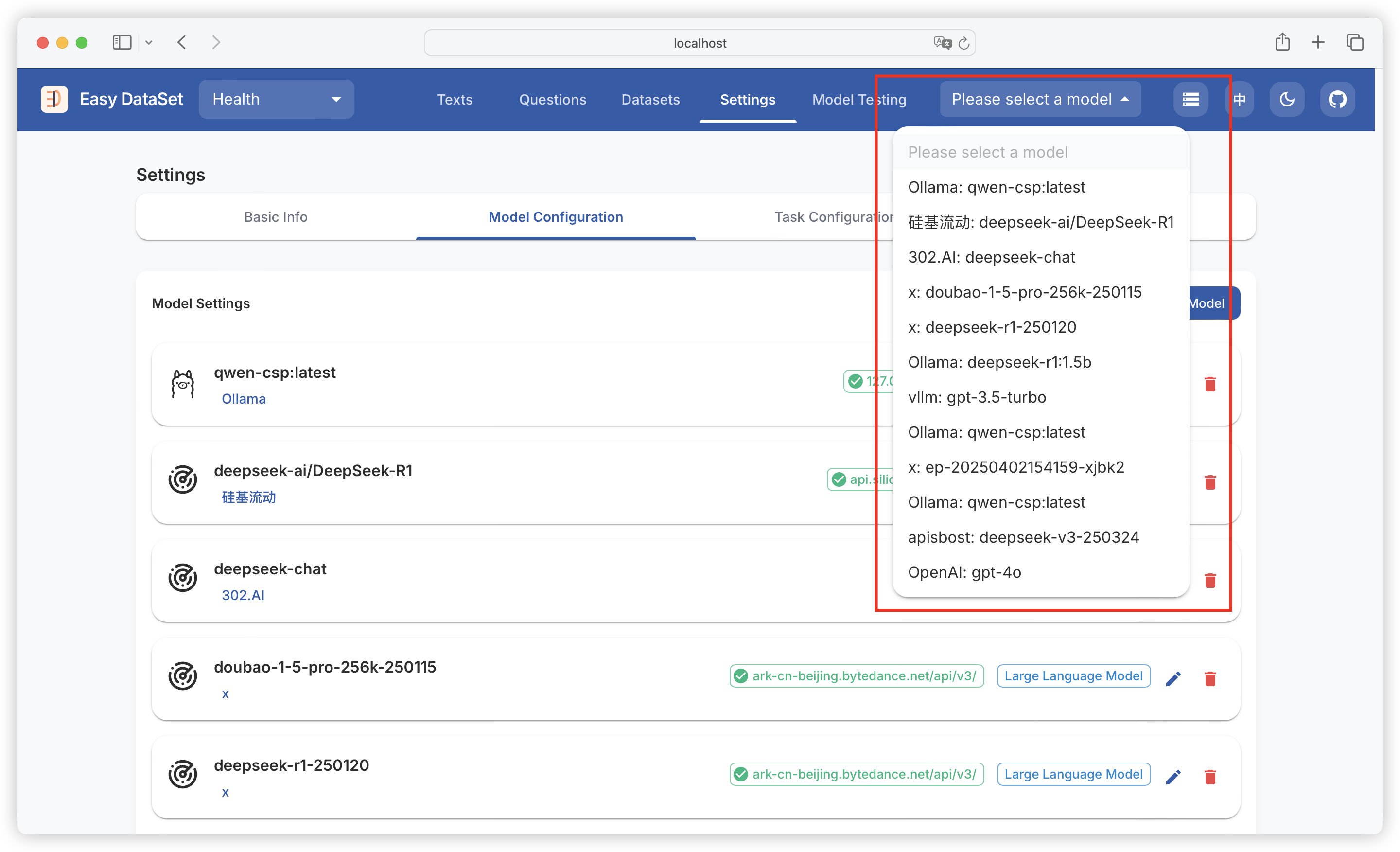
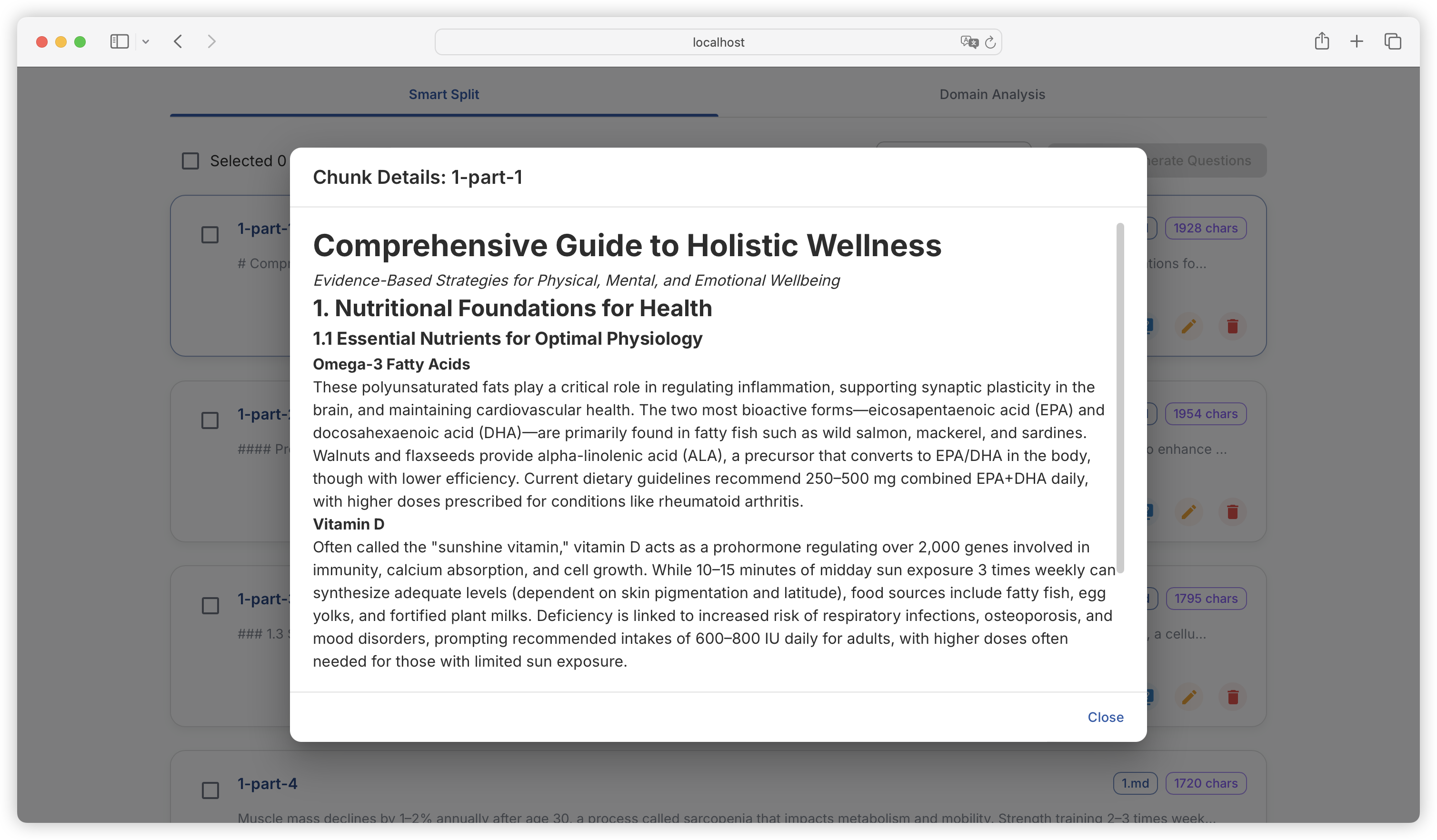
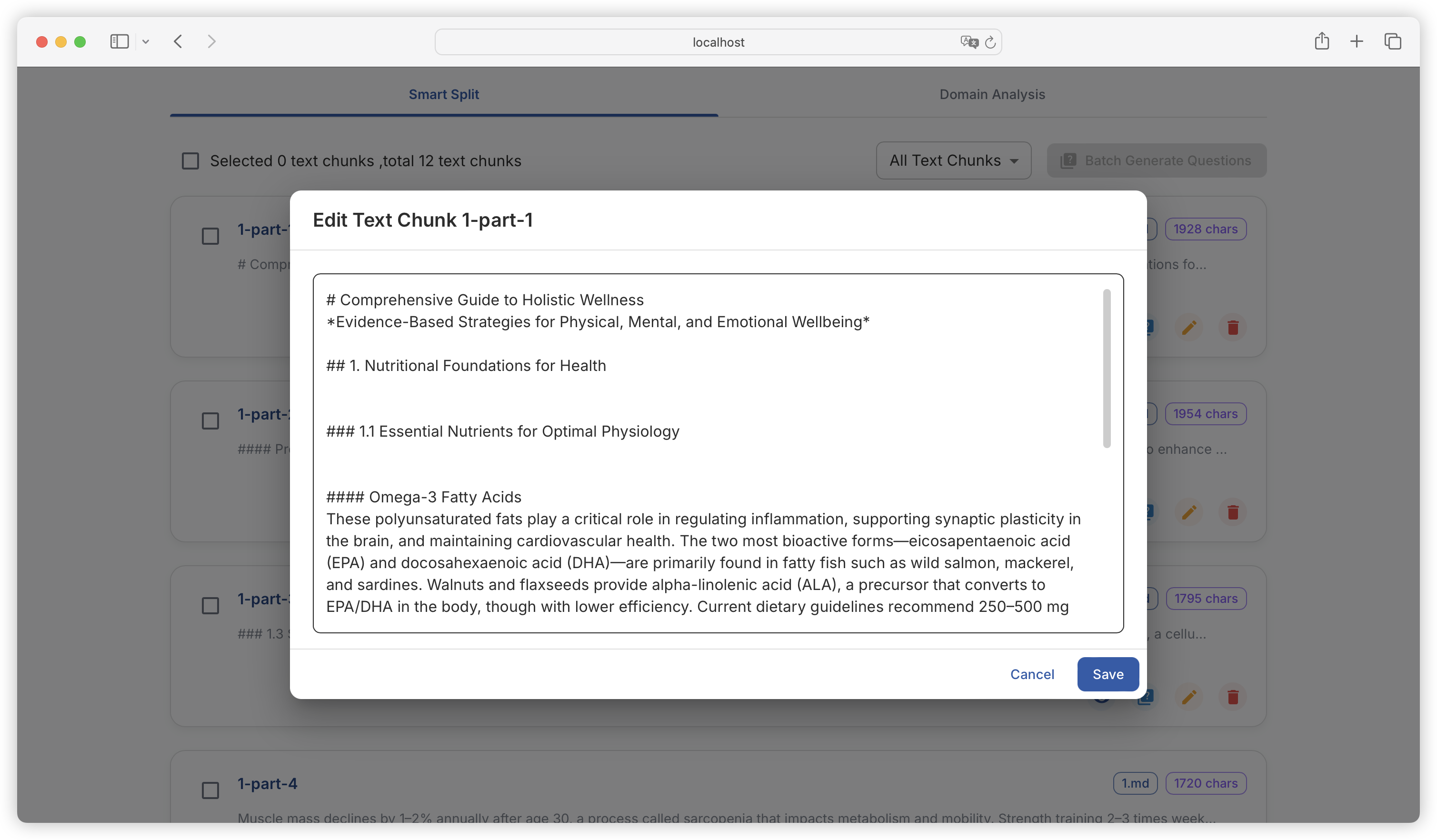
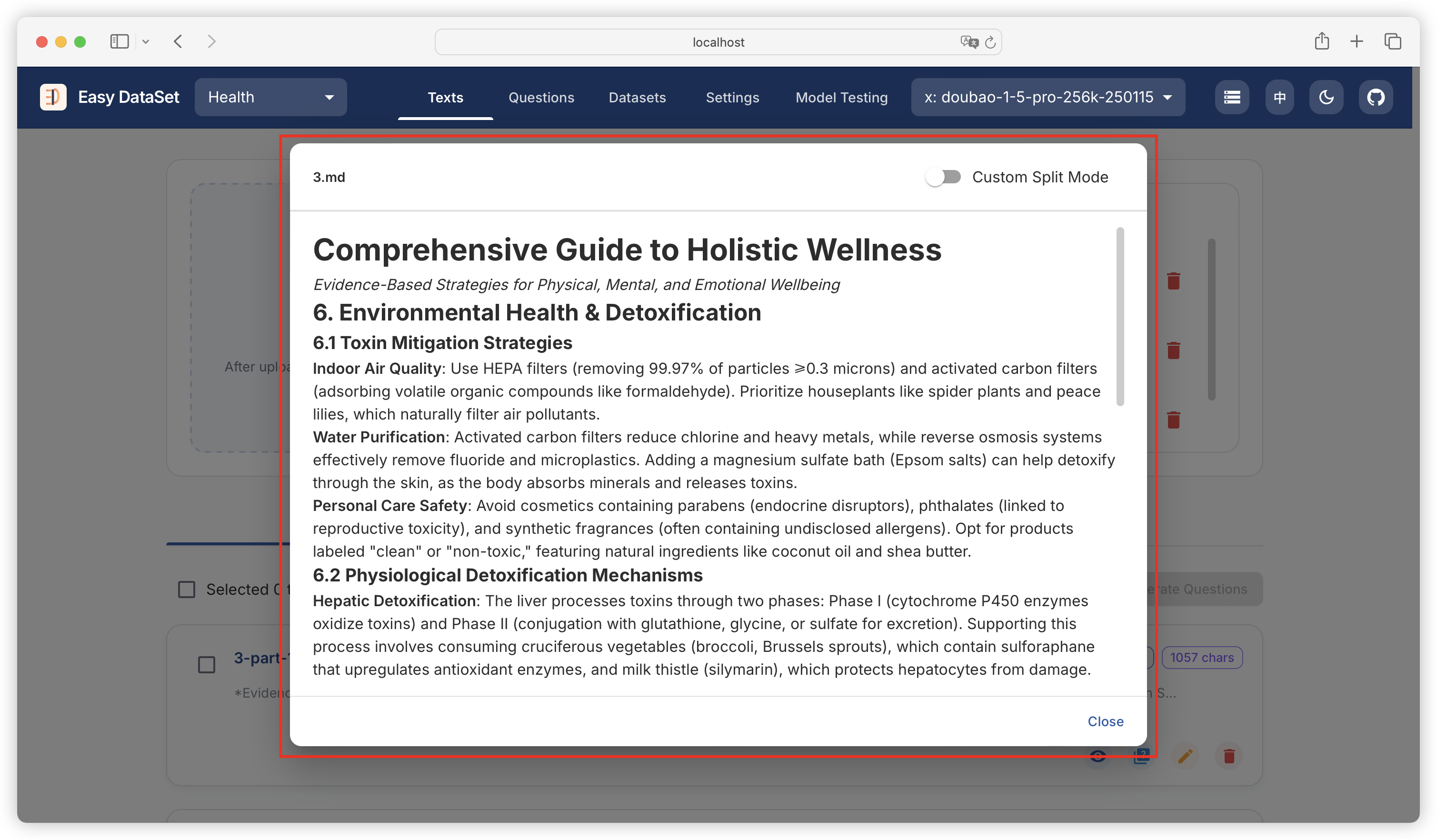
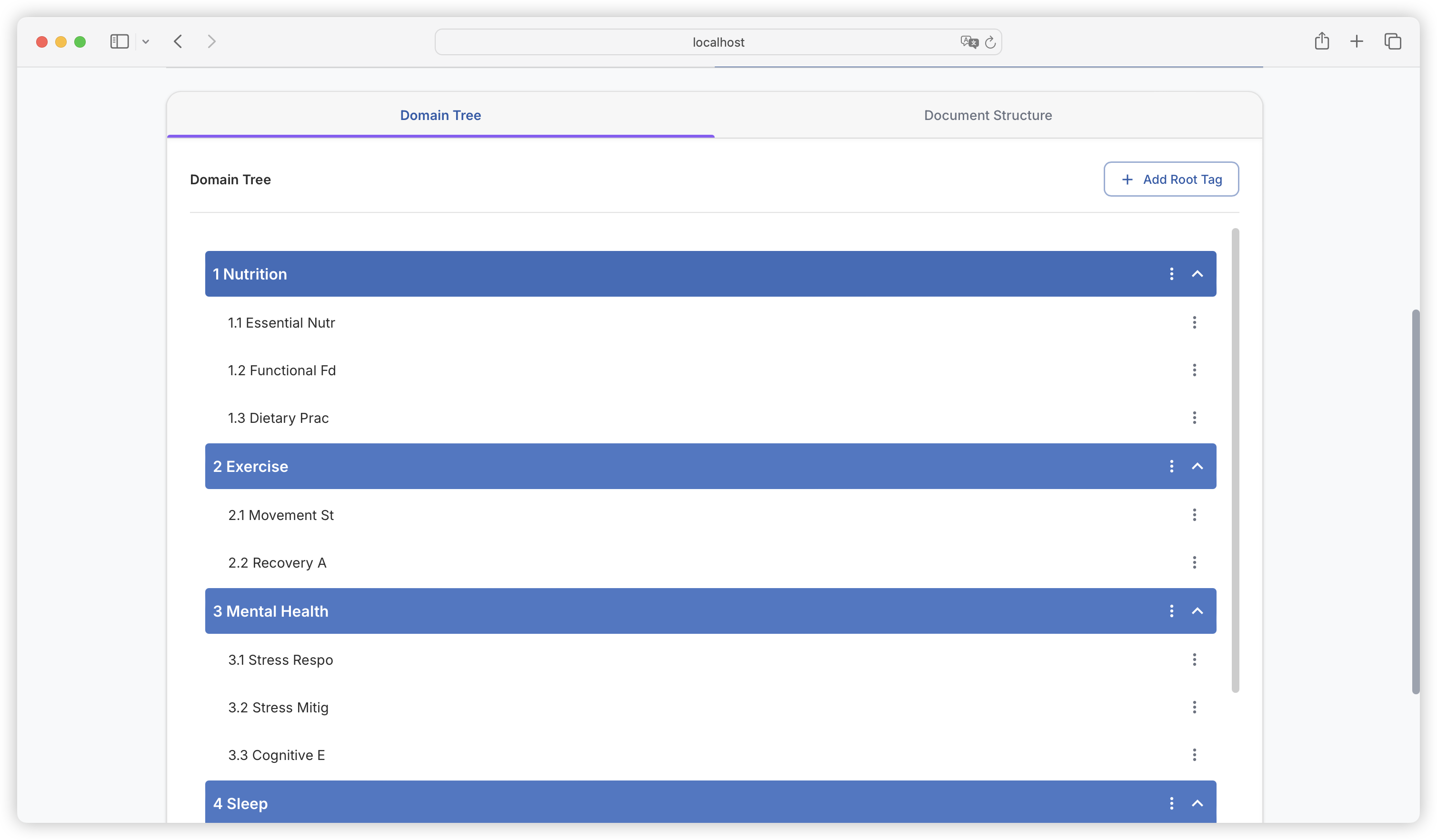
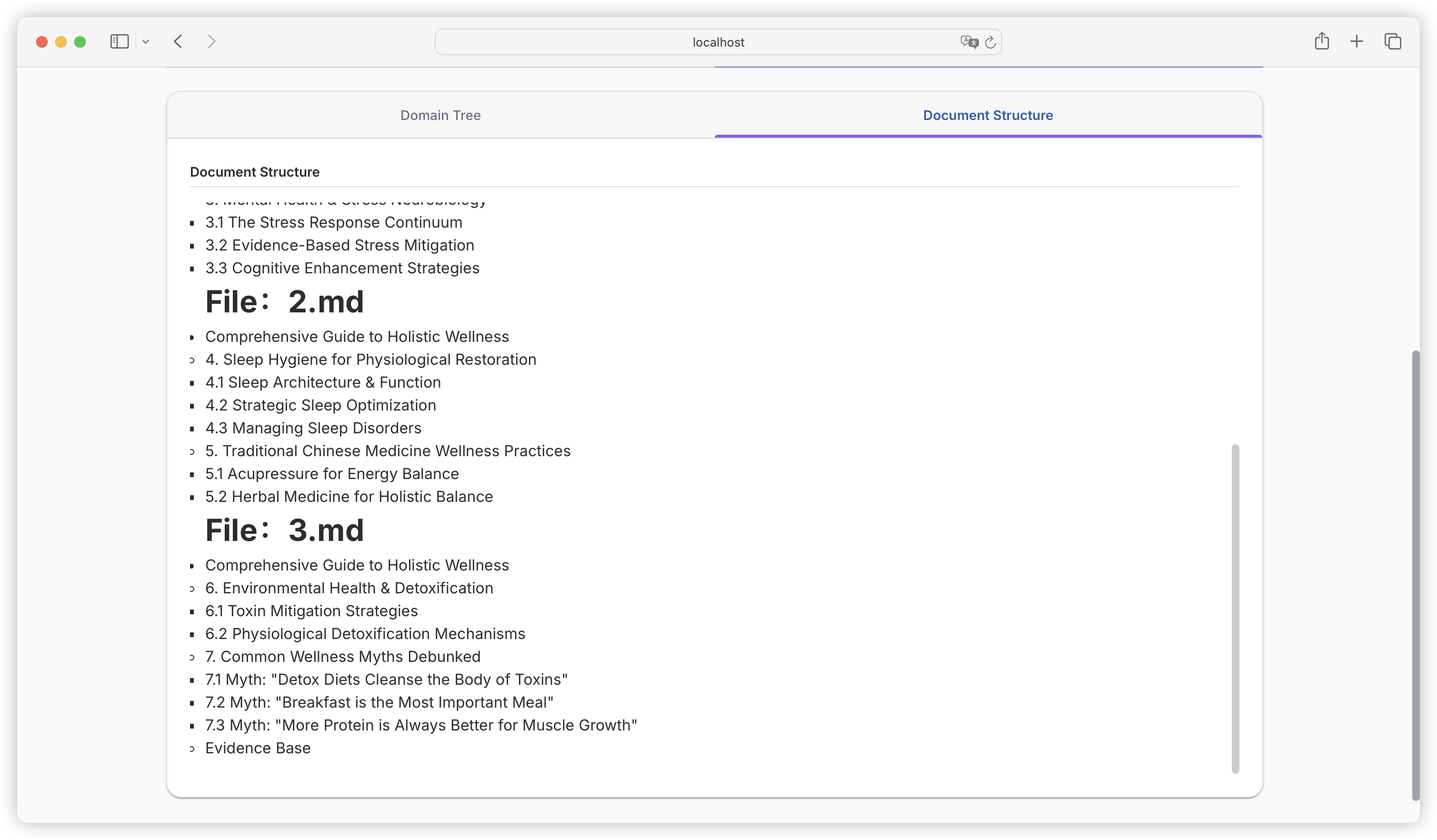
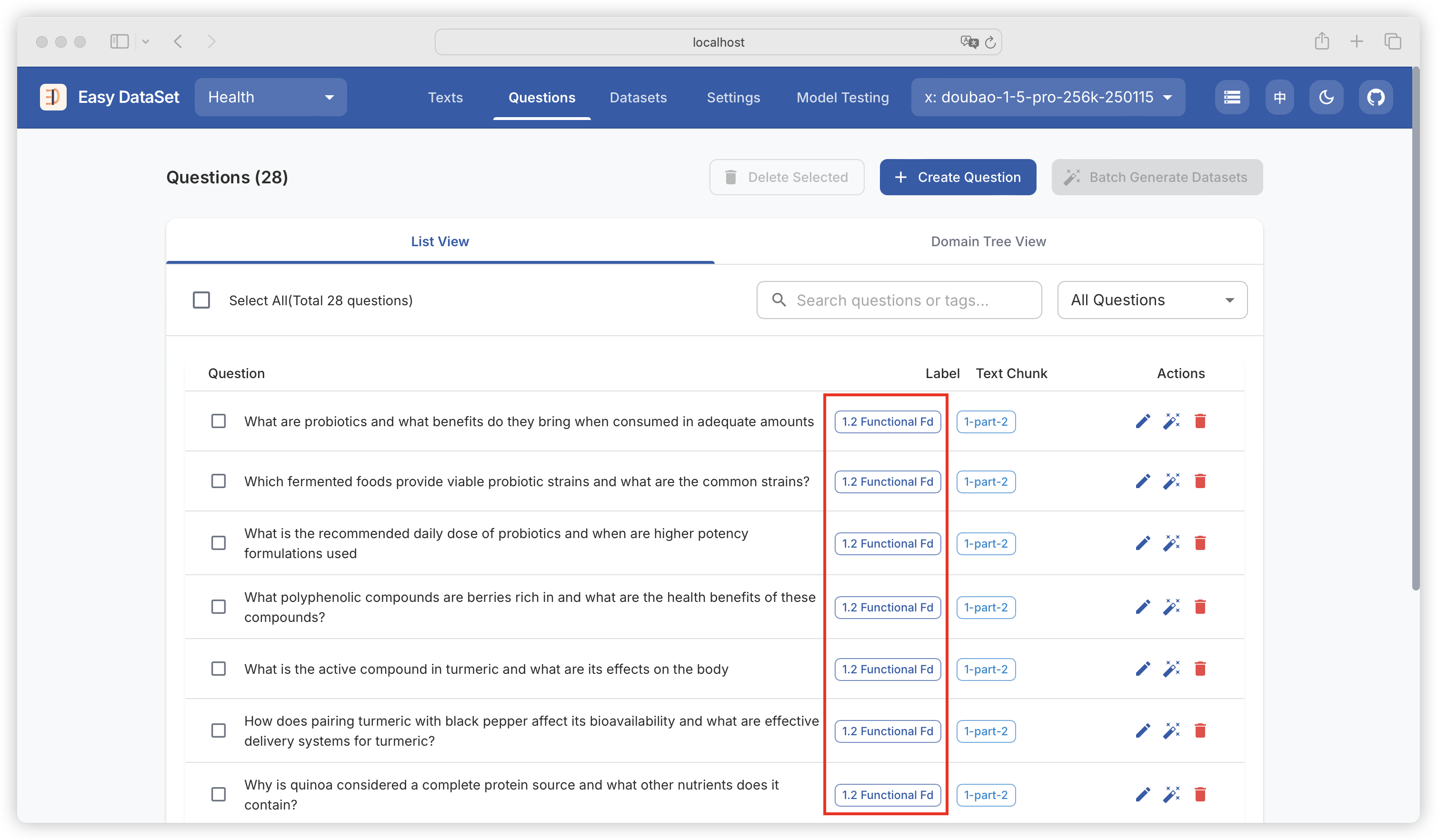
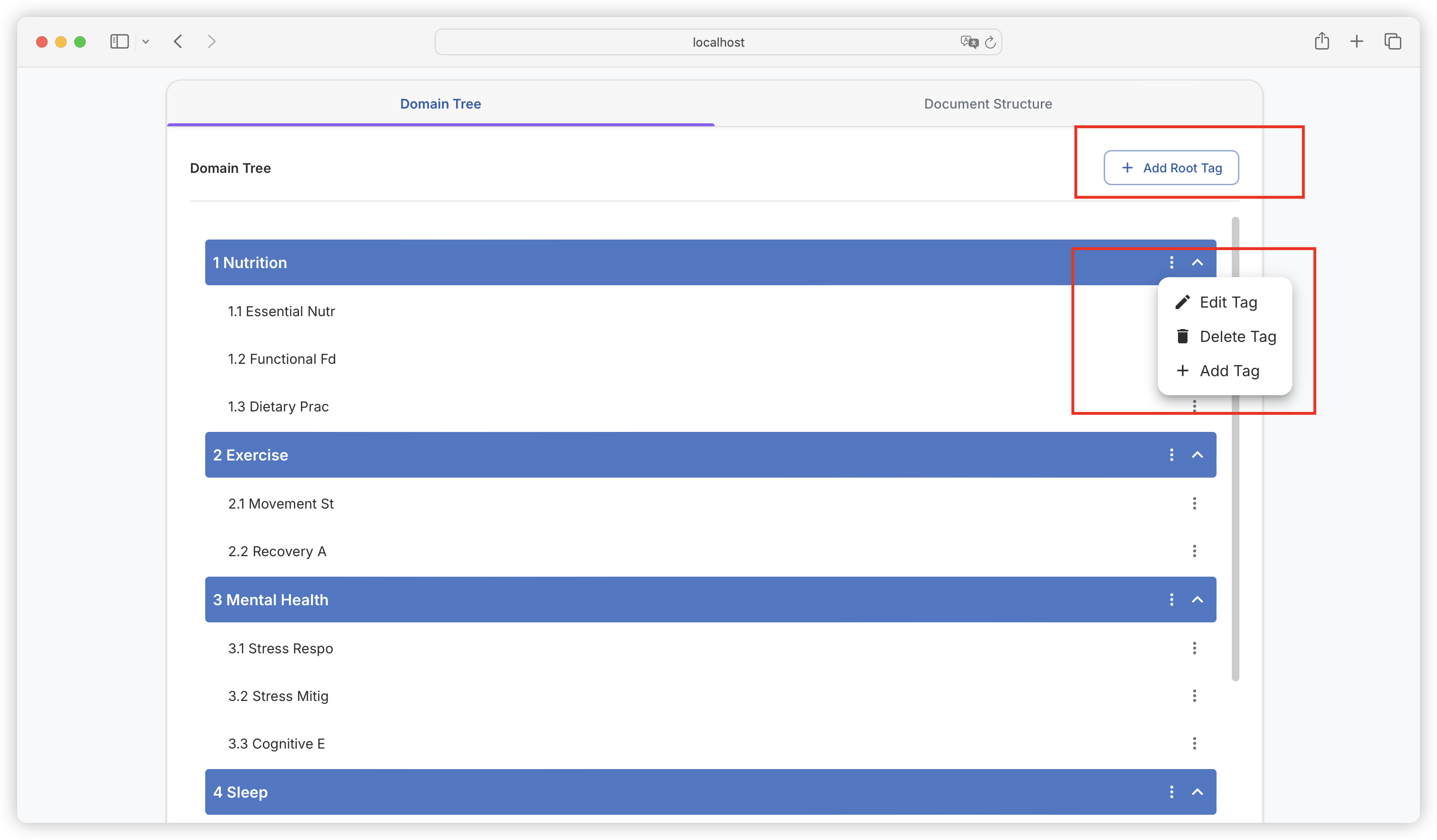
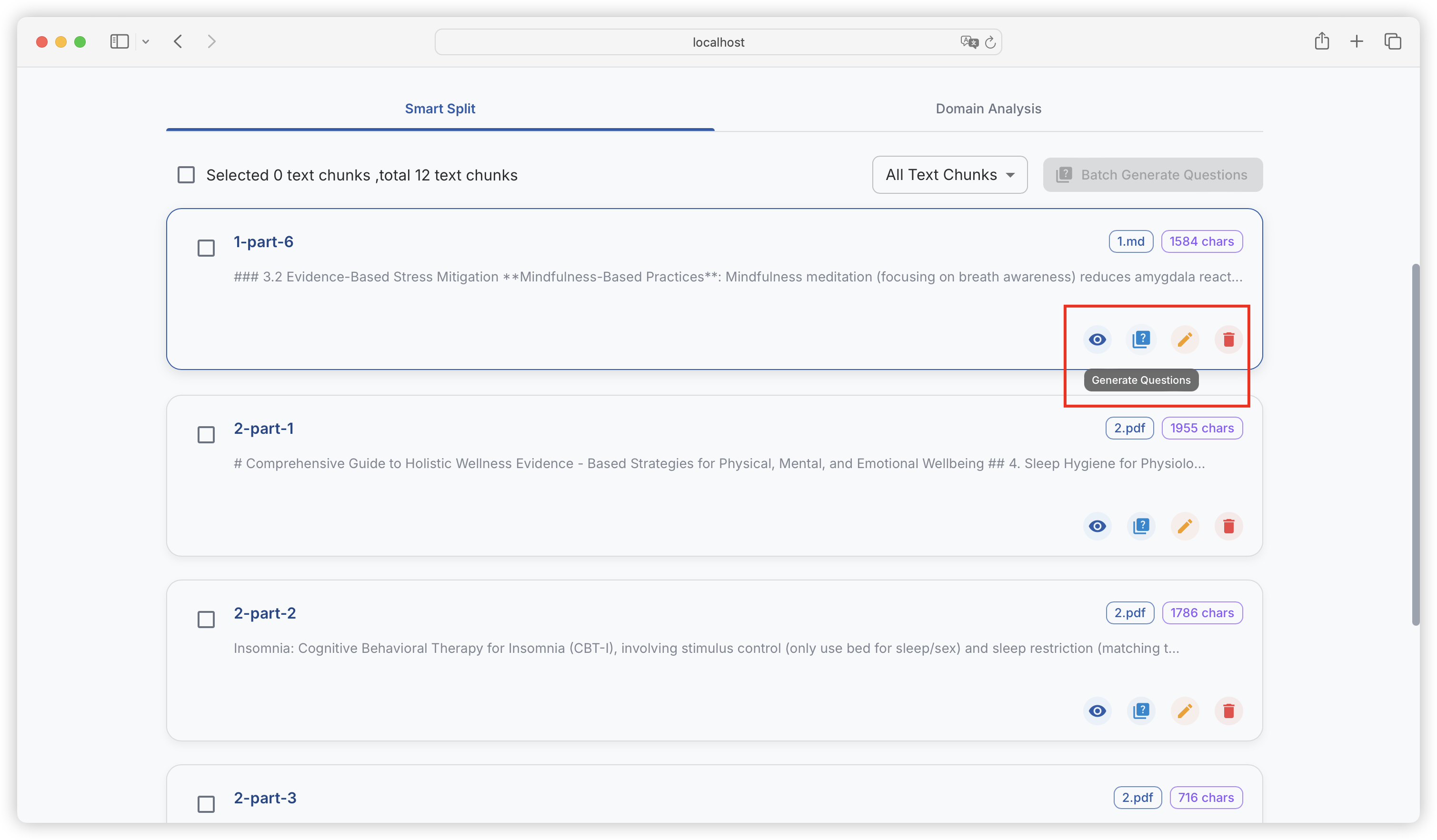
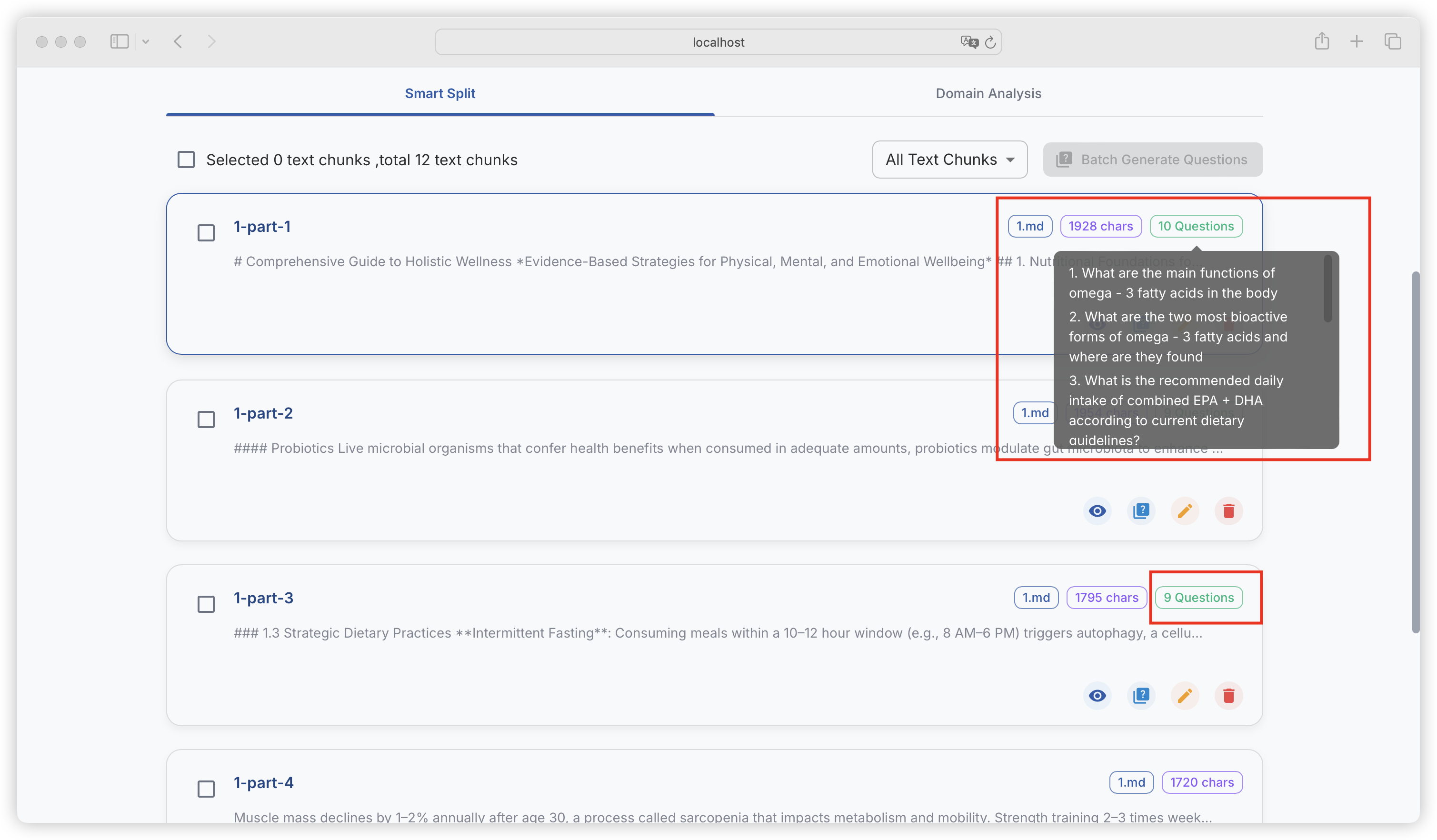
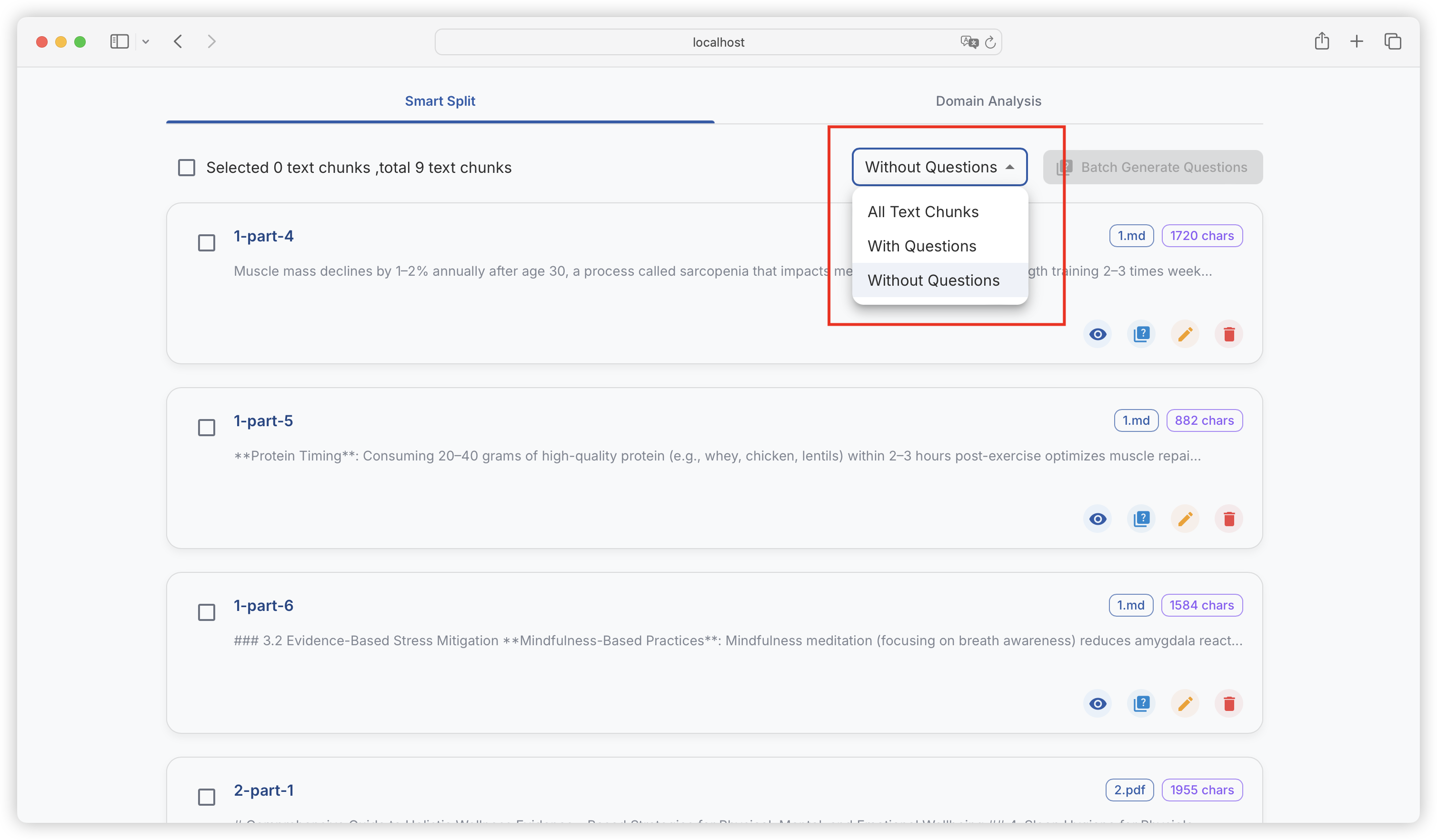
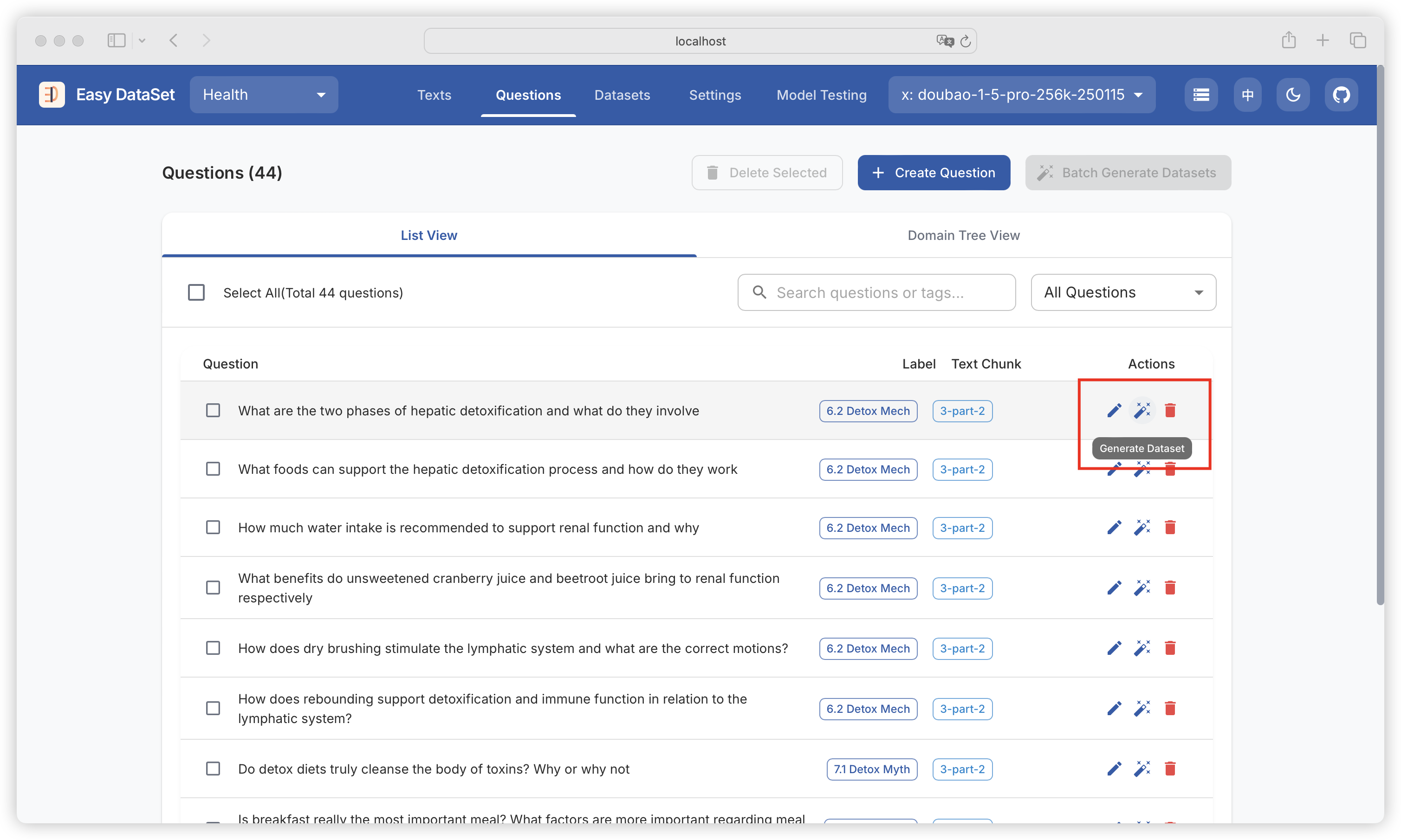
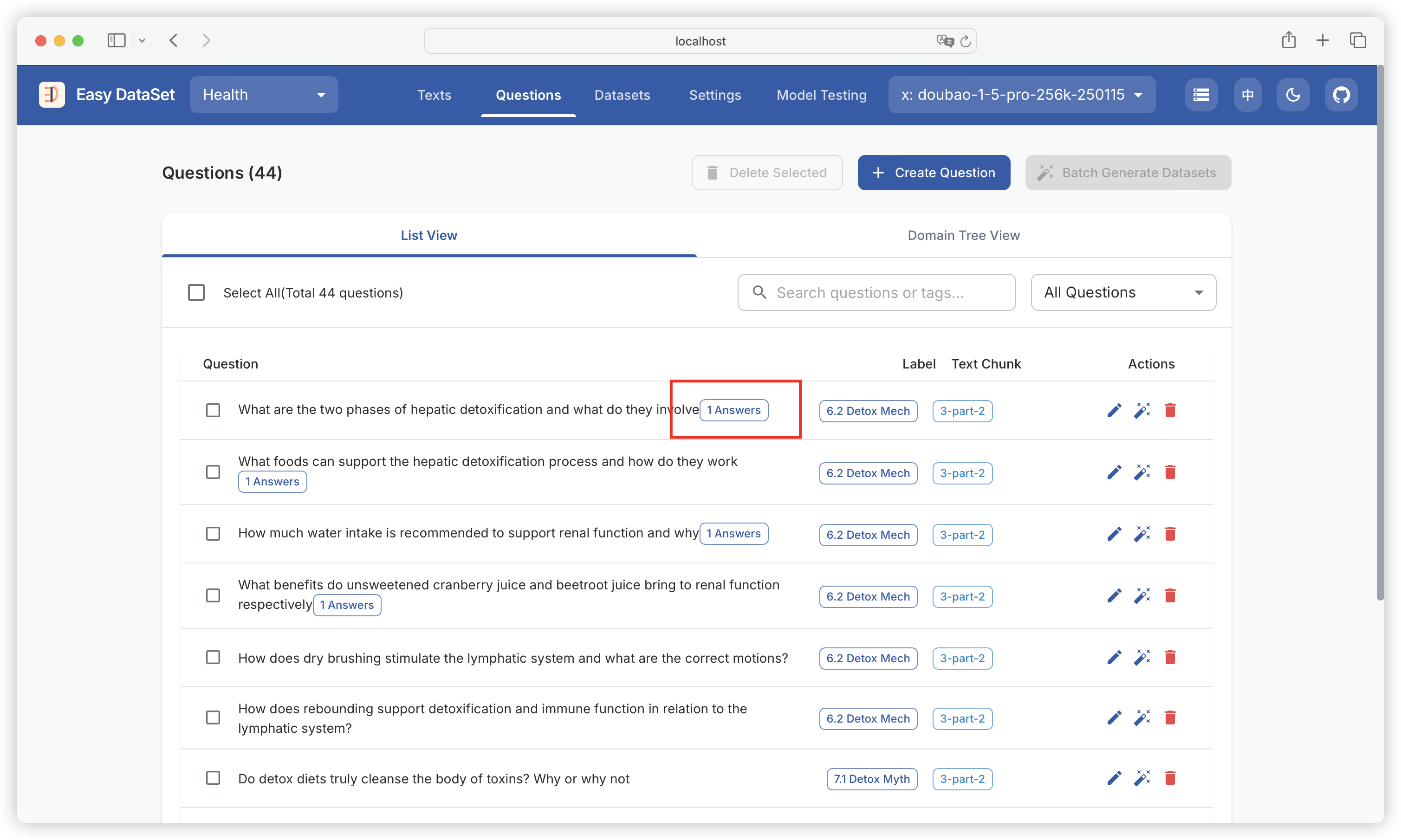
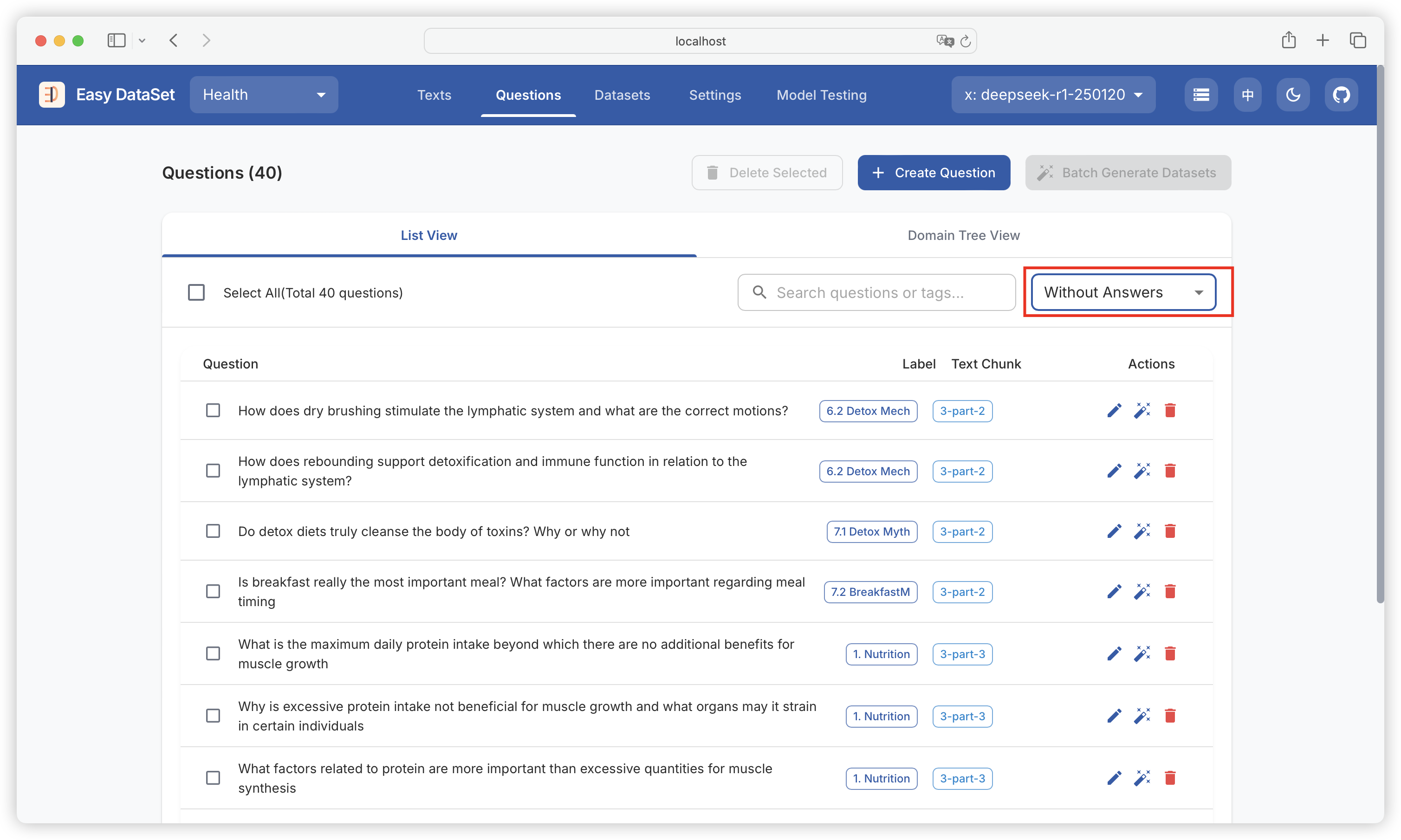
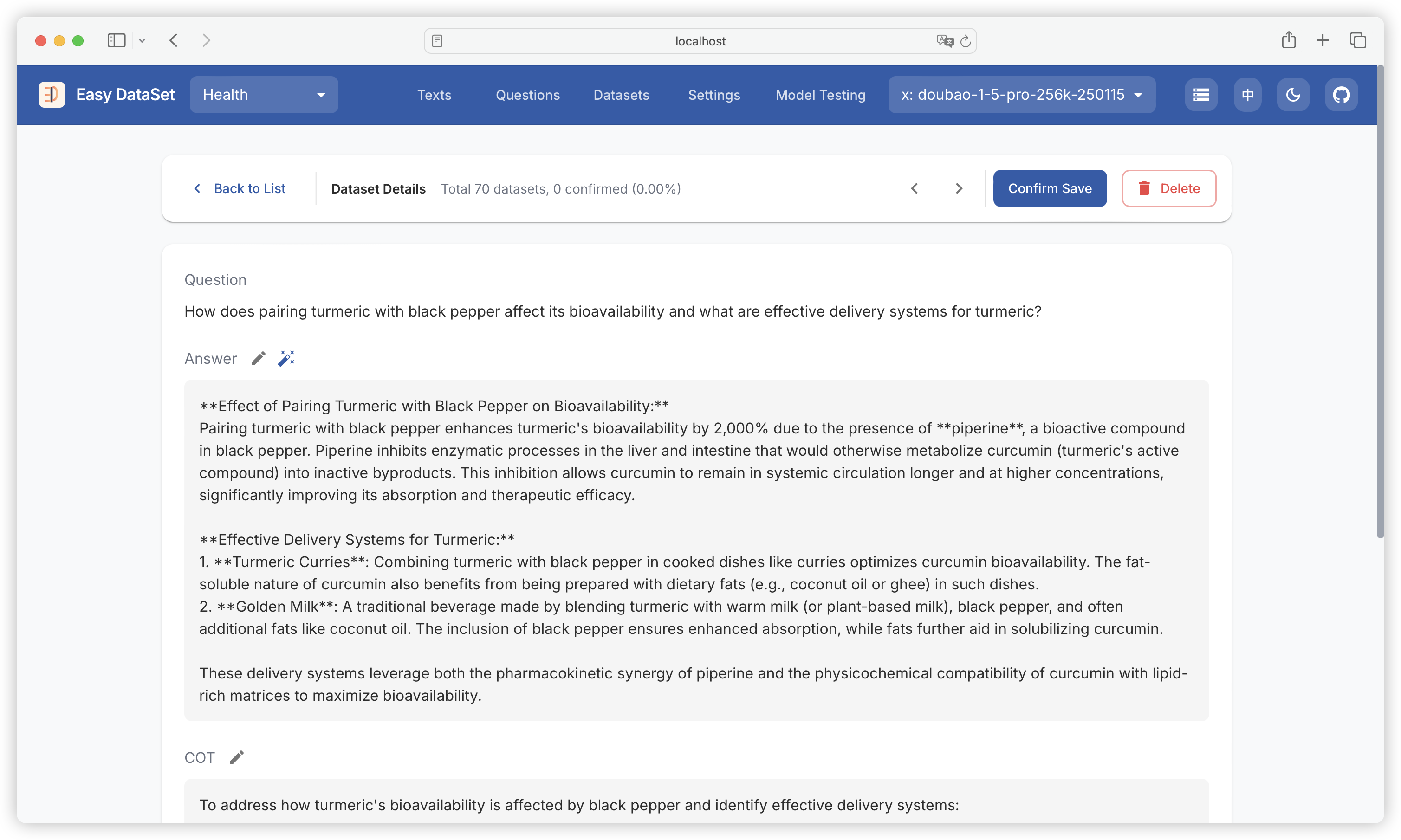
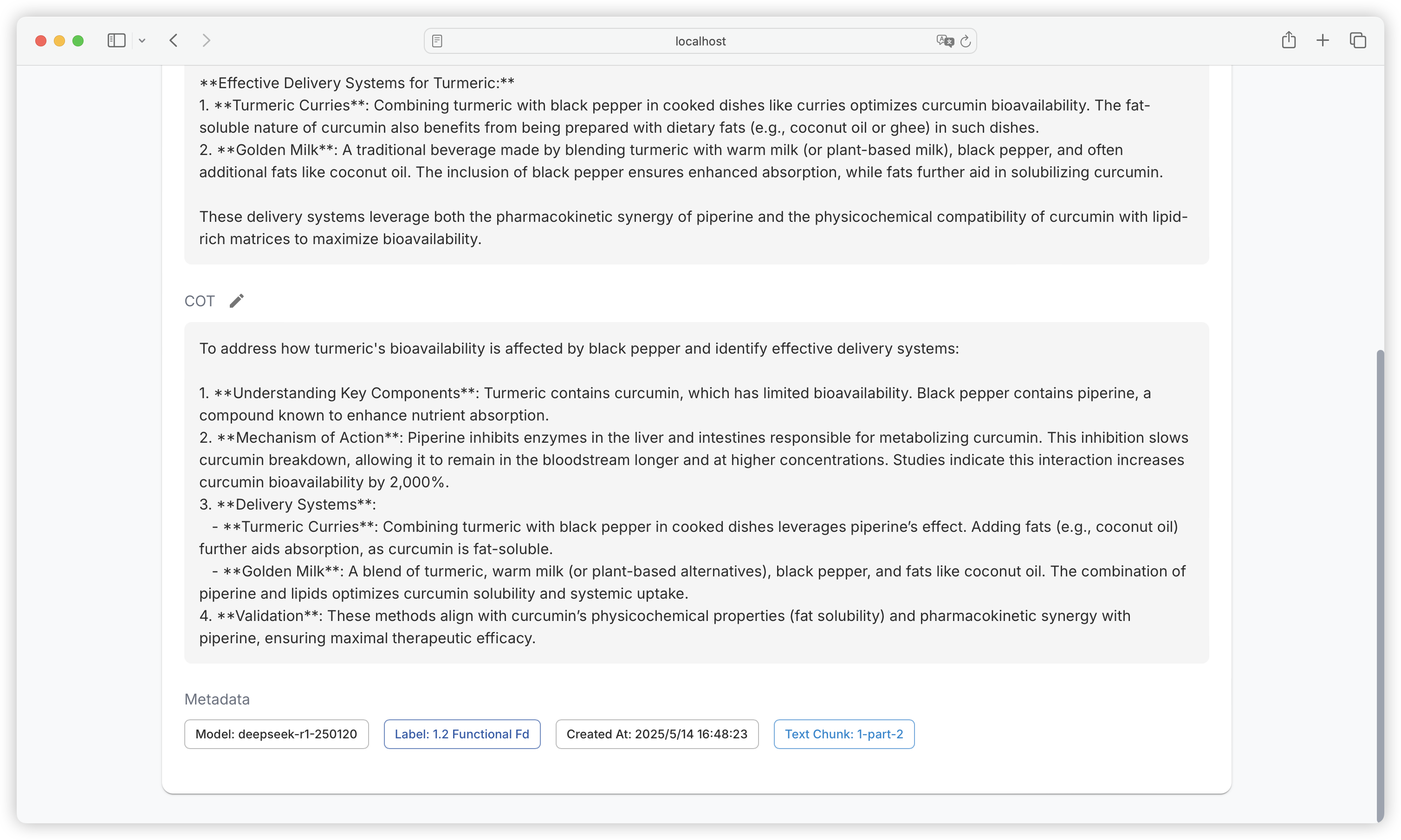
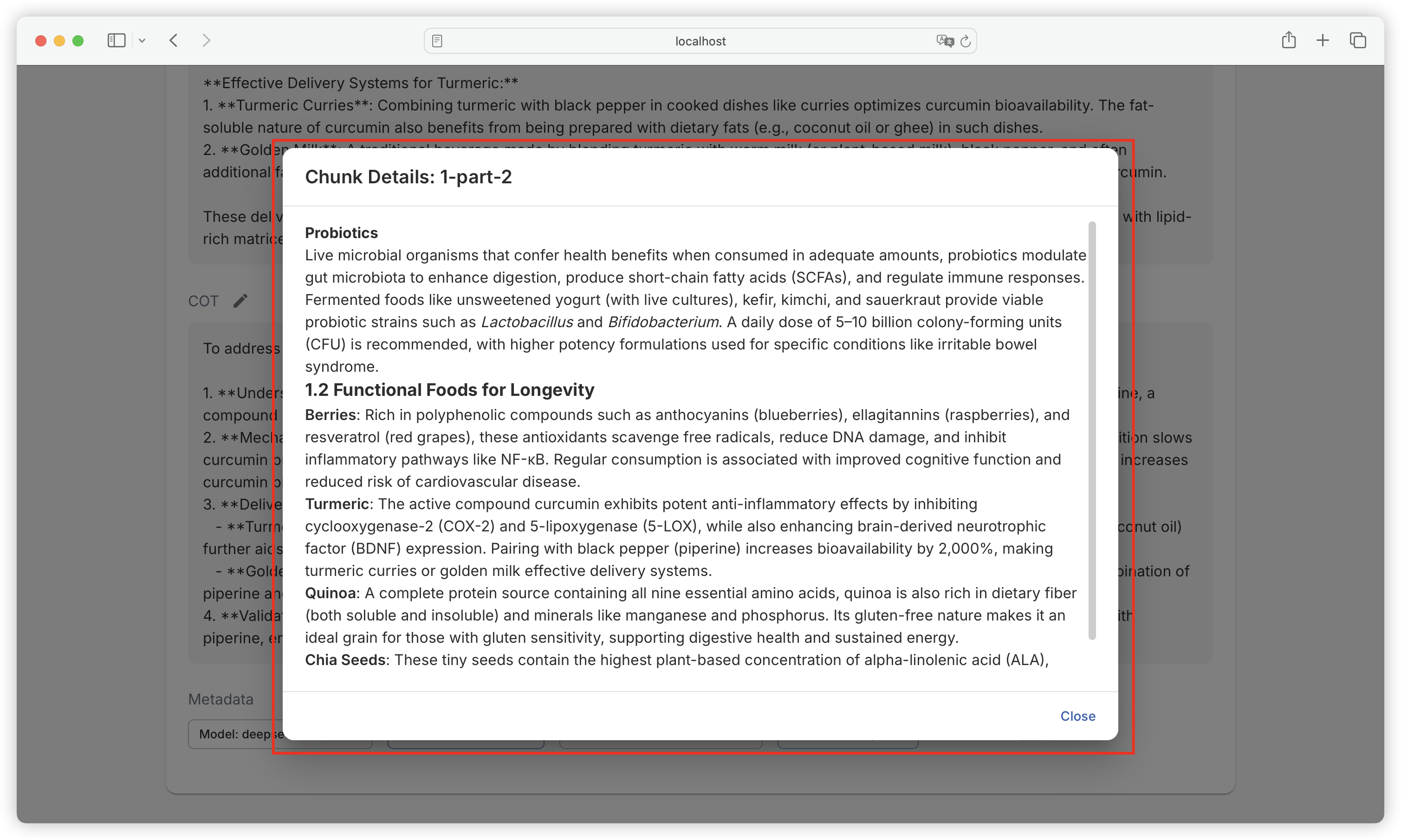
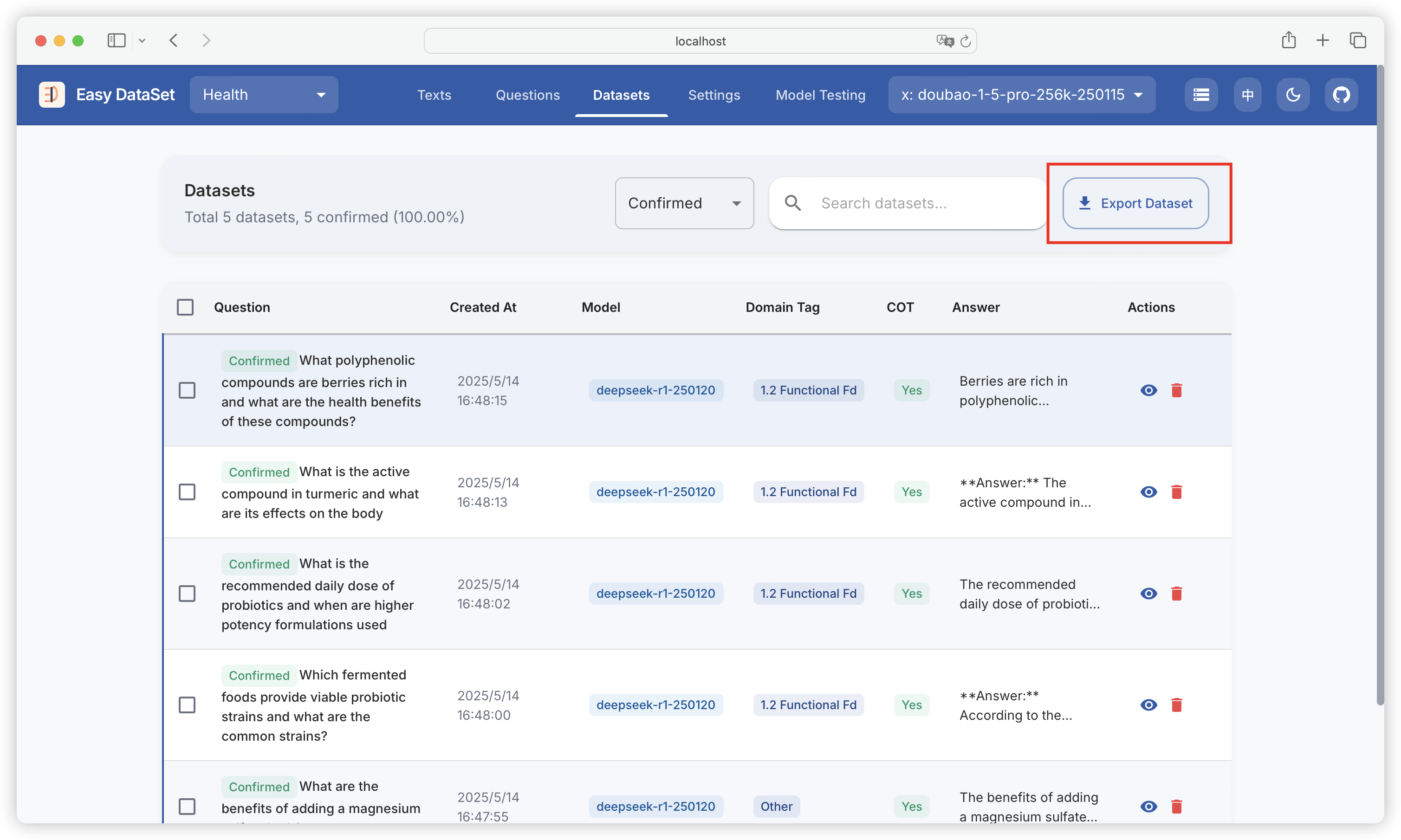
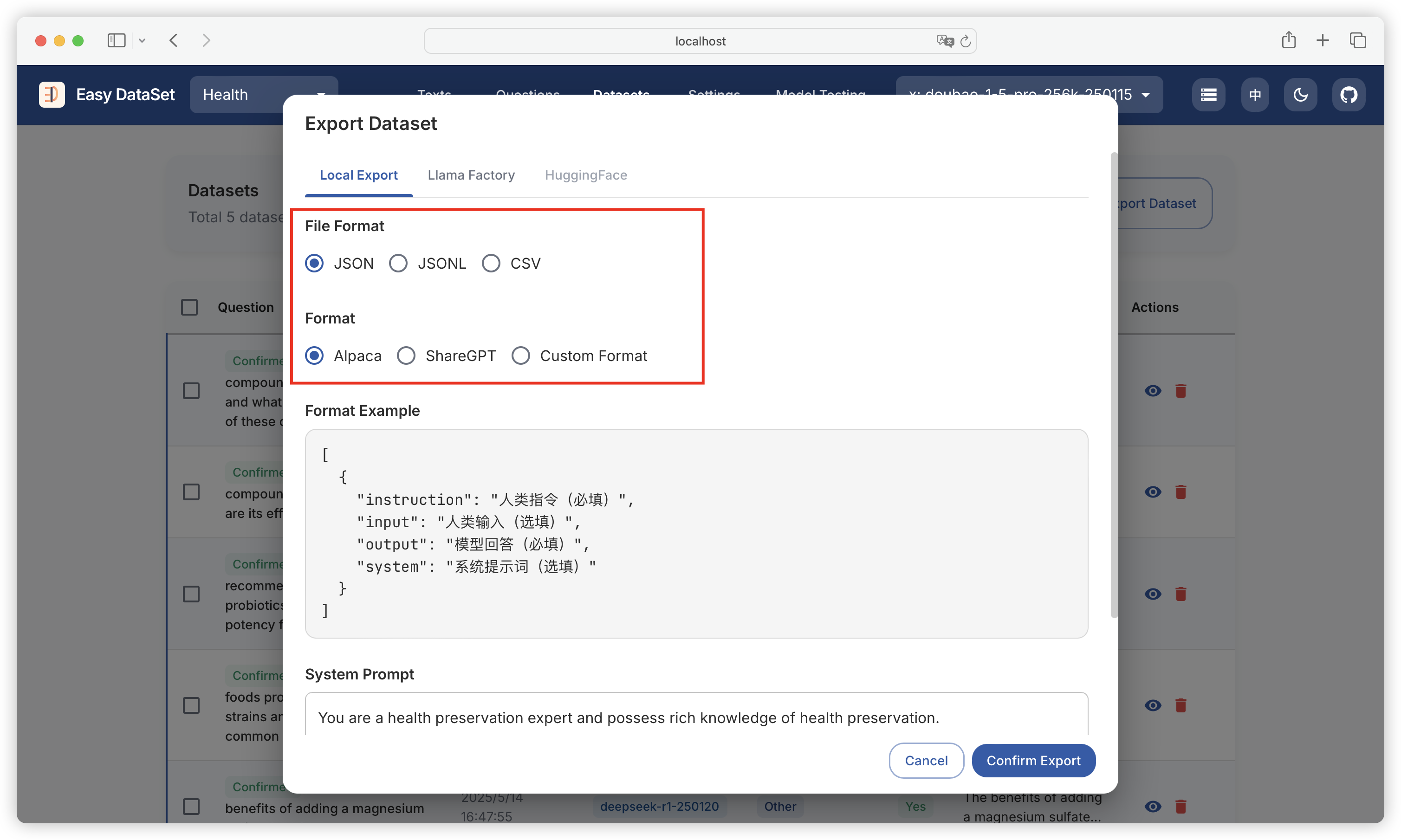
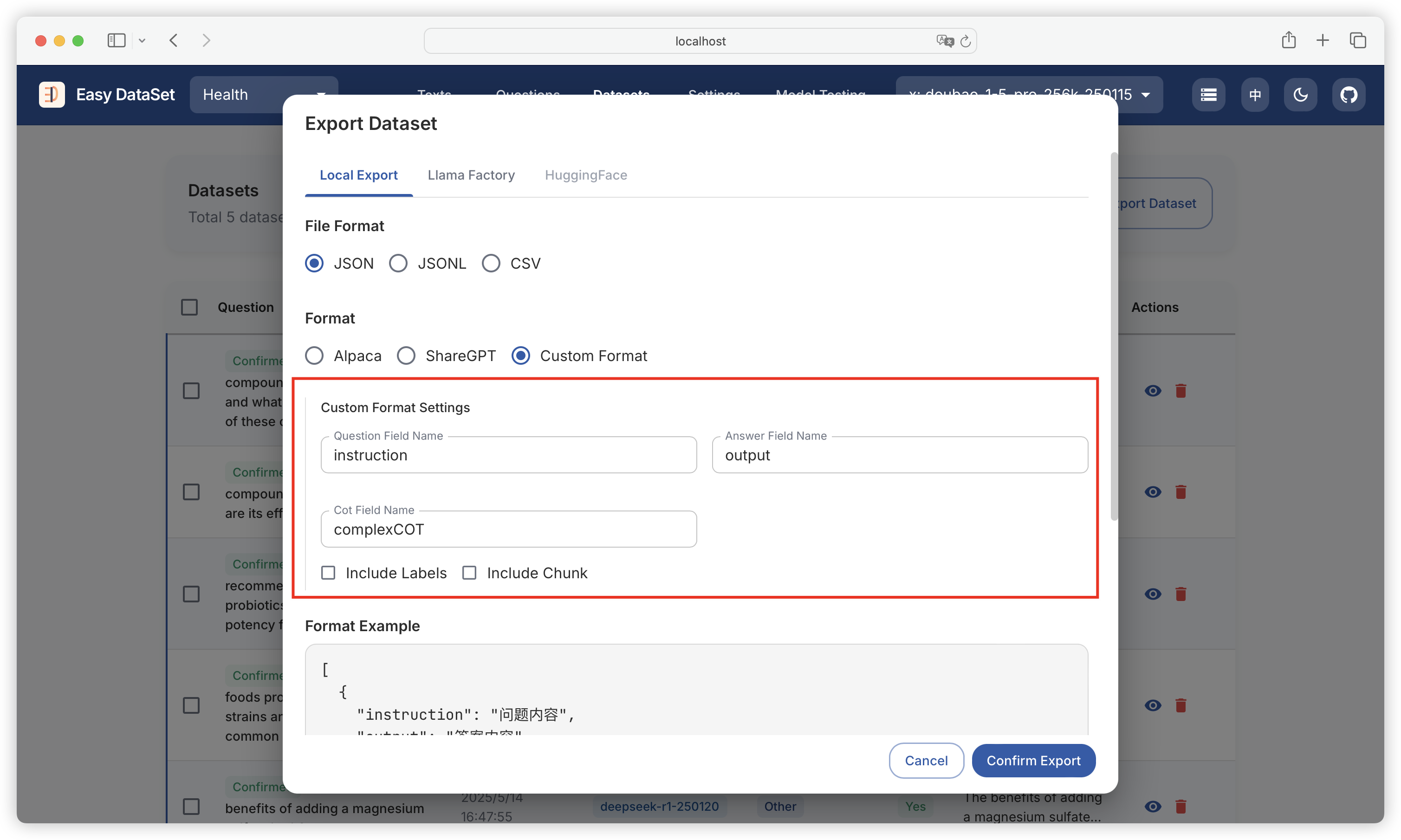
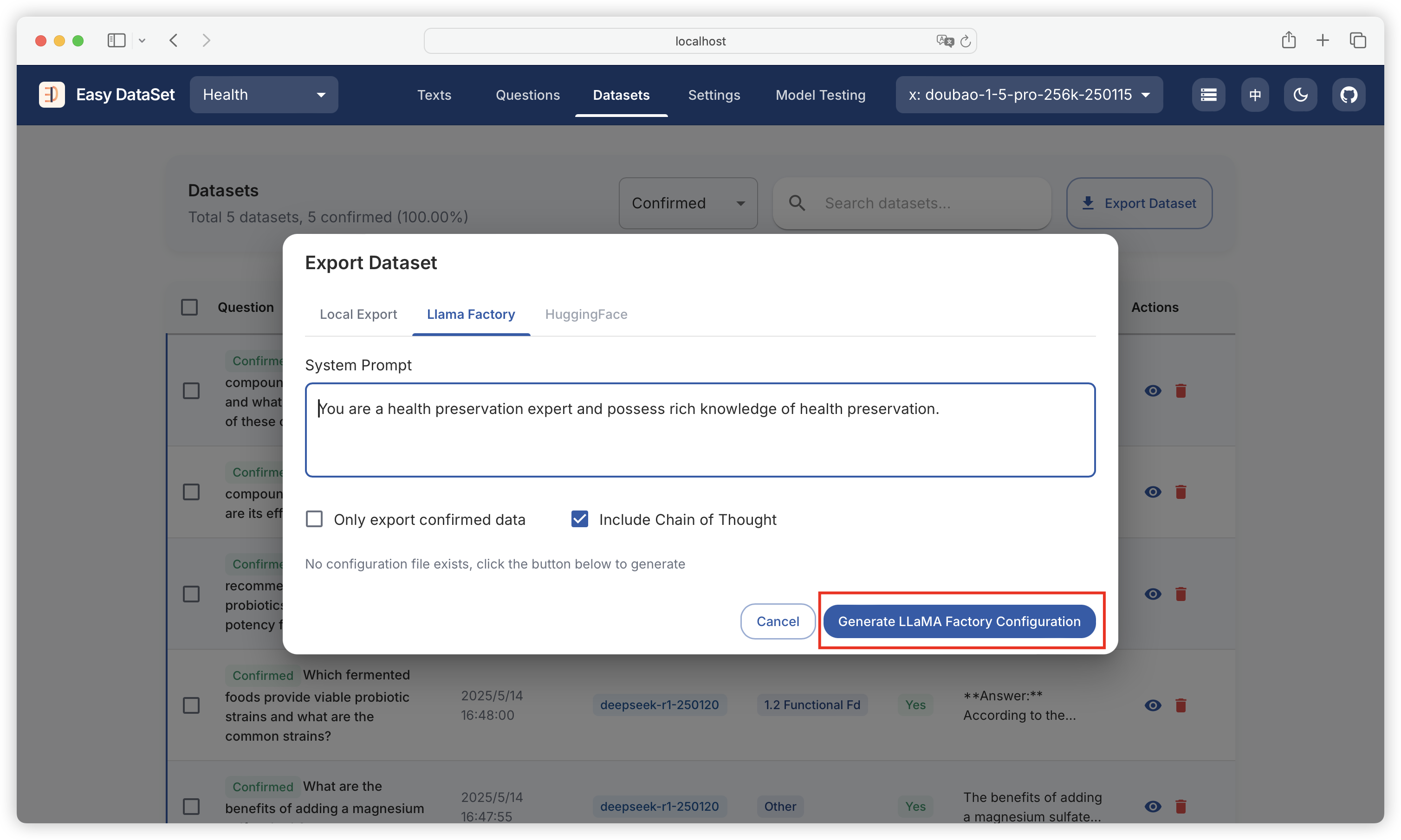
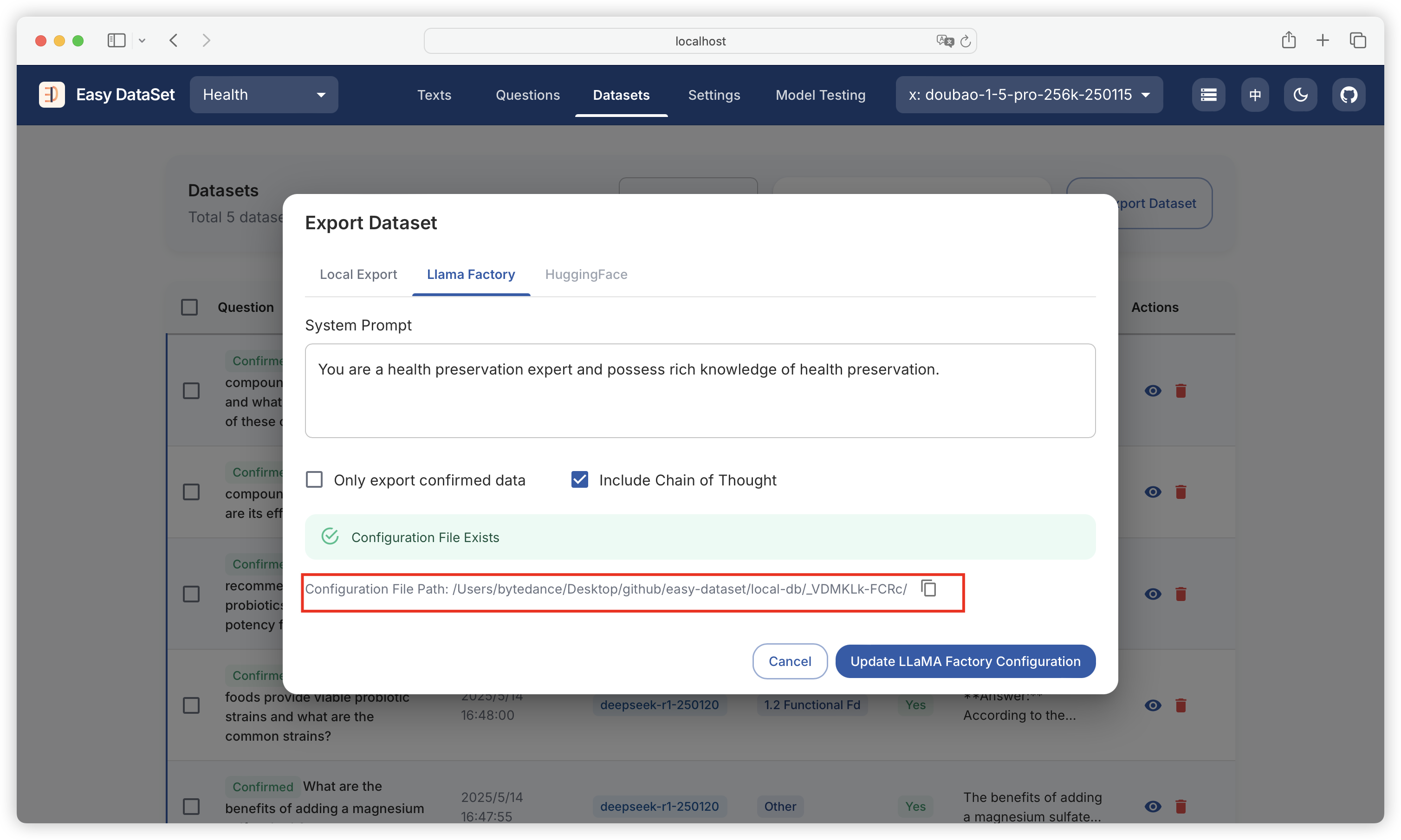
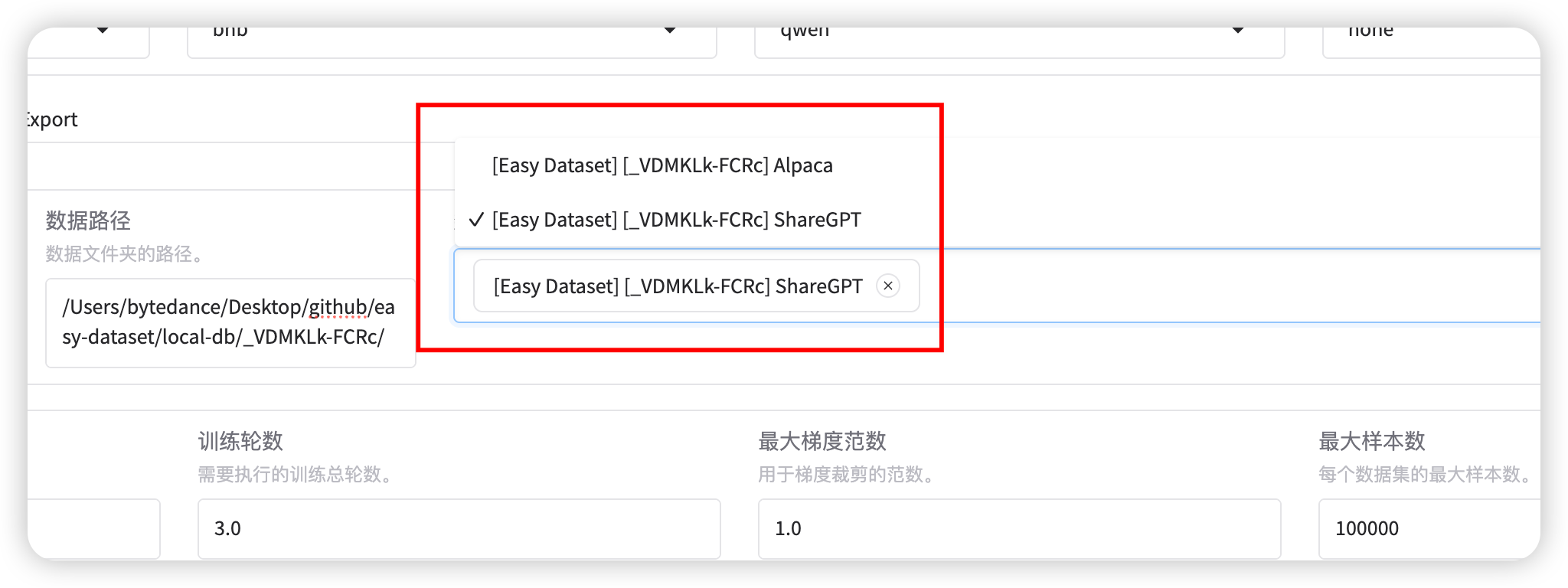

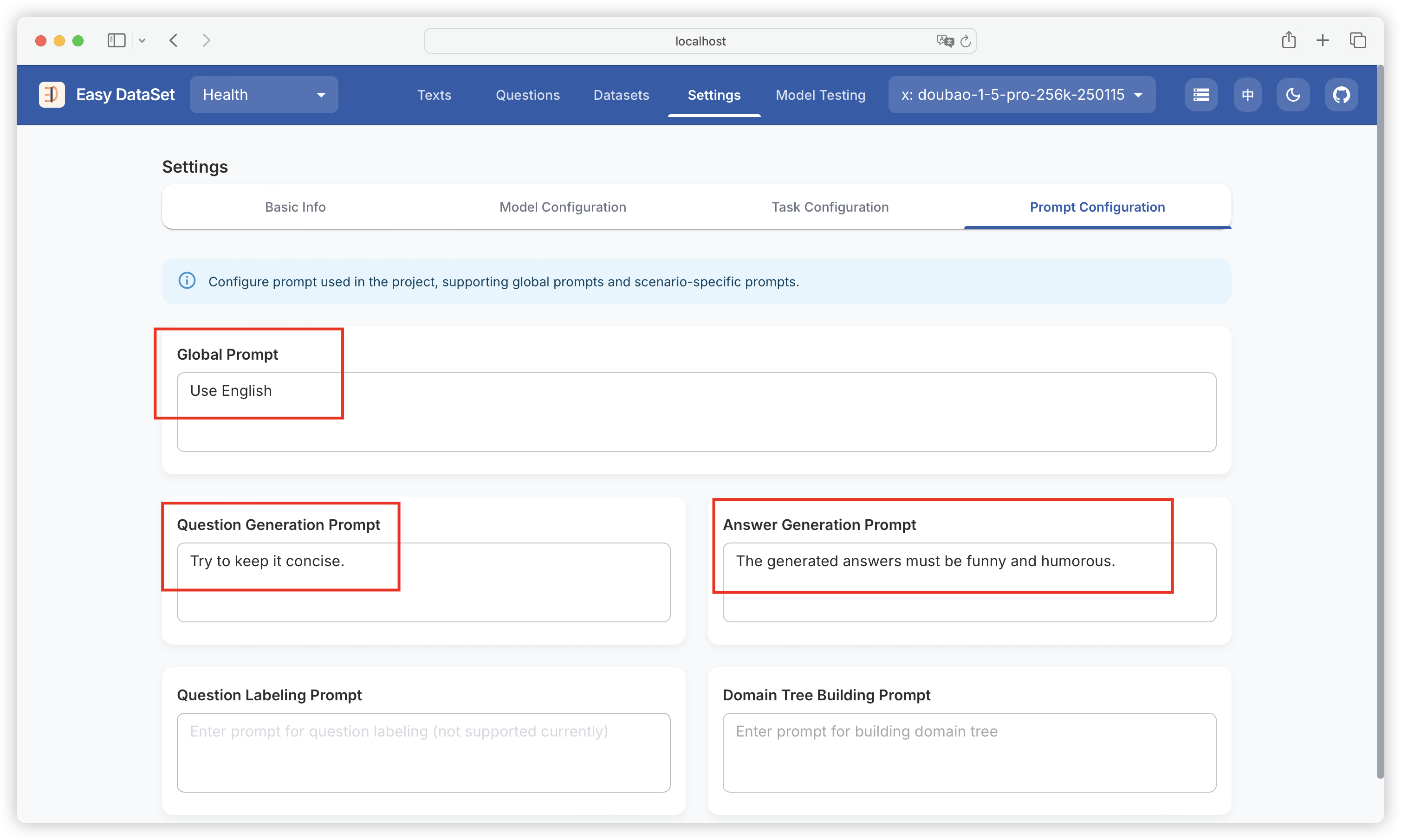

















| Comparison Dimension | Alpaca Format | ShareGPT Format |
| Core Design Purpose | Single-turn instruction-driven tasks (e.g., Q&A, translation, summarization) | Multi-turn dialogues and tool invocation (e.g., chatbots, API interactions) |
| Data Structure | JSON objects centered around instruction, input, output | Multi-role dialogue chains (human/gpt/function_call/observation) with conversations list as core |
| Dialogue History Handling | Records history through history field (format: [["instruction", "response"], ...]) | Naturally represents multi-turn dialogues through ordered conversations list (alternating roles) |
| Roles & Interaction Logic | Only distinguishes user instructions and model outputs, no explicit role labels | Supports multiple role labels (e.g., human, gpt, function_call), enforces odd-even position rules |
| Tool Invocation Support | No native support, requires implicit description through input or instructions | Explicit tool invocation through function_call and observation, supports external API integration |
| Typical Use Cases | - Instruction response (e.g., Alpaca-7B) - Domain-specific Q&A - Structured text generation | - Multi-turn dialogues (e.g., Vicuna) - Customer service systems - Interactions requiring real-time data queries (e.g., weather, calculations) |
| Advantages | - Concise structure, clear task orientation - Suitable for rapid single-turn dataset construction | - Supports complex dialogue flows and external tool extension - Closer to real human-machine interaction scenarios |
| Limitations | - Requires manual history concatenation for multi-turn dialogues- Lacks dynamic tool interaction capabilities | - More complex data format - Requires strict adherence to role position rules |
