> For the complete documentation index, see [llms.txt](https://docs.easy-dataset.com/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://docs.easy-dataset.com/bo-ke/shi-zhan-an-li/an-li-5-cong-tu-wen-ppt-zhong-ti-qu-shu-ju-ji.md).
# 案例5:从图文 PPT 中提取数据集
最后,我们来看一个比较特殊的场景,假如你现有的资料中有大量的图片,使用纯文本的提取方式可能会丢失大量关键信息。这时我们可以选择用纯视觉的提取方式,来构造一份纯本文的数据集。
> 目标场景:现有一份多图的 PPT ,纯本文解析方式可提取的信息太少,希望将此转为 QA 数据集
我们以:《2025年AI+教育发展洞察报告》这个文件为例:

在导入图片时,我们选择从 PDF 导入:

然后可以看到按照 PDF 页码分隔好的图片:

我们大概 Review 一下,删掉一些章节衔接、二维码这些不必要的图片。
为了保障最终生成的数据集能够独立作为文本数据集进行训练,我们需要稍微对默认的图像问题生成提示词作一些调整,我们来到 项目设置 - 提示词设置 ,找到图像问题生成的提示词:

然后在最后加上这么两句话:
* 生成的问题在脱离图片时,也能作为独立的提问,不要对图提问,应该是对图里的知识提问
* 生成的问题应该是自然的知识类提问,在问题中不得包含如:这份材料、这张图片、这份图表、这张幻灯片、这份PPT、右侧文字、图中文字、这个案例、这份材料这样的字眼。
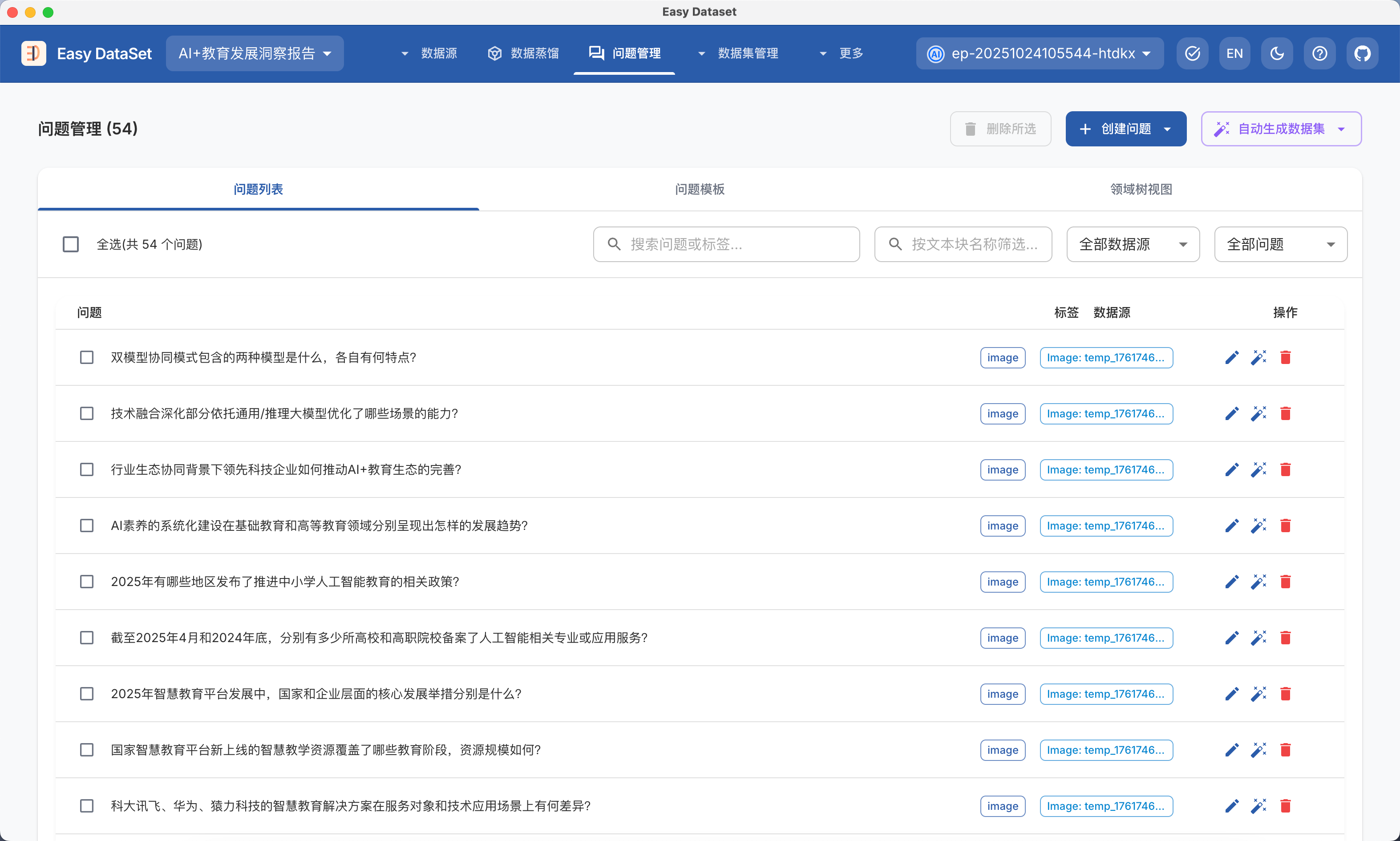
接下来我们回到图片管理,选择自动提取问题:

来到问题管理,我们可以看到已经生成的问题非常自然,大部分都是单纯的知识类提问,和图片本身并不会强相关,然后我们点击 - 【自动生成数据集 - 生成图像问答数据集】
\
然后,我们来到图像问答数据集管理模块,可以看到已经生成好的数据集:

在导出数据集时,一定要注意,将【在数据集中包含图片路径】这个配置取消勾选:

然后我们就得到了一份基于视觉模型对图文进行提取的纯文本数据集:

---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter, and the optional `goal` query parameter:
```
GET https://docs.easy-dataset.com/bo-ke/shi-zhan-an-li/an-li-5-cong-tu-wen-ppt-zhong-ti-qu-shu-ju-ji.md?ask=&goal=
```
`ask` is the immediate question: it should be specific, self-contained, and written in natural language.
`goal` is optional and describes the broader end goal you are ultimately trying to accomplish on behalf of the user. GitBook uses it to tailor the answer towards what is most useful for that goal.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.